探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(十)
Llama 推理
为了对模型进行推理, 需要从Meta的LLaMA 3仓库下载模型的权重。
编写模型推理的代码。在推理模型时,有许多可调参数需要考虑,包括top-k、贪婪搜索/束搜索。为了简单起见,只实现了贪婪搜索。对于束搜索,你可以参考GitHub上LLaMA 3仓库的generation.py文件。
https://github.com/meta-llama/llama3/blob/main/llama/generation.py
以下是您提供的代码段的逐行中文注释:```python
## 推理部分
from typing import Optional # 导入可选类型注解
import torch # 导入PyTorch库
import time # 导入时间库
import json # 导入JSON库
from pathlib import Path # 导入路径库
from sentencepiece import SentencePieceProcessor # 导入句子片段处理器
from tqdm import tqdm # 导入进度条库
from model import ModelArgs, Transformer # 从模型模块导入参数类和Transformer类class LLaMA: # 定义LLaMA类def __init__(self, model: Transformer, tokenizer: SentencePieceProcessor, model_args: ModelArgs):self.model = model # 初始化模型self.tokenizer = tokenizer # 初始化分词器self.args = model_args # 初始化模型参数@staticmethoddef build(checkpoints_dir: str, tokenizer_path: str, load_model: bool, max_seq_len: int, max_batch_size: int, device: str):prev_time = time.time() # 记录当前时间if load_model: # 如果需要加载模型checkpoints = sorted(Path(checkpoints_dir).glob("*.pth")) # 获取所有检查点文件assert len(checkpoints) > 0, "No checkpoints files found" # 确保检查点文件存在chk_path = checkpoints[0] # 获取最新的检查点路径print(f'Loaded checkpoint {chk_path}') # 打印加载的检查点checkpoint = torch.load(chk_path, map_location="cpu") # 加载检查点print(f'Loaded checkpoint in {(time.time() - prev_time):.2f} seconds') # 打印加载时间prev_time = time.time() # 更新当前时间# 加载模型参数with open(Path(checkpoints_dir) / "params.json", "r") as f:params = json.loads(f.read())model_args: ModelArgs = ModelArgs( # 实例化模型参数max_seq_len=max_seq_len,max_batch_size=max_batch_size,device=device,**params # 展开其他参数)tokenizer = SentencePieceProcessor() # 实例化分词器tokenizer.load(tokenizer_path) # 加载分词器模型model_args.vocab_size = tokenizer.vocab_size() # 设置词汇表大小# 根据设备类型设置默认的张量类型if device == "cuda":torch.set_default_tensor_type(torch.cuda.HalfTensor)else:torch.set_default_tensor_type(torch.BFloat16Tensor)model = Transformer(model_args).to(device) # 实例化Transformer模型并指定设备if load_model: # 如果需要加载模型# 从检查点中移除rope.freqs,因为我们是预计算频率del checkpoint["rope.freqs"]model.load_state_dict(checkpoint, strict=False) # 加载模型状态字典print(f"Loaded state dict in {(time.time() - prev_time):.2f} seconds") # 打印加载时间return LLaMA(model, tokenizer, model_args) # 返回LLaMA实例def text_completion(self, prompts: list[str], temperature: float = 0.6, top_p: float = 0.9, max_gen_len: Optional[int] = None):# 如果没有指定最大生成长度,则使用模型参数中的最大序列长度减1if max_gen_len is None:max_gen_len = self.args.max_seq_len - 1# 将每个提示转换为令牌prompt_tokens = [self.tokenizer.encode(prompt, out_type=int, add_bos=True, add_eos=False) for prompt in prompts]# 确保批量大小不是太大batch_size = len(prompt_tokens)assert batch_size <= self.args.max_batch_size, f"Batch size {batch_size} is too large"max_prompt_len = max(len(prompt) for prompt in prompt_tokens)# 确保提示长度不大于最大序列长度assert