背景:学习使用SIMD AVX指令集,已经完成了一份代码,在Windows中能正常运行,想迁移到Linux中,结果却出现两个问题,最终逐渐排坑至可以正常运行。
环境:windows 10, ubuntu 20.04
目录
- 一、Windows下正常运行代码
- 二、Ubuntu中运行问题一:编译错误
- 三、Ubuntu运行问题二:Segmentation fault (core dumped)
- 四、成功运行结果
- 参考资料
一、Windows下正常运行代码
#include<immintrin.h>
#include<iostream>
#include<cmath>using namespace std;void sinx(int, int, float*, float*);
void print_MM(__m256);int main()
{int N = 8, terms = 3;float x[8] = { 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8 }, result[8];sinx(N, terms, x, result);for (int i = 0; i < N; ++i){printf("sin(%.3f) = %.10f;%.10f\n", x[i], result[i], sin(x[i]));}return 0;
}void sinx(int N, int terms, float* x, float* result)
{float three_fact = 6;for (int i = 0; i < N; i += 8){__m256 origx = _mm256_load_ps(&x[i]);print_MM(origx);__m256 value = origx;__m256 numer = _mm256_mul_ps(origx, _mm256_mul_ps(origx, origx));__m256 denom = _mm256_broadcast_ss(&three_fact);int sign = -1;for (int j = 1; j <= terms; j++){//value += sign * numer / denom__m256 tmp1 = _mm256_div_ps(_mm256_mul_ps(_mm256_set1_ps(sign), numer), denom);value = _mm256_add_ps(value, tmp1);numer = _mm256_mul_ps(numer, _mm256_mul_ps(origx, origx));float tmp2 = (float)((2 * j + 2) * (2 * j + 3));denom = _mm256_mul_ps(denom, _mm256_broadcast_ss(&tmp2));sign *= -1;}_mm256_store_ps(&result[i], value);}// Scalar program/*for (int i = 0; i < N; ++i){float value = x[i];float numer = x[i] * x[i] * x[i];int denom = 6;int sign = -1;for (int j = 1; j <= terms; ++j){value += sign * numer / denom;numer *= x[i] * x[i];denom *= (2 * j + 2) * (2 * j + 3);sign *= -1;}result[i] = value;}*/
}void print_MM(__m256 test)
{float out[8];_mm256_store_ps(&out[0], test);for (int i = 0; i < 8; ++i){cout << out[i] << " ";}cout << endl;
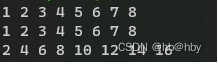
}在VS中创建CPP项目运行即可,其功能为利用泰勒展开近似计算sin(x)值,运行结果如下

二、Ubuntu中运行问题一:编译错误
将这份代码复制到Linux系统利用如下命令编译,出现错误
g++ filename.cpp -o filename

/usr/lib/gcc/x86_64-linux-gnu/9/include/avxintrin.h:878:1: error: inlining failed in call to always_inline ‘void _mm256_store_ps(float*, __m256)’: target specific option mismatch
878 | _mm256_store_ps (float *__P, __m256 __A)
vector_program.cpp:75:17: note: called from here
75 | _mm256_store_ps(out, test);
查阅多方资料/文档/博客,最终找到两个解决方法
方法一:使用编译命令
g++ filename.cpp -march=native -o filename
方法二:使用编译命令
g++ -mavx filename.cpp -o filename
三、Ubuntu运行问题二:Segmentation fault (core dumped)
使用上述编译命令正确编译后,运行无结果

再查阅多方资料/文档/博客,终于发现原因是因为内存不对齐,所使用的_mm256_load_ps()和_mm256_store_ps()等操作要求内存地址以32对齐。而直接定义来的float数组并非如此,可以直接输出变量地址进行验证
最终也找到两个解决方法
方法一:使用不严格对齐操作
_mm256_loadu_ps() 代替 _mm256_load_ps()
_mm256_storeu_ps() 代替_mm256_store_ps()
等等
方法二:定义变量时规定内存对齐
根据编译器的不同而有不同的具体要求,在本例中我使用GCC编译器,因而具体改动如下
__attribute__ ((aligned (32))) float x[8] = { 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8 }, result[8];
__attribute__ ((aligned (32))) float out[8];
在这类数组定义前加上__attribute__ ((aligned (32)))
如果是MSVC编译器,则是__declspec(align(32))
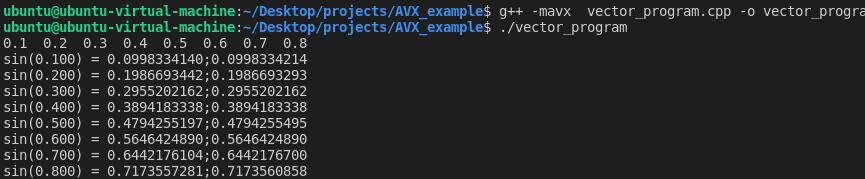
四、成功运行结果
参考资料
AVX segmentation fault on linux – Stack Overflow
SSE/AVX加速时的内存对齐问题
c++ - 使用 AVX vector 警告编译旧版 GCC 代码
github.com/JustasMasiulis/xorstr/issues