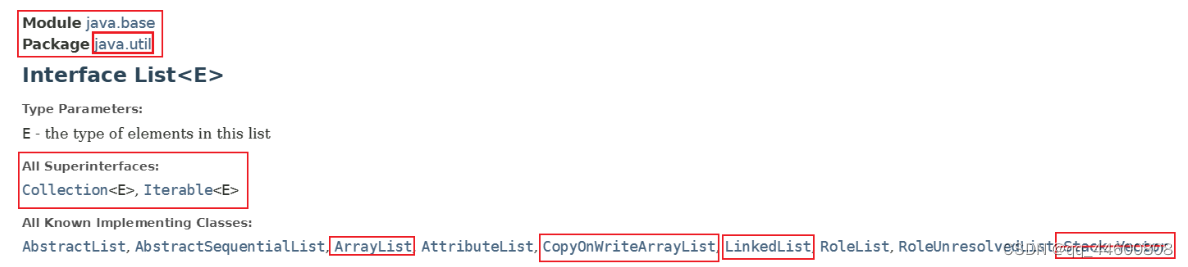
List
- Collection、List接口
- 1、继承结构
- 2、方法
- Collection实现类
- 具体实现类
- 1、Vector
- Stack
- 2、ArrayList
- 3、LinkedList
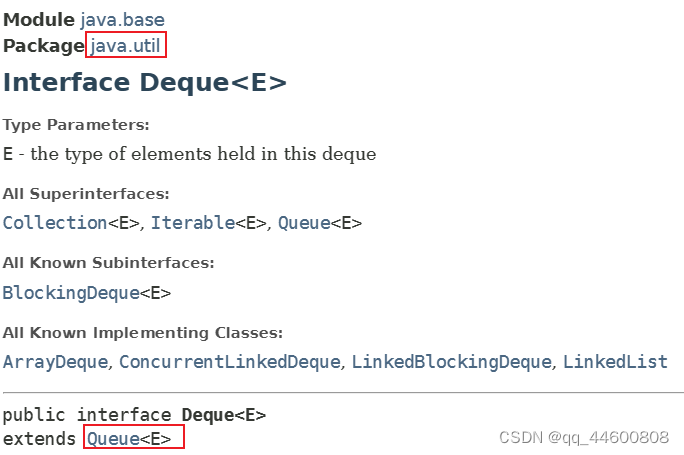
- Deque接口(子接口)
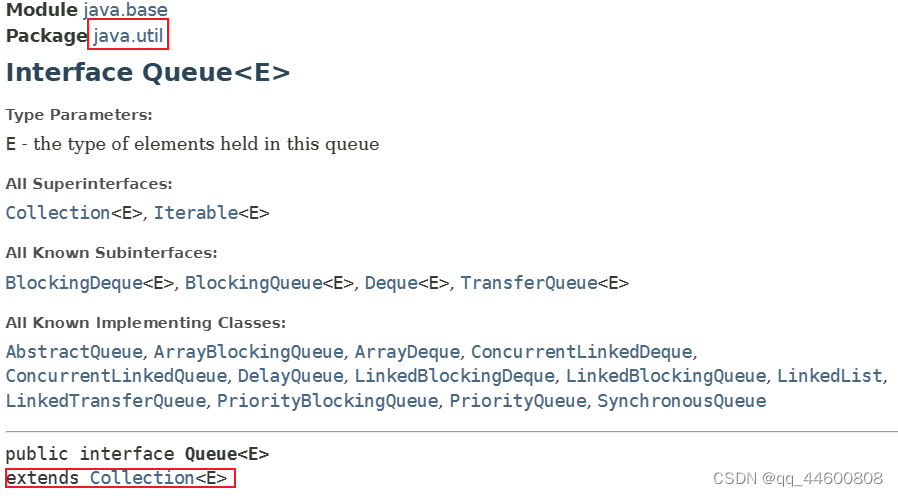
- Queue接口(父接口)
- 源码分析
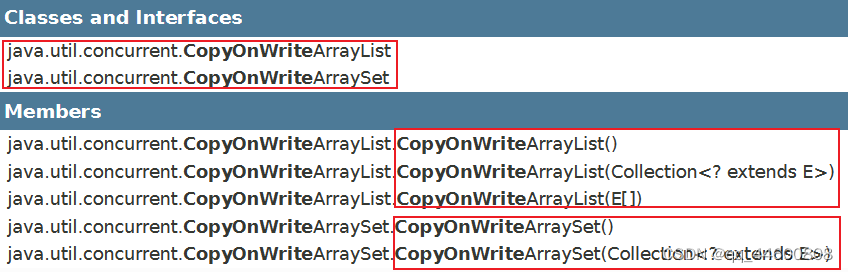
- 4、CopyOnWriteArrayList【COW并发容器,写时复制容器<读写分离>】
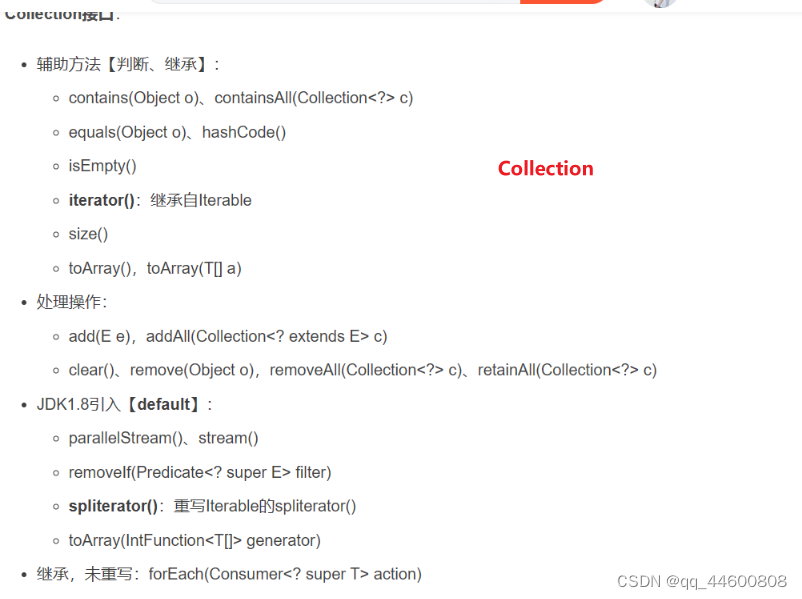
Collection、List接口
1、继承结构

2、方法

Collection实现类
1、继承结构

类图:
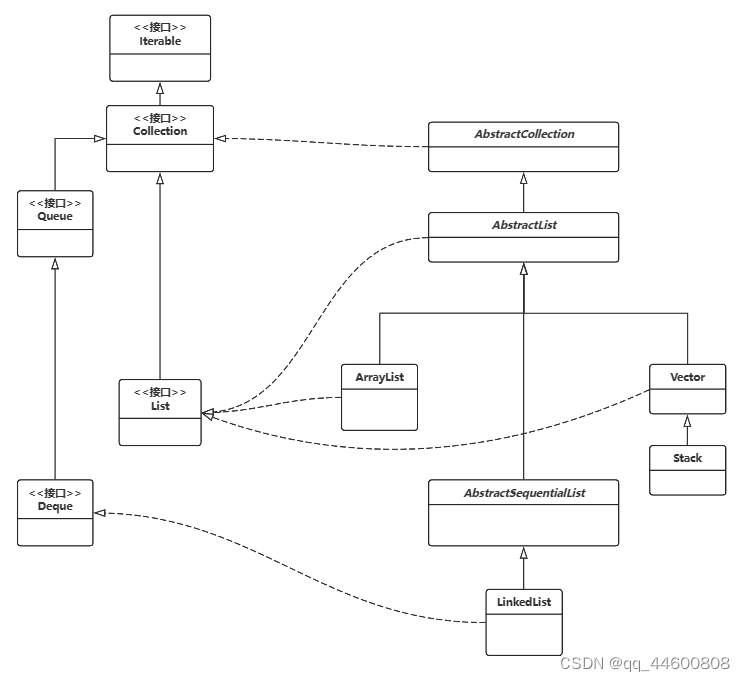
2、相关类
(1)AbstractCollection
Collection接口的骨架式实现类,最小化实现Collection接口的代价。
(2)AbstractList
List接口的骨架式实现类,最小化实现List接口的代价。**“随机访问”**数据存储。
