目录
一、urllib网络库
1.urlopen()方法
2.request方法
二、requests网络请求库
1.主要方法
2.requests.get()和requests.post()
一、urllib网络库
1.urlopen()方法
语法格式:
urlopen(url,data,timeout,cafile,capath,context)
# url:地址
# data:要提交的数据
# timeout:设置请求超时时间,超时就舍弃或者重新尝试
# cafile和capath:代表CA证书和CA证书的路径,如果使用https需要用到
# context:指定SSL设置,必须是ssl.SSLContext类型
案例:请求一个简单的网页源代码
import urllib.request
url="https://www.baidu.com/"
responds=urllib.request.urlopen(url)
# 返回一个结果
html=responds.read()
# 运用结果的read方法即可获取源码
print(html.decode('utf-8'))
# decode解码为utf-8,防止乱码结果:
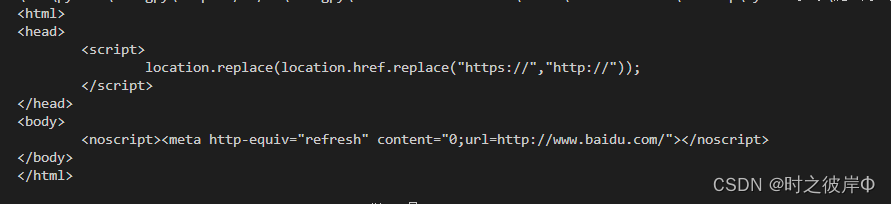
但发现和我们通过f12获取的源码有所不同,原因是网站对headers内的User-Agent信息进行了验证,识别出是程序在访问(默认的User-Agent是python-urllib/版本号),所以对其进行了拦截。此时我们就需要对header进行伪装,伪装成浏览器上的header信息。
案例:设置请求超时
设置timeout参数的值即可。
import urllib.request
url="https://www.baidu.com/"
responds=urllib.request.urlopen(url,timeout='3')
# 返回一个结果
html=responds.read()
# 运用结果的read方法即可获取源码
print(html.decode('utf-8'))
# decode解码为utf-8,防止乱码案例:使用data参数提交数据
data是bytes字节流。
import urllib.request
url="https://httpbin.org/post"
# url后加post为POST方法
data=bytes(urllib.parse.urlencode({'word':'22222'}),encoding='utf-8')
# urllib.parse.urlencode这个方法在构建GET请求时非常有用,可以将参数编码为URL编码格式,方便附加到URL后面。
responds=urllib.request.urlopen(url,data=data)
# 返回一个结果
html=responds.read()
# 运用结果的read方法即可获取源码
print(html.decode('utf-8'))
# decode解码为utf-8,防止乱码2.request方法
语法格式:
urllib.request.Request(url,data,headers={},origin_req_host,unverifiable,method)
