引言
在本文[1],我们将介绍Awk的更多特性,特别是两个特殊的模式:BEGIN和END。

这些独特的功能在我们努力扩展和深入探索构建复杂Awk操作的多种方法时,将大有裨益。
实例
让我们从Awk系列的开篇回顾开始,回想一下,当我们启动这个系列时,我提到了运行Awk命令的通用语法是这样的:
# awk 'script' filenames
在上面的语法中,Awk 脚本的形式如下:
/pattern/ { actions }
在编写脚本时,你可能会用到模式,这通常是正则表达式。同时,你也可以将模式理解为特殊的BEGIN和END模式。基于此,我们可以按照以下形式来编写Awk命令:
awk '
BEGIN { actions }
/pattern/ { actions }
/pattern/ { actions }
……….
END { actions }
' filenames
在Awk脚本中,如果用到了BEGIN和END这两个特殊模式,它们各自代表的含义如下:
BEGIN模式:指的是在读取任何输入行之前,Awk会先执行BEGIN下指定的所有操作一次。 END模式:指的是在Awk程序退出之前,会执行END下指定的所有操作。 含有这些特殊模式的Awk命令脚本的执行顺序大致如下:
当脚本执行到BEGIN模式时,BEGIN下的所有操作会被执行一遍,这发生在读取任何输入行之前。 接着,Awk会读取一行输入并将其分解成不同的字段。 然后,Awk会将指定的非特殊模式与输入行逐一进行匹配,一旦匹配成功,就会执行该模式下的所有操作。这个过程会针对所有已指定的模式重复进行。 对于所有输入行,第二和第三步会重复执行。 处理完所有输入行后,如果脚本中有END模式,那么Awk将执行END下的操作。 在使用特殊模式进行Awk操作时,你应该始终牢记这个执行顺序,以期获得最佳操作效果。
以domains.txt文件中的Tecmint所拥有的域名列表为例:
news.tecmint.com
tecmint.com
linuxsay.com
windows.tecmint.com
tecmint.com
news.tecmint.com
tecmint.com
linuxsay.com
tecmint.com
news.tecmint.com
tecmint.com
linuxsay.com
windows.tecmint.com
tecmint.com
$ cat ~/domains.txt
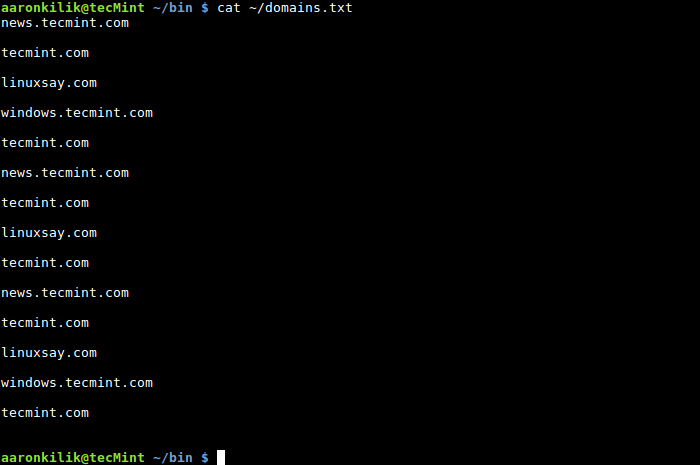
以这个示例为例,我们的目标是统计域名 "tecmint.com" 在文件 "domains.txt" 中出现的次数。为此,我们编写了一个简短的 shell 脚本,利用了变量、数值表达式和赋值运算符的相关知识,脚本的具体内容如下:
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
#print out filename
echo "File is: $file"
#print a number incrementally for every line containing tecmint.com
awk '/^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; }' $file
else
#print error info incase input is not a file
echo "$file is not a file, please specify a file." >&2 && exit 1
fi
done
#terminate script with exit code 0 in case of successful execution
exit 0
接下来,我们将在上述脚本中的Awk命令里应用BEGIN和END这两个特殊模式,具体如下:
我们会对脚本做出如下修改:
awk '/^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; }' $file
>
awk ' BEGIN { print "The number of times tecmint.com appears in the file is:" ; }
/^tecmint.com/ { counter+=1 ; }
END { printf "%s\n", counter ; }
' $file
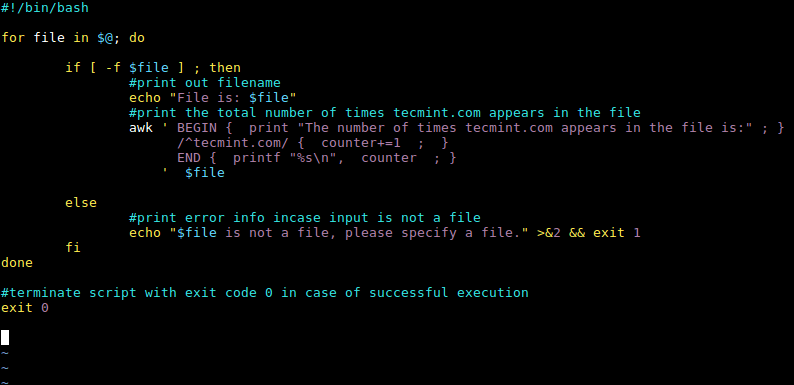
修改Awk命令后,整个shell脚本现在变成了如下形式:
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
#print out filename
echo "File is: $file"
#print the total number of times tecmint.com appears in the file
awk ' BEGIN { print "The number of times tecmint.com appears in the file is:" ; }
/^tecmint.com/ { counter+=1 ; }
END { printf "%s\n", counter ; }
' $file
else
#print error info incase input is not a file
echo "$file is not a file, please specify a file." >&2 && exit 1
fi
done
#terminate script with exit code 0 in case of successful execution
exit 0
执行上述脚本时,它会首先显示文件 "domains.txt" 的位置,随后执行Awk命令脚本。在读取文件中的任何输入行之前,BEGIN特殊模式会先帮助我们输出信息:“域名tecmint.com在文件中出现的次数为:”。
接下来,我们的正则表达式模式 /^tecmint.com/ 将与每一行输入行进行匹配,对于匹配的每一行,将执行操作 { counter+=1 ; },这个操作用于统计域名 "tecmint.com" 在文件中出现的次数。
最终,END模式将输出域名 "tecmint.com" 在文件中出现的总次数。
$ ./script.sh ~/domains.txt

总结来说,我们通过研究BEGIN和END这两个特殊模式的概念,进一步探索了Awk的更多功能。正如我之前提到的,这些Awk的功能将助力我们构建更为复杂的文本过滤操作。
Source: https://www.tecmint.com/learn-use-awk-special-patterns-begin-and-end/
本文由 mdnice 多平台发布