提供了iterator()、listIterator()方法的实现。
重要属性:
protected transient int modCount;【修改次数,迭代器和列表迭代器使用】
如果该字段的值发生意外变化,迭代器(或列表迭代器)将抛出ConcurrentModificationException,以响应next、remove、previous、set、add操作。这提供了快速故障行为,而不是在迭代期间面对并发修改时的不确定性行为。
AbstractSequentialList(子类)
List接口的框架实现,**“顺序访问”**数据存储。
其它接口
javautil_29">RandomAccess【java.util】
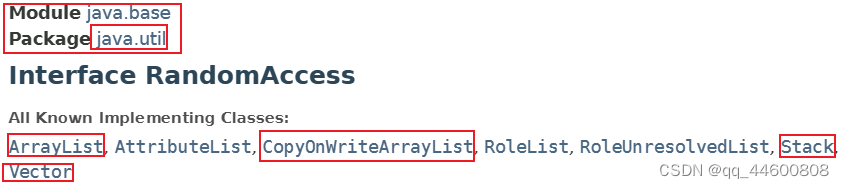
List实现使用的标记接口,表明它们支持快速随机访问(通常是常量时间)。
该接口的主要目的是允许泛型算法改变其行为,以便在应用于随机或顺序访问列表时提供良好的性能。
操作随机访问列表(如ArrayList)的最佳算法在应用于顺序访问列表(如LinkedList)时可以产生二次行为。鼓励泛型列表算法在应用算法之前检查给定列表是否是该接口的实例。
javalang_36">Cloneable【java.lang】
标记接口。
