前言:更多更新文章详见我的个人博客主页【MGodmonkeyの世界】
描述:欢迎来到CERLAB无人机自主框架,这是一个用于自主无人飞行器 (UAV) 的多功能模块化框架。该框架包括不同的组件 (模拟器,感知,映射,规划和控制),以实现自主导航,未知探索和目标检查。
本章为框架中的一个检测模块,用于对静态或动态障碍物进行识别。
论文地址:Paper
代码地址:GitHub
1. 论文解析
Chatpaper
Basic Information:
- Title: Onboard Dynamic-Object Detection and Tracking for Autonomous Robot Navigation With RGB-D Camera (基于RGB-D相机的机载动态物体检测和跟踪用于自主机器人导航)
- Authors: Zhefan Xu, Xiaoyang Zhan, Yumeng Xiu, Christopher Suzuki, Kenji Shimada
- Affiliation: Department of Mechanical Engineering, Carnegie Mellon University, Pittsburgh, PA 15213 USA (美国卡内基梅隆大学机械工程系)
- Keywords: RGB-D perception, vision-based navigation, visual tracking, 3D object detection, collision avoidance
- URLs: Paper, GitHub
论文简要 :
- 本文提出了一种基于RGB-D相机的轻量级3D动态障碍物检测和跟踪方法,用于具有有限计算能力的小型机器人。该方法采用了新颖的集成检测策略,结合多个计算效率高但准确率较低的检测器,实现实时高准确性的障碍物检测。此外,还引入了一种基于特征的数据关联和跟踪方法,利用点云的统计特征来防止匹配错误。实验结果表明,该方法在小型四旋翼飞行器上实现了最低的位置误差和可比较的速度误差,证明了该方法在导航动态环境中能够有效改变机器人的轨迹。
背景信息:
- 论文背景: 在拥挤的室内环境中部署自主机器人通常需要它们具备准确的动态障碍物感知能力。然而,以往在自动驾驶领域的许多研究都是针对3D物体检测问题进行的,使用了来自重型激光雷达传感器的密集点云数据,而这些基于学习的数据处理方法的高计算成本使得这些方法不适用于小型机器人,例如具有小型机载计算机的基于视觉的无人机。因此,需要针对计算能力有限的小型机器人开发一种轻量级的基于RGB-D相机的动态障碍物检测和跟踪方法。
- 过去方案: 以往的方法中,有些采用了单一的检测器,但这些方法在计算效率和准确性之间存在权衡。另一些方法则使用了深度图像进行障碍物检测,但深度相机的范围和视野有限,使得一些方法只能在短距离范围内进行障碍物跟踪。此外,深度相机的噪声也会影响检测算法的准确性和可靠性。
- 论文的Motivation: 针对上述问题,本文提出了一种基于RGB-D相机的轻量级3D动态障碍物检测和跟踪方法。该方法采用了多个计算效率高但准确率较低的检测器的集成策略,实现了实时高准确性的障碍物检测。此外,还引入了一种基于特征的数据关联和跟踪方法,利用点云的统计特征来防止匹配错误。最后,该系统还引入了一个学习模块,用于增强检测范围和动态障碍物识别。通过在小型四旋翼飞行器上的实验验证,该方法在机器人的机载计算机上实现了最低的位置误差和可比较的速度误差,证明了该方法在导航动态环境中能够有效改变机器人的轨迹。
方法:
- a. 理论背景:
- 介绍了在拥挤的室内环境中,自主机器人需要准确的动态障碍物感知的需求,以及使用轻量级3D动态障碍物检测和跟踪方法的技术路线。
- b. 技术路线:
- 提出了基于RGB-D相机的轻量级3D动态障碍物检测和跟踪方法,利用集成检测策略和基于特征的数据关联和跟踪方法实现实时高精度障碍物检测。
结果:
- a. 详细的实验设置:
- 在动态环境中使用两台定制的四轴飞行器进行实验,搭载Intel NUC和NVIDIA Jetson Xavier NX嵌入式计算机,算法在飞行器的嵌入式计算机上实时运行。
- b. 详细的实验结果:
- DODT方法在基准算法中表现出最低的位置误差和第二低的速度误差,集成检测降低了误报率并提高了障碍物位置和速度估计的准确性。学习模块增强了检测范围。实验结果显示算法在Intel NUC和Xavier NX平台上实现了实时性能,YOLO-MAD检测器占用了大部分处理时间。物理实验展示了成功检测和跟踪动态障碍物在机器人导航任务中的应用。
1.1 问题汇总
-
关于图2的系统框架:
- 系统框架包括三个核心模块:检测模块、跟踪模块和识别模块。
- 检测模块由非学习和学习两部分组成,非学习部分利用深度图像和两个非学习检测器进行通用障碍物检测。
- 学习模块使用对齐的RGB-D图像进行直接动态障碍物检测,结果与非学习模块结合。
- 跟踪模块使用精细化的3D边界框来估计障碍物状态。
- 识别模块根据状态和跟踪历史将障碍物分类为静态或动态。
- 系统输出动态障碍物边界框,并在静态地图中清除动态障碍物区域以进行导航。 Pages: [“a. system overview”, “d. data association and tracking”, “e. dynamic obstacle identification”]
-
关于U-depth检测器和DBSCAN检测器的定义,方法和作用:
-
U-depth检测器:
- 定义:U-depth检测器是一种基于深度图像的方法,用于检测和跟踪动态障碍物。它通过生成U-depth图和V-depth图,结合深度信息来估计障碍物状态,实现对静态障碍物的安全导航。
