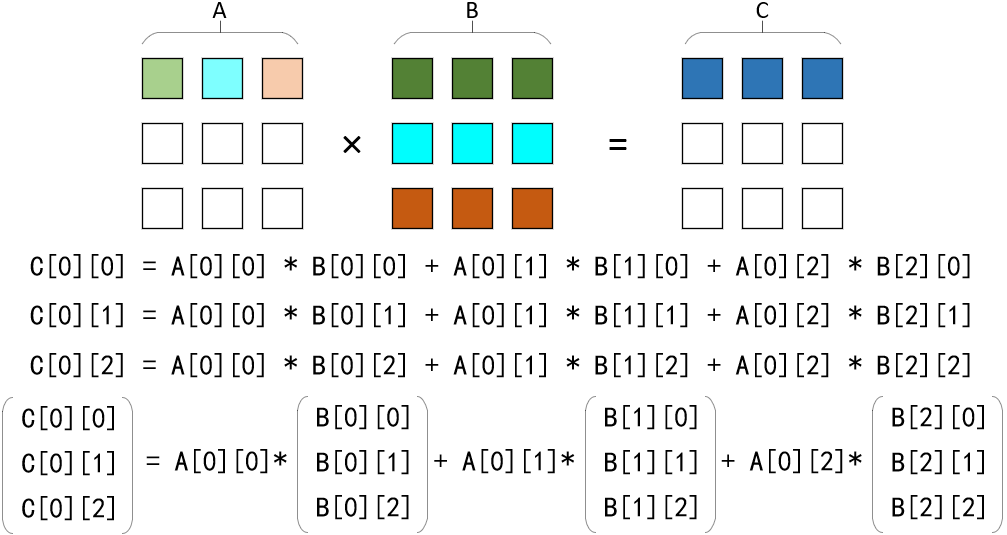
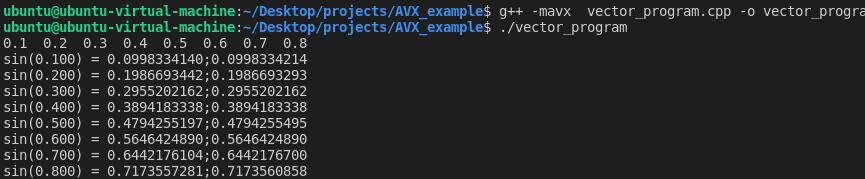
#include "xmmintrin.h"
#include "windows.h"
#include "math.h"
#include "iostream"
using namespace std;
typedef unsigned long uL;void MultiplyWithSSE(float * a, DWORD len, float scale){ //DWORD means unsigned longDWORD nowlen = len / 4;__m128 new_scale = _mm_set_ps1(nowlen);for(DWORD i = 0; i < nowlen; i++){*(__m128*)(a + i*4) = _mm_mul_ps(*(__m128*)(a + i*4), new_scale);}
}void MultiplyWithoutSSE(float *a, DWORD len, float scale){for(DWORD i = 0; i < len; i++){a[i] *= scale;}
}void AddWithSSE(float *a, DWORD len, float add){DWORD nowlen = len / 4;__m128 new_add = _mm_set_ps1(nowlen);for(DWORD i = 0; i < nowlen; i++){*(__m128*)(a + i*4) = _mm_add_pd(*(__m128*)(a + i*4), new_add);}
}void AddWithoutSSE(float *a, DWORD len, float add){for(DWORD i = 0; i < len; i++){a[i] += add;}
}void SqrtWithSSE(float *a, DWORD len, float scale){DWORD nowlen = len / 4;__m128 new_add = _mm_set_ps1(nowlen);for(DWORD i = 0; i < nowlen; i++){*(__m128*)(a + i*4) = _mm_sqrt_pd(scale);}
}void SqrtWithoutSSE(float *a, DWORD len, float scale){for(DWORD i = 0; i < len; i++){a[i] = sqrt(scale);}
}void MinWithSSE(float *a, DWORD len, float scale){DWORD nowlen = len / 4;__m128 new_min = _mm_set_ps1(nowlen);for(DWORD i = 0; i < nowlen; i++){*(__m128*)(a + i*4) = _mm_min_pd(*(__m128*)(a + i*4), scale);}
}void MinWithoutSSE(float *a, DWORD len, float scale){for(DWORD i = 0; i < len; i++){a[i] = min(a[i], scale);}
}void MaxWithSSE(float *a, DWORD len, float scale){DWORD nowlen = len / 4;__m128 new_max = _mm_set_ps1(nowlen);for(DWORD i = 0; i < nowlen; i++){*(__m128*)(a + i*4) = _mm_max_pd(*(__m128*)(a + i*4), scale);}
}void MaxWithoutSSE(float *a, DWORD len, float scale){for(DWORD i = 0; i < len; i++){a[i] = max(a[i], scale);}
}void Add2WithSSE(float *a, DWORD len, float scale){DWORD nowlen = len / 4;__m128 new_and = _mm_set_ps1(nowlen);for(DWORD i = 0; i < nowlen; i++){*(__m128*)(a + i*4) = _mm_add_ps(*(__m128*)(a + i*4), scale);}
}void Add2WithoutSSE(float *a, DWORD len, float scale){for(DWORD i = 0; i < len; i++){a[i] = (int) a[i] & (int) scale;}
}int main(){
}
#include "avxintrin.h"
#include "windows.h"
#include "math.h"
#include "time.h"
#include "iostream"
using namespace std;
typedef unsigned long uL;//cal PI