一个类实现了Cloneable接口,表明调用Object.clone()方法对该类的实例进行逐个字段的复制是合法的。在没有实现Cloneable接口的实例上调用Object的clone方法将导致抛出CloneNotSupportedException异常。
按照约定,实现这个接口的类应该重写Object.clone()方法,表明是public,而Object.clone()方法是protected。
这个接口不包含clone方法。因此,不可能仅仅因为对象实现了这个接口就克隆它。即使以反射方式调用clone方法,也不能保证它一定会成功。
javaio_43">Serializable【java.io】
标记接口。Serializable接口没有方法或字段,仅用于标识可序列化的语义。
具体实现类
1、Vector
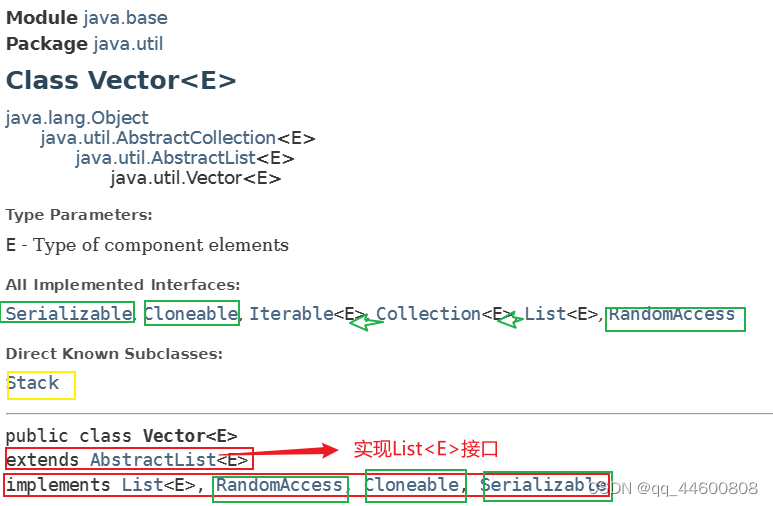

- 可增长的对象数组,使用索引访问:
capacity、capacityIncremnt
Stack
继承自Vector类,扩展Vector类实现LIFO功能:
- push、pop
- peek
- search
- empty
LIFO功能:

2、ArrayList
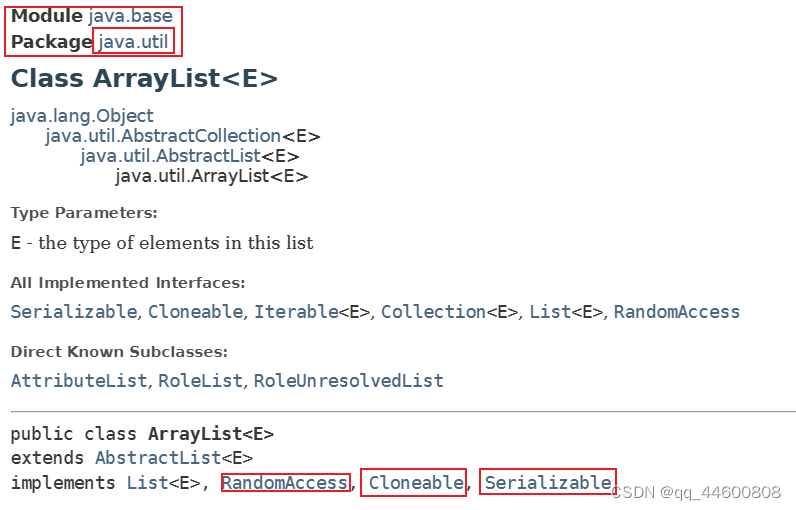
List接口的可调整数组实现。
不同步:
- Collections.synchronizedList(new ArrayList(…));
