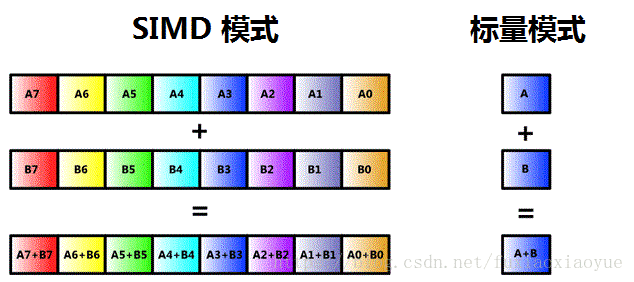
本节矩阵乘选择方阵
思想:c语言默认按行优先存储,矩阵a * b,a的行连续,可以连续访存,大大提高效率;但是b要按列取数,所以去b的列向量浪费时间,解决办法是:将b转置存储,这样b就可以按行进行连续访问。但是要牺牲空间去转存,还浪费了转存的计算时间。但实际仍然有加速效果。
另外还有很多算法可以提升效率。
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#include <x86intrin.h>const int M = 1000;
//串行矩阵乘
void matrix(float **a, float **b, float **c){int i, j, k;for(i = 0; i < M; i++){for(k = 0; k < M; k++){for(j = 0; j < M; j = j+1){c[i][j] += a[i][k] * b[k][j];//c[i][j+1] += a[i][k] * b[k][j+1];//c[i][j+2] += a[i][k] * b[k][j+2];//c[i][j+3] += a[i][k] * b[k][j+3]; }}}
}
//两层循环展开
void matrix_loop_two(float **a, float **b, float **c){int i, j, k;for(i = 0; i < M; i++){for(k = 0; k < M; k++){for(j = 0; j < M; j = j+2){c[i][j] += a[i][k] * b[k][j];c[i][j+1] += a[i][k] * b[k][j+1];//c[i][j+2] += a[i][k] * b[k][j+2];//c[i][j+3] += a[i][k] * b[k][j+3]; }}}
}
//数组赋值
void value(float **a){int i, j, t = 1.0;for(i = 0; i < M; i++){for(j = 0; j < M; j++){a[i][j] = t;}t++;}
}
//打印数组
void print(float **a){int i, j;for(i = 0; i < M; i++){for(j = 0; j < M; j++){printf("%.2f ", a[i][j]);}printf("\n");}printf("***************************************************************\n");
}
//重置数组元素
void reset(float **a){int i, j;for(i = 0; i < M; i++){for(j = 0; j < M; j++){a[i][j] = 0.0;}}
}
//数组转置存储
void rotate(float **b, float **copy_b){int i, j;for(i = 0; i < M; i++){for(j = 0; j < M; j++){copy_b[j][i] = b[i][j];}}
}//avx指令向量乘
void avx_matrix(float **a, float **b, float **c){int i, j, k;float sum = 0.0;float assist = 0.0;//加载a的数组的寄存器,行row加载,连续存储__m256 r0, r1, r2, r3, r4, r5, r6, r7;//加载b数组的寄存器,col加载,转置后列变行,连续存储__m256 c0, c1, c2, c3, c4, c5, c6, c7;__m256 avx_mul0, avx_mul1, avx_mul2, avx_mul3,avx_mul4, avx_mul5, avx_mul6, avx_mul7;__m256 avx_sum0 = _mm256_setzero_ps();__m256 avx_sum1 = _mm256_setzero_ps();__m256 avx_sum2 = _mm256_setzero_ps();__m256 avx_sum3 = _mm256_setzero_ps();__m256 avx_sum4 = _mm256_setzero_ps();__m256 avx_sum5 = _mm256_setzero_ps();__m256 avx_sum6 = _mm256_setzero_ps();__m256 avx_sum7 = _mm256_setzero_ps();__m256 avx_zero = _mm256_setzero_ps();//方阵中每行或每列取64个数据,放到8个寄存器中int copy_M = M - M % 64;//剩余不足64个的数据int reserve = M % 64;for(i = 0; i < M; i++){for(j = 0; j < M; j++){for(k = 0; k < copy_M; k = k + 64){r0 = _mm256_loadu_ps(&a[i][k]);r1 = _mm256_loadu_ps(&a[i][k+8]);r2 = _mm256_loadu_ps(&a[i][k+16]);r3 = _mm256_loadu_ps(&a[i][k+24]);r4 = _mm256_loadu_ps(&a[i][k+32]);r5 = _mm256_loadu_ps(&a[i][k+40]);r6 = _mm256_loadu_ps(&a[i][k+48]);r7 = _mm256_loadu_ps(&a[i][k+56]);c0 = _mm256_loadu_ps(&b[i][k]);c1 = _mm256_loadu_ps(&b[i][k+8]);c2 = _mm256_loadu_ps(&b[i][k+16]);c3 = _mm256_loadu_ps(&b[i][k+24]);c4 = _mm256_loadu_ps(&b[i][k+32]);c5 = _mm256_loadu_ps(&b[i][k+40]);c6 = _mm256_loadu_ps(&b[i][k+48]);c7 = _mm256_loadu_ps(&b[i][k+56]);avx_mul0 = _mm256_mul_ps(r0, c0);avx_mul1 = _mm256_mul_ps(r1, c1);avx_mul2 = _mm256_mul_ps(r2, c2);avx_mul3 = _mm256_mul_ps(r3, c3);avx_mul4 = _mm256_mul_ps(r4, c4);avx_mul5 = _mm256_mul_ps(r5, c5);avx_mul6 = _mm256_mul_ps(r6, c6);avx_mul7 = _mm256_mul_ps(r7, c7);avx_sum0 = _mm256_add_ps(avx_sum0, avx_mul0);avx_sum1 = _mm256_add_ps(avx_sum1, avx_mul1);avx_sum2 = _mm256_add_ps(avx_sum2, avx_mul2);avx_sum3 = _mm256_add_ps(avx_sum3, avx_mul3);avx_sum4 = _mm256_add_ps(avx_sum4, avx_mul4);avx_sum5 = _mm256_add_ps(avx_sum5, avx_mul5);avx_sum6 = _mm256_add_ps(avx_sum6, avx_mul6);avx_sum7 = _mm256_add_ps(avx_sum7, avx_mul7);}//每次向量乘并求和avx_sum0 = _mm256_add_ps(avx_sum0, avx_sum1);avx_sum2 = _mm256_add_ps(avx_sum2, avx_sum3);avx_sum4 = _mm256_add_ps(avx_sum4, avx_sum5);avx_sum6 = _mm256_add_ps(avx_sum6, avx_sum7);avx_sum0 = _mm256_add_ps(avx_sum0, avx_sum2);avx_sum2 = _mm256_add_ps(avx_sum4, avx_sum6);avx_sum0 = _mm256_add_ps(avx_sum0, avx_sum2);//每次求出的c[i][j]avx_sum0 = _mm256_hadd_ps(avx_sum0, avx_zero);avx_sum0 = _mm256_hadd_ps(avx_sum0, avx_zero);assist = avx_sum0[0] + avx_sum0[4];c[i][j] += assist;//寄存器归0avx_sum0 = _mm256_setzero_ps();avx_sum1 = _mm256_setzero_ps();avx_sum2 = _mm256_setzero_ps();avx_sum3 = _mm256_setzero_ps();avx_sum4 = _mm256_setzero_ps();avx_sum5 = _mm256_setzero_ps();avx_sum6 = _mm256_setzero_ps();avx_sum7 = _mm256_setzero_ps();}}//处理第二个矩阵的列向量reserveassist = 0.0;for(i = 0; i < M; i++){for(j = 0; j < M; j = j+1){for(k = 0; k < reserve; k++){assist += a[i][copy_M+k] * b[j][copy_M+k]; }c[i][j] += assist;assist = 0.0;}}
}
int main(){clock_t start, end;int i;//copy_b b的转置存储float **a, **b, **c, **copy_b;a = (float**)malloc(sizeof(float*) * M);b = (float**)malloc(sizeof(float*) * M);c = (float**)malloc(sizeof(float*) * M);copy_b = (float**)malloc(sizeof(float*) * M);a[0] = (float*)malloc(sizeof(float) * M * M);b[0] = (float*)malloc(sizeof(float) * M * M);c[0] = (float*)malloc(sizeof(float) * M * M);copy_b[0] = (float*)malloc(sizeof(float) * M * M);//保证申请的空间连续for(i = 1; i < M; i++){a[i] = a[i-1] + M;b[i] = b[i-1] + M;c[i] = c[i-1] + M;copy_b[i] = copy_b[i-1] + M;}value(a);value(b);reset(c);//normal_mulstart = clock();matrix(a, b, c);end = clock();printf("normal : c[20][9] = %f", c[20][9]);double time = (double)(end - start) / CLOCKS_PER_SEC;printf(" waste time = %f\n", time);//normal_loop_four mulreset(c);start = clock();matrix_loop_two(a, b, c);end = clock();printf("matrix_loop_two : c[20][9] = %f", c[20][9]);time = (double)(end - start) / CLOCKS_PER_SEC;printf(" waste time = %f\n", time);//avx_loop_four mulreset(c);start = clock();rotate(b, copy_b);avx_matrix(a, copy_b, c);end = clock();printf("avx_loop_eight : c[20][9] = %f", c[20][9]);time = (double)(end - start) / CLOCKS_PER_SEC;printf(" waste time = %f\n", time);free(a[0]);free(b[0]);free(c[0]);free(a);free(b);free(c);
}
-
编译器不进行优化时
编译:clang -mavx matrix.c -o matrix
运行:./matrix
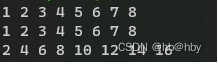
结果:

-
编译器进行-O3优化时:
编译:clang -O3 -mavx matrix.c -o matrix
运行:./matrix
结果:

所以转置花的时间是要小于优化加速的时间的。