double calPI(size_t dt){double pi = 0;double delta = 1.0 / delta;for(size_t i = 0; i < dt; i++){double x = (double) i / dt;pi += delta / (1.0 + x * x);}return pi * 4.0;
}//cal PI with AVX
double calPIWithAVX(size_t dt){double pi = 0;double delta = 1.0 / dt;__m256d ymm0, ymm1, ymm2, ymm3, ymm4;ymm0 = _mm256_set1_pd(1.0); //赋值ymm1 = _mm256_set1_pd(delta);ymm2 = _mm256_set_pd(delta*3, delta*2, delta, 0.0);ymm4 = _mm256_setzero_pd();for(int i = 0; i <= dt-4; i+=4){ymm3 = _mm256_set1_pd(i * delta);ymm3 = _mm256_add_pd(ymm3, ymm2);ymm3 = _mm256_mul_pd(ymm3, ymm3);ymm3 = _mm256_add_pd(ymm0, ymm3);ymm3 = _mm256_div_pd(ymm1, ymm3);ymm4 = _mm256_add_pd(ymm4, ymm3);}double tmp[4] __attribute__((aligned(32))); //_attribute__((aligned(n)))// 此属性指定了指定类型的变量的最小对齐(以字节为单位)。// 如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。_mm256_store_pd(tmp, ymm4); //对齐存储pi += tmp[0] + tmp[1] + tmp[2] + tmp[3];return pi * 4.0;
}//cal PI with AVX and LOOP EXPANSION
double calPIWITHAVX2(size_t dt){double pi = 0;double delta = 1.0 / dt;__m256d ymm0, ymm1, ymm2, ymm3, ymm4, ymm5, ymm6, temp;ymm0 = _mm256_set1_pd(1.0);ymm1 = _mm256_set1_pd(delta);ymm2 = _mm256_set_pd(delta*3, delta*2, delta, 0.0);temp = _mm256_set_pd(delta*7, delta*6, delta*5, delta*4);ymm4 = _mm256_setzero_pd();ymm5 = _mm256_setzero_pd();for(int i = 0; i <= dt - 8; i += 8){ymm3 = _mm256_set1_pd(i * delta);ymm3 = _mm256_add_pd(ymm3, ymm2);ymm3 = _mm256_mul_pd(ymm3, ymm3);ymm3 = _mm256_add_pd(ymm0, ymm3);ymm3 = _mm256_div_pd(ymm1, ymm3);ymm4 = _mm256_add_pd(ymm4, ymm3);ymm6 = _mm256_set1_pd((i+4) * delta);ymm6 = _mm256_mul_pd(ymm6, temp);ymm6 = _mm256_add_pd(ymm0, ymm6);ymm6 = _mm256_div_pd(ymm1, ymm6);ymm5 = _mm256_add_pd(ymm5, ymm6);}ymm4 = _mm256_add_pd(ymm4, ymm5);double tmp[4] __attribute__((aligned(32))); //_attribute__((aligned(n)))// 此属性指定了指定类型的变量的最小对齐(以字节为单位)。// 如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。_mm256_store_pd(tmp, ymm4); //对齐存储pi += tmp[0] + tmp[1] + tmp[2] + tmp[3];return pi * 4.0;
}int main(){clock_t st = clock();calPI(1000000000);clock_t en = clock();double t = (double)(en - st) / CLOCKS_PER_SEC;printf("%.5f\n", t);st = clock();calPIWithAVX(10000000000);en = clock();t = (double)(en - st) / CLOCKS_PER_SEC;printf("%.5f\n", t);st = clock();calPIWITHAVX2(10000000000);en = clock();t = (double)(en - st) / CLOCKS_PER_SEC;printf("%.5f\n", t);return 0;
}