实现所有可选列表操作,并允许所有元素,包括null。除了实现List接口之外,这个类还提供了一些方法来操作内部用于存储列表的数组的大小。(大致相当于Vector,但不同步。)
-
Cloneable:Object.clone()
-
Iterable:forEach(Consumer<? super E> action)
-
Collection:removeIf(Predicate<? super E> filter)
-
AbstractList:removeRange(int fromIndex, int toIndex)
-
增加方法:
- ensureCapacity(int minCapacity)
- trimToSize()
时间复杂度:
-
size、isEmpty、get、set、iterator和listIterator操作在常量时间内运行。
-
add在平摊常数时间内运行,即添加n个元素需要O(n)时间。
-
所有其他操作都在线性时间内运行(粗略地说)。
与LinkedList实现相比,常数因子较低。
每个ArrayList实例都有一个capacity,用于存储列表中元素的数组的大小。它总是至少和列表大小一样大。当元素被添加到ArrayList中时,它的容量会自动增长。
在添加大量元素之前使用ensureCapacity操作来增加ArrayList实例的容量。这可能会减少增量再分配的数量。
分析源码:
(1)构造函数
java">//存储数据:Object数组elementData//构造函数(空参):赋值空数组
public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}/*构造函数(含参:容器大小):判断initialCapacity > 0:创建对应大小的一个Object数组;= 0 :赋值一个空数组
*/
public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {// 空数组this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);}
}/*构造函数(使用集合Collection的子类对象)
*/
public ArrayList(Collection<? extends E> c) {//将参数转换成数组Object[] a = c.toArray();//数组长度不为0//参数类型判断:ArrayList直接赋值;Arrays.copyOf()方法拷贝if ((size = a.length) != 0) {if (c.getClass() == ArrayList.class) {elementData = a;} else {elementData = Arrays.copyOf(a, size, Object[].class);}} else {//转换的数组长度为0:赋值空数组 elementData = EMPTY_ELEMENTDATA;}
