超参数调优是机器学习模型调优过程中的重要步骤,它可以帮助我们找到最佳的超参数组合,从而提高模型的性能和泛化能力。在本文中,我们将介绍超参数调优的基本原理和常见的调优方法,并使用Python来实现这些方法。
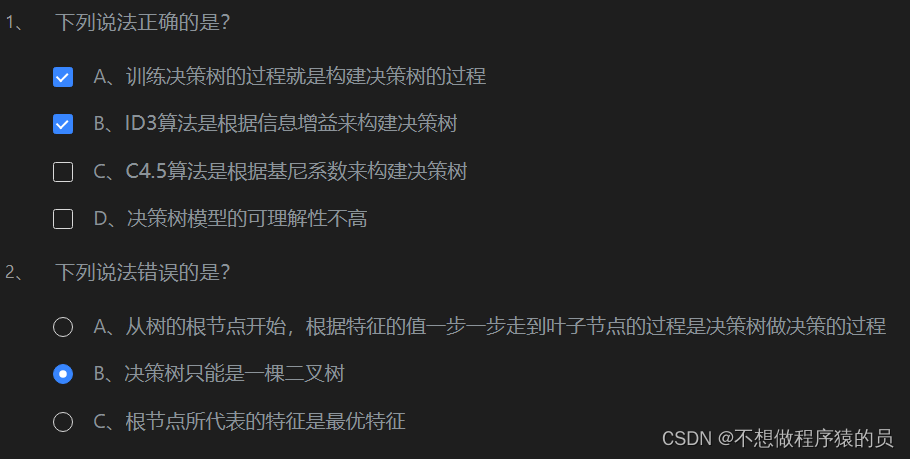
什么是超参数?
超参数是在模型训练之前需要设置的参数,它们不是通过训练数据学习得到的,而是由人工设置的。常见的超参数包括学习率、正则化参数、树的深度等。选择合适的超参数对模型的性能至关重要。
超参数调优方法
1. 网格搜索调优
网格搜索是一种通过遍历所有可能的超参数组合来选择最佳组合的方法。在Python中,我们可以使用GridSearchCV类来实现网格搜索调优:
python">from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris# 准备示例数据集
iris = load_iris()
X, y = iris.data, iris.target# 创建随机森林模型
rf_model = RandomForestClassifier()# 定义超参数搜索空间
param_grid = {'n_estimators': [10, 50, 100],'max_depth': [None, 5, 10, 20]
}# 创建网格搜索调优器
grid_search = GridSearchCV(estimator=rf_model, param_grid=param_grid, cv=5)# 进行网格搜索调优
grid_search.fit(X, y)# 输出最佳超参数组合
print("最佳超参数组合:", grid_search.best_params_)
2. 随机搜索调优
随机搜索调优是一种通过随机抽样超参数空间中的点来选择最佳组合的方法。相比网格搜索,随机搜索更加高效,特别是在超参数空间较大的情况下。在Python中,我们可以使用RandomizedSearchCV类来实现随机搜索调优:
python">from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris# 准备示例数据集
iris = load_iris()
X, y = iris.data, iris.target# 创建随机森林模型
rf_model = RandomForestClassifier()# 定义超参数搜索空间
param_dist = {'n_estimators': randint(10, 100),'max_depth': [None, 5, 10, 20]
}# 创建随机搜索调优器
random_search = RandomizedSearchCV(estimator=rf_model, param_distributions=param_dist, n_iter=10, cv=5)# 进行随机搜索调优
random_search.fit(X, y)# 输出最佳超参数组合
print("最佳超参数组合:", random_search.best_params_)
结论
通过本文的介绍,我们了解了超参数调优的基本原理和常见的调优方法,并使用Python实现了网格搜索调优和随机搜索调优。选择合适的超参数对模型的性能和泛化能力至关重要,因此在机器学习模型调优过程中,我们应该充分利用这些调优方法来提高模型的性能。
希望本文能够帮助读者理解超参数调优的概念和方法,并能够在实际应用中使用Python实现这些方法。