# url:请求url
# data:上传数据
# headers:指定发起的HTTP请求的头部信息,此为字典,还可以add_header()添加
# origin_req_host:请求方的host或ip地址
# unverifiable:设置请求是否有权限,true为有,false为无.
# method:发起HTTP请求方式,有GET,POST,DELETE,PUT等
案例:伪装headers
常见的User-Agent示例:
Chrome:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3Firefox:
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:53.0) Gecko/20100101 Firefox/53.0
import urllib.request
url="https://www.baidu.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
request=urllib.request.Request(url=url,headers=headers)
# 获得一个request对象
responds=urllib.request.urlopen(request)
# 使用对象返回一个结果
html=responds.read()
# 运用结果的read方法即可获取源码
print(html.decode('utf-8'))
# decode解码为utf-8,防止乱码案例:通过data提交数据
import urllib.request
url="https://www.baidu.com/"
# url后加post为POST方法
data=bytes(urllib.parse.urlencode({'word':'22222'}),encoding='utf-8')
# urllib.parse.urlencode这个方法在构建GET请求时非常有用,可以将参数编码为URL编码格式,方便附加到URL后面。
request=urllib.request.Request(url=url,data=data,method='POST')
responds=urllib.request.urlopen(request)
# 返回一个结果
html=responds.read()
# 运用结果的read方法即可获取源码
print(html.decode('utf-8'))
# decode解码为utf-8,防止乱码二、requests网络请求库
1.主要方法
常用方法:requests.get()和requests.post()方法。
| 方法 | 解释 |
| requests.request() | 构造一个请求,支持下面各种方法 |
| requests.get() | 获取HTML的主要方法 |
| requests.head() | 获取HTML头部信息的主要方法 |
| requests.post() | 提交POST请求 |
| requests.put() | 提交PUT请求 |
| requests.patch() | 提交局部修改方法 |
| requests.delete() | 提交删除请求 |
2.requests.get()和requests.post()
语法格式:
res = resquests.get(url,**kwargs)或res = resquests.post(url,**kwargs)
# url:请求url。
# **kwargs:其为以下参数可选。
| 参数名称 | 描述 |
| params | 字典或字节序列,作为参数添加到URL中,使用这个参数可以方便的向服务器传参。 例:params = {'keyword': 'python', 'page': '1'} 则发送请求的URL为(数值插入为?部分)https://www.example.com/search?keyword=python&page=1w |
| data | 字典、字节序列或文件对象,向服务器提交资源或数据时候使用,与params区别是data提交的数据放在URL链接所指向的对应地方进行存储,而不放在URL链接里。一般在post方法里使用。 |
| json | json格式数据,它作为内容部分向服务器提交。 |
| headers | 字典类型数据,设置发起HTTP请求的头字段。 |
| cookies | 字典或CookieJar,指的是从HTTP中解析Cookie。 |
| auth | 元组,用来支持HTTP认证功能。 |
| files | 字典,传输文件时候使用。 例:fs={'files':open('data.txt','rb'} |
| timeout | 设置超时时间。 |
| proxies | 字典,用来设置访问代理服务器。 |
| allow_redirects | 开关,设置是否允许库自动处理重定向,默认为true,允许返回响应结果,不允许则返回含重定向信息的响应对象。 |
| stream | 开关,指是否对获取内容进行立即下载,默认为true。 |
| verify | 开关,用于认证SSL证书,默认为True。 |
| cert | 用于设置保存本地SSL证书路径。 |
请求发起后,会返回包含服务器资源的response对象,其包含了以下内容。
| 属性 | 说明 |
| status_code | 返回HTTP请求的状态码,若为200表示请求成功。 |
| text | HTTP响应内容的字符串形式,即返回页面内容。 |
| encoding | 从HTTP Header中猜测响应内容编码方式。 |
| apparent_encoding | 从内容中分析出的响应内容编码方式 |
| content | HTTP响应内容的二进制形式。 |
案例:简单请求
import requestsheader={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
res=requests.get("http://www.baidu.com",headers=header)
print(res.status_code)
print(res.encoding)
print(res.apparent_encoding)
print(res.text)运行结果:

案例:data传递参数
这里表单文本输入框的id为text,data相当于设定了表单值。
import requestsheader={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
data={"text":"hello"
}
res=requests.post("http://8.134.81.188:8080/music/servlet.jsp",headers=header,data=data)
print(res.text)
运行结果:
返回响应体内容。
去后台可以发现写入成功。

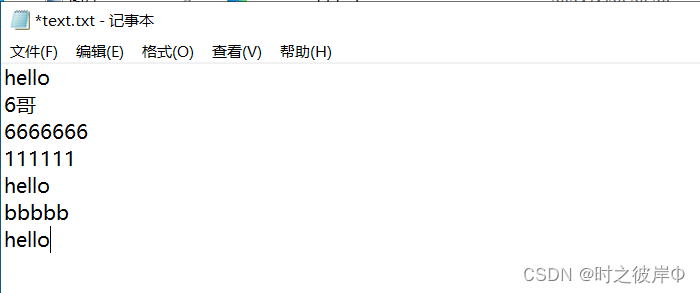
案例:URL传数据
该方法相当于在浏览器地址栏输入以下内容。
http://8.134.81.188:8080/music/servlet.jsp?text=hello
import requestsheader={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
params={"text":"hello"
}
res=requests.get("http://8.134.81.188:8080/music/servlet.jsp",headers=header,params=params)
print(res.text)
运行结果与前一个相同。