}
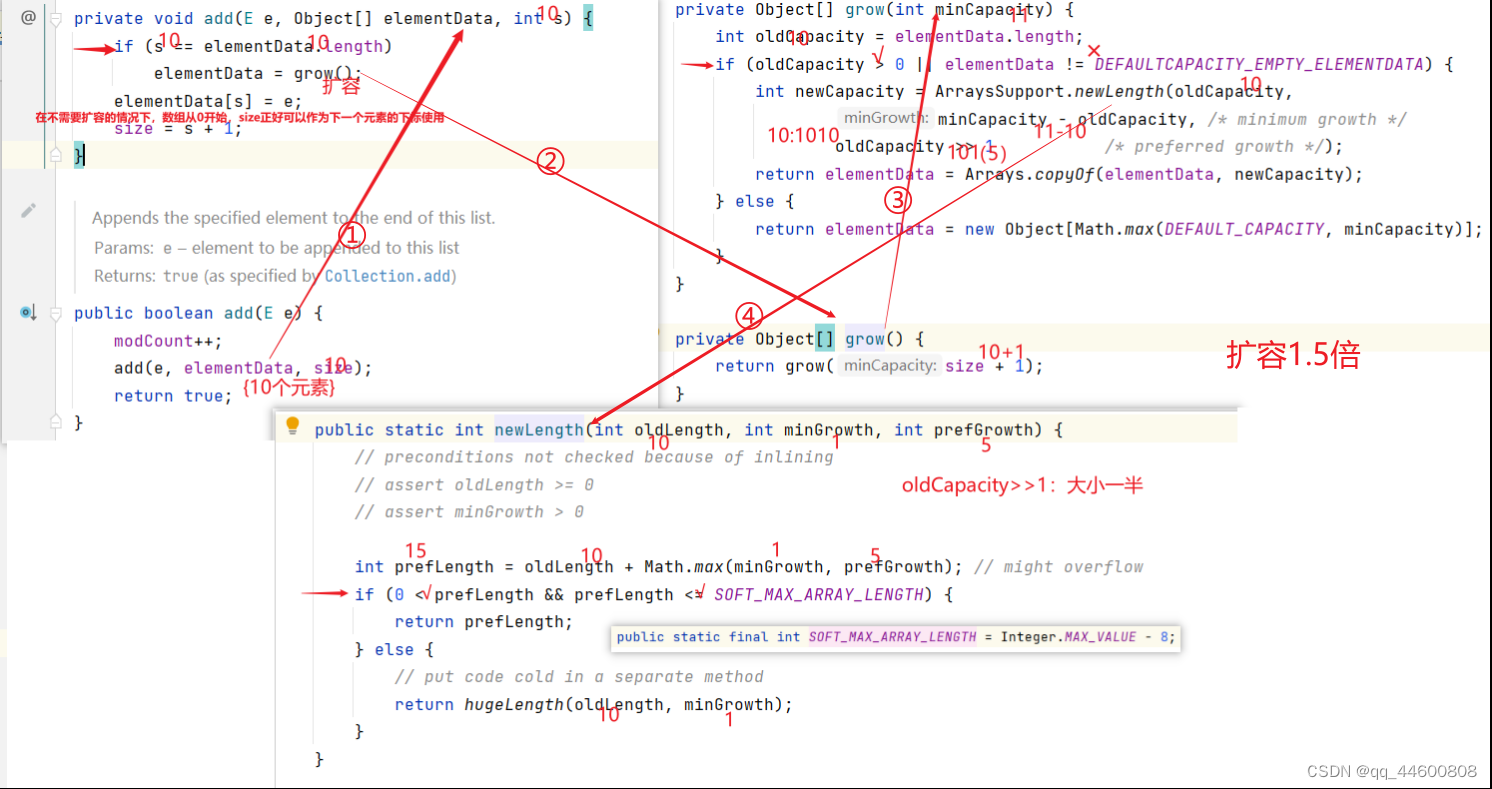
(2)数组大小扩展
java"> // 减少不必要的空间消耗public void trimToSize() {//处理数++modCount++;//容器中元素个数 VS 存储数据数组长度 if (size < elementData.length) {//容器空 ? 空数组 : Arrays.copyOf()elementData = (size == 0)? EMPTY_ELEMENTDATA: Arrays.copyOf(elementData, size);}}public void ensureCapacity(int minCapacity) {//minCapacity>底层数组长度【需要扩容】//!(底层数组不空 && minCapacity<=10)【底层数组空:第一次】if (minCapacity > elementData.length&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA && minCapacity <= DEFAULT_CAPACITY)) {//操作数++modCount++;//增加grow(minCapacity);}}private