- 方法:利用深度图像生成U-depth图和V-depth图,通过估计障碍物的速度和维度来检测和跟踪动态障碍物,将其表示为3D椭球体。采用YOLO检测器来有效避开快速和小型动态障碍物,结合图像差异来识别RGB图像中的所有动态点。
- 作用:U-depth检测器的作用在于提高障碍物维度估计的准确性,结合占据地图来导航动态环境,有效避开动态障碍物,从而实现机器人的安全导航。
-
DBSCAN检测器:
- 定义:DBSCAN检测器是一种基于点云的方法,直接利用点云的几何信息来检测3D障碍物。它通过点云聚类方法结合YOLO检测器进行人体检测,提出使用点云特征向量和对象跟踪点来识别正确的对象匹配和估计其状态。
- 方法:采用点云聚类方法结合YOLO检测器进行室内动态障碍物避让,利用点云特征向量和对象跟踪点来识别正确的对象匹配和估计其状态。
- 作用:DBSCAN检测器的作用在于提高障碍物跟踪的稳健性,通过点云信息直接检测3D障碍物,从而实现动态障碍物的避让和安全导航。 Pages: [“d. data association and tracking”, “e. dynamic obstacle identification”, “b. 3d-obstacle detectors”]
- 定义:DBSCAN检测器是一种基于点云的方法,直接利用点云的几何信息来检测3D障碍物。它通过点云聚类方法结合YOLO检测器进行人体检测,提出使用点云特征向量和对象跟踪点来识别正确的对象匹配和估计其状态。
-
2.环境搭建
2.1 CERLAB无人机框架搭建
参考教程:CERLAB 无人机自主框架:环境搭建 | MGodmonkey の世界
2.2 yolo-mad环境安装(可选)
说明:如果用到yolo-mad检测器作为辅助,按照下面的教程搭建yolo-mad环境
- 安装torch
# 这是ubuntu20-torch-cpu版本的,其余系统或者GPU版本的参考官网教程
# 有缓存指令(网络不好的情况下建议有缓存)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
# 无缓存指令
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu --no-cache-dir
参考:Start Locally | PyTorch
问题汇总:
网络超时【urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=‘files.pythonhosted.org’, port=443): Read timed out】:下载过程中经常会遇到timeout的情况,这时候可以通过复制上面的网址,通过各种方法先下载到本地,然后通过
pip3 install ~/torch-2.2.2+cpu-cp38-cp38-linux_x86_64.whl torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu,哪个超时下载哪个到本地安装,或者头铁一直重试,迟早有一次成功的😉
【ERROR: Package ‘networkx’ requires a different Python: 3.8.10 not in ‘>=3.9’】:networkx版本不兼容3.8,需要通过
pip3 install networkx -i https://pypi.tuna.tsinghua.edu.cn/simple手动安装network3.1版本的库

2.3 运行Demo
- 下载rosbag包:【夸克网盘:single-object.bag】【夸克网盘:multi-objects.bag】
- 将python3设置为系统默认python版本:
sudo ln -sf /usr/bin/python3 /usr/local/bin/python - 运行代码
roscore
# 单人运动
rosbag play -l single-object.bag
# 多人运动
rosbag play -l multi-objects.bag
# 运行没有yolo-mad作为辅助的检测器
roslaunch onboard_detector run_detector.launch
# 运行yolo-mad作为辅助(感觉效果比上面的还差)
roslaunch onboard_detector detector_with_learning_module.launch
2.4 在自己设备上运行(待补充更新)
请调整你的摄像头设备下的配置文件,位于
cfg/detector_param.yaml。同时,修改scripts/yolo_detector/yolo_detector.py中的彩色图像话题名称。从参数文件中,你可以看到算法期望从机器人获取以下数据:
深度图像:
/camera/depth/image_rect_raw机器人姿态:
/mavros/local_position/pose机器人里程计(可选):
/mavros/local_position/odom彩色图像(如果应用了YOLO则为可选):
/camera/color/image_rect_raw对齐深度图像(可选):
/camera/aligned_depth_to_color/image_raw
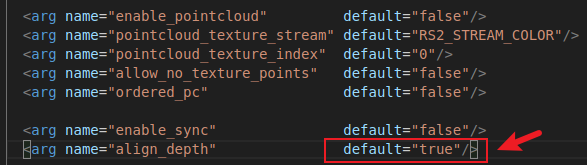
- 修改深度相机launch文件
对齐深度图像默认不生成,因此需要修改launch文件继续修改
roscd realsense2_camera/launch nano rs_camera.launch将
align_depth参数修改为true,然后Ctrl+O&Ctrl+X保存退出