Object[] grow(int minCapacity) {int oldCapacity = elementData.length;if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity >> 1 /* preferred growth */);return elementData = Arrays.copyOf(elementData, newCapacity);} else {return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];}}private Object[] grow() {return grow(size + 1);}(3)代码
java">ArrayList<String> al = new ArrayList<>();
al.add("hello");
构造函数:创建一个空数组

add()方法:【底层:空数组】=>扩容到长度为DEFAULT_CAPACITY(10)的数组
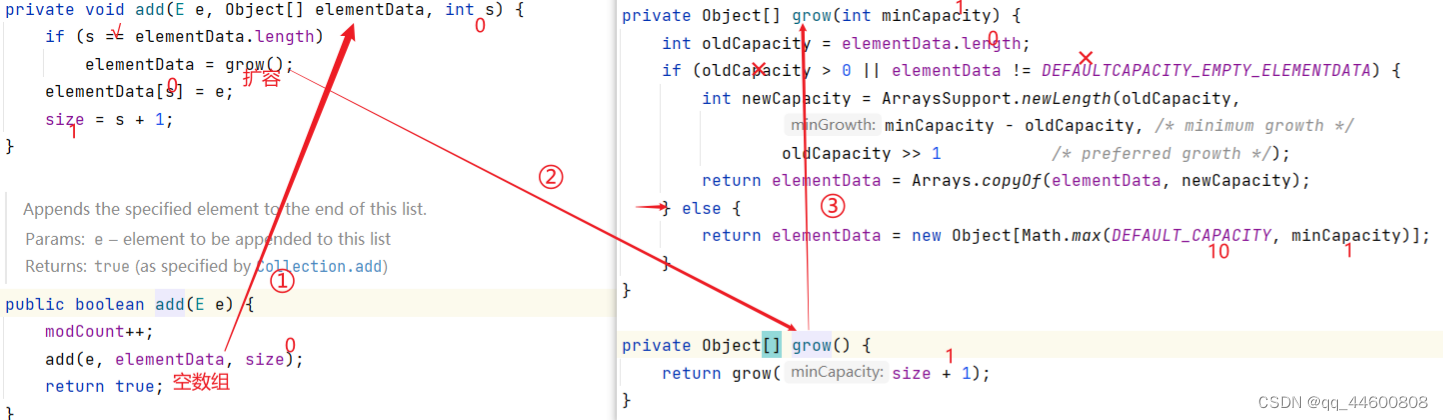
假设当前底层数组中已经添加了10个元素,现在继续调用add()添加一个元素:数组扩容1.5倍
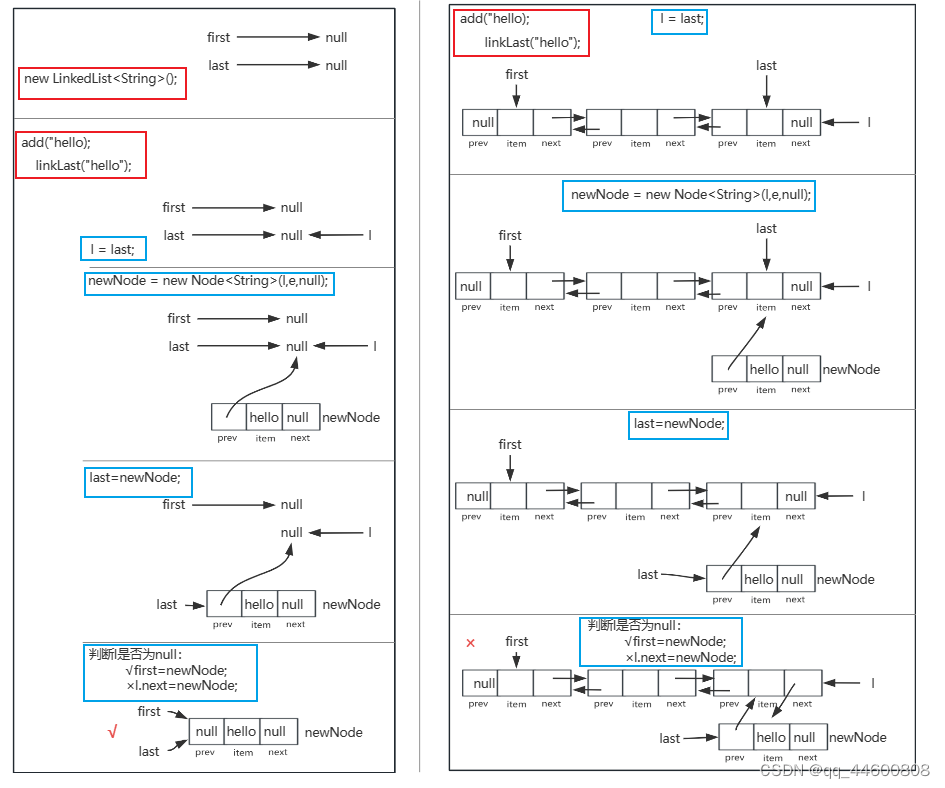
3、LinkedList
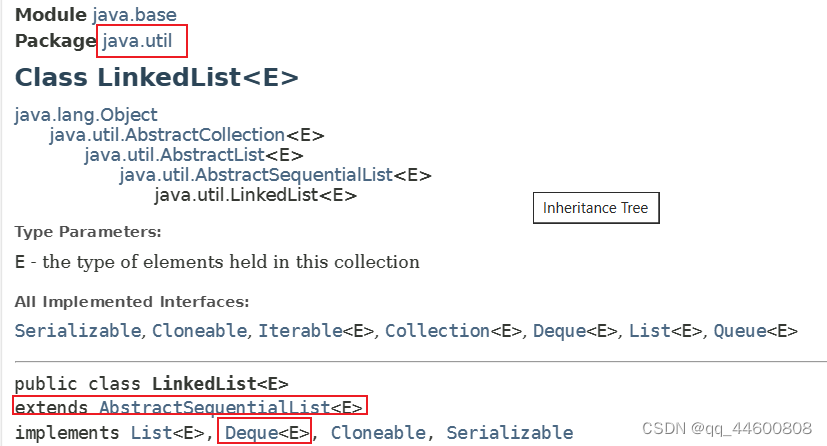
Deque接口(子接口)

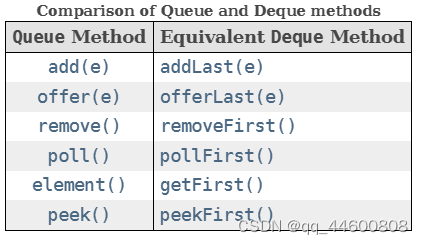

Queue接口(父接口)
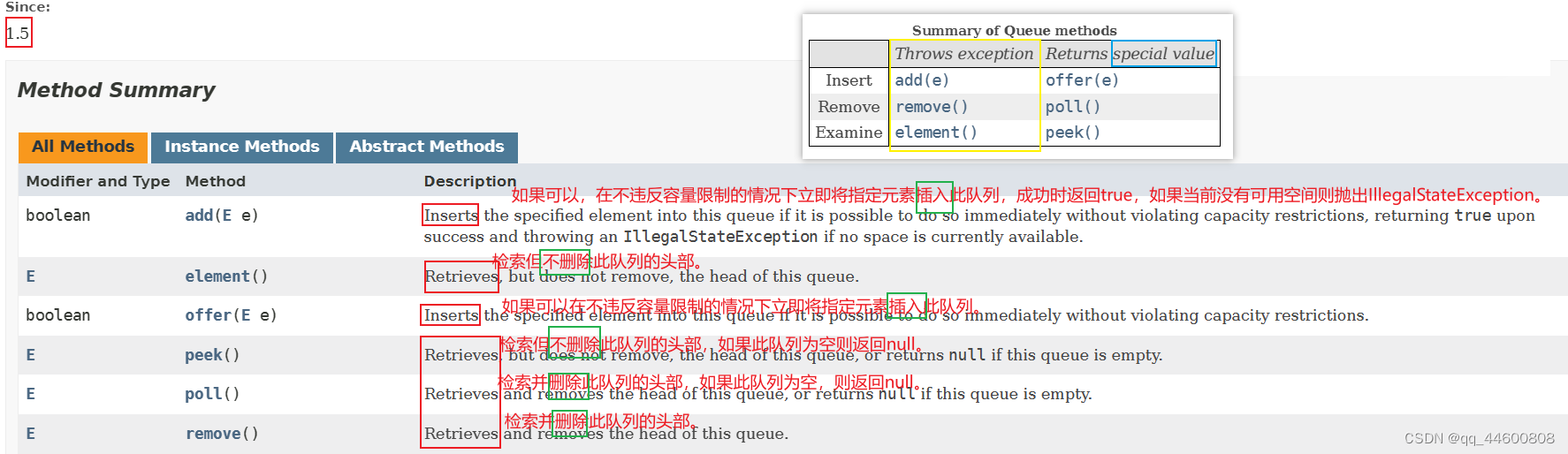
源码分析
(1)双向链表
java"> private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}transient int size = 0;transient Node<E> first;transient Node<E> last;//构造函数public LinkedList() {}
(2)add方法
java"> public boolean add(E e) {linkLast(e);return true;}void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;}
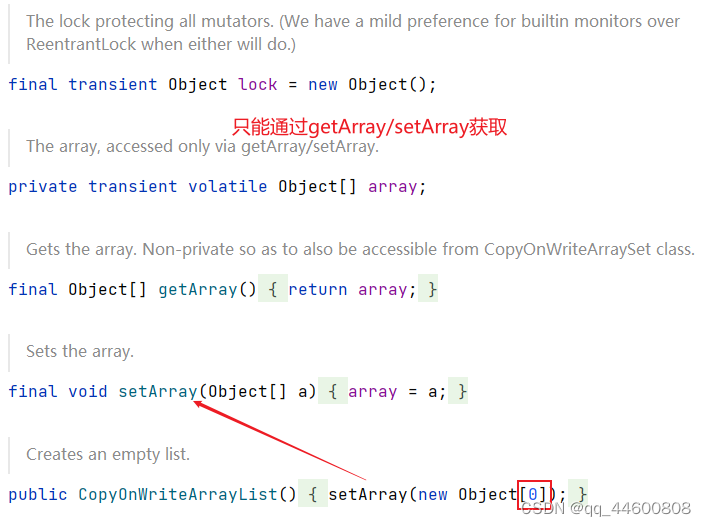
4、CopyOnWriteArrayList【COW并发容器,写时复制容器<读写分离>】
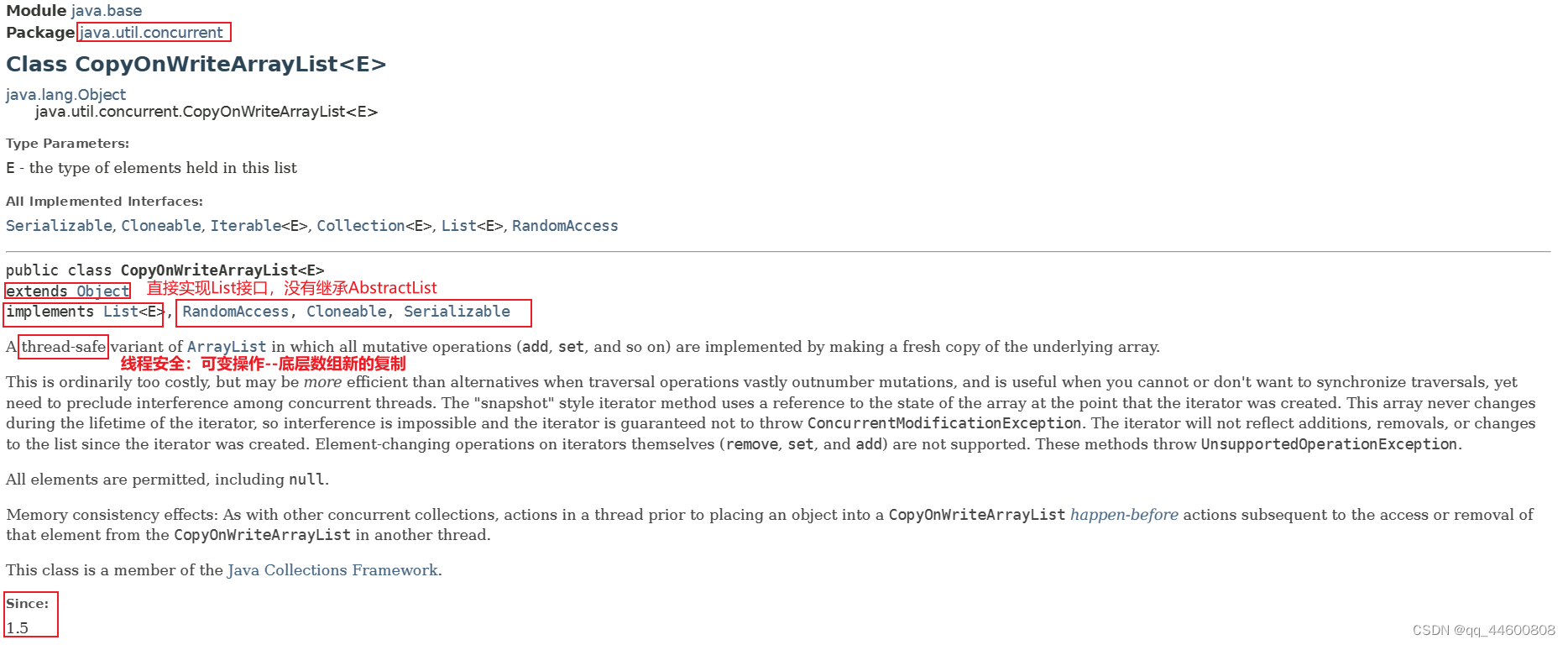
底层:Object数组