max_prompt_len < self.args.max_seq_len, f"Prompt length {max_prompt_len} is too large"total_len = min(self.args.max_seq_len, max_gen_len + max_prompt_len)# 创建一个列表,用于包含生成的令牌以及初始提示令牌pad_id = self.tokenizer.pad_id()tokens = torch.full((batch_size, total_len), pad_id, dtype=torch.long, device=self.args.device)for k, t in enumerate(prompt_tokens):tokens[k, :len(t)] = torch.tensor(t, dtype=torch.long, device=self.args.device)eos_reached = torch.tensor([False] * batch_size, device=self.args.device)# 如果令牌是提示令牌,则为True,否则为Falseprompt_tokens_mask = tokens != pad_id for cur_pos in tqdm(range(1, total_len), desc='Generating tokens'):with torch.no_grad(): # 不计算梯度logits = self.model.forward(tokens[:, cur_pos-1:cur_pos], cur_pos)if temperature > 0: # 如果设置了温度参数# 在softmax之前应用温度probs = torch.softmax(logits[:, -1] / temperature, dim=-1)next_token = self._sample_top_p(probs, top_p)else: # 如果温度参数为0,则贪婪选择概率最大的令牌next_token = torch.argmax(logits[:, -1], dim=-1)next_token = next_token.reshape(-1)# 只有在位置是填充令牌时才替换令牌next_token = torch.where(prompt_tokens_mask[:, cur_pos], tokens[:, cur_pos], next_token)tokens[:, cur_pos] = next_token# 如果填充位置找到了EOS令牌,则EOS已到达eos_reached |= (~prompt_tokens_mask[:, cur_pos]) & (next_token == self.tokenizer.eos_id())if all(eos_reached): # 如果所有序列都已到达EOS,则跳出循环breakout_tokens = []out_text = []for prompt_index, current_prompt_tokens in enumerate(tokens.tolist()):# 如果存在EOS令牌,则剪切到EOS令牌if self.tokenizer.eos_id() in current_prompt_tokens:eos_idx = current_prompt_tokens.index(self.tokenizer.eos_id())current_prompt_tokens = current_prompt_tokens[:eos_idx]out_tokens.append(current_prompt_tokens)out_text.append(self.tokenizer.decode(current_prompt_tokens))return (out_tokens, out_text) # 返回生成的令牌和文本def _sample_top_p(self, probs, p):# 对概率进行排序probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)# 计算累积概率probs_sum = torch.cumsum(probs_sort, dim=-1)# 创建一个掩码,当累积概率超过阈值p时为Truemask = probs_sum - probs_sort > pprobs_sort[mask] = 0.0 # 将超过阈值的概率设置为0probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True)) # 重新归一化概率next_token = torch.multinomial(probs_sort, num_samples=1) # 从概率中采样下一个令牌next_token = torch.gather(probs_idx, -1, next_token) # 根据采样的索引获取对应的令牌return next_token # 返回采样的下一个令牌if __name__ == '__main__':import os # 导入操作系统库torch.manual_seed(0) # 设置随机种子以确保结果的可复现性prompts = [ # 定义提示列表# 少量样本提示"""Translate English to kananda:water : ನೀರುland : ಭೂಮಿdusk : ಸಂಜೆdawn : ಬೆಳಗುವಿಕೆmilk : ಹಾಲು""",# 零样本提示"""Tell me if the following person is actually a real person or a fictional character:Name : Vignesh Decision:"""]# 检查CUDA是否可用allow_cuda = True if 'CUDA_VISIBLE_DEVICES' in os.environ else Falsedevice = 'cuda' if torch.cuda.is_available() and allow_cuda else 'cpu' # 根据CUDA的可用性选择设备# 构建LLaMA模型model = LLaMA.build(checkpoints_dir='Meta-Llama-3-8B/',tokenizer_path='Meta-Llama-3-8B/tokenizer.model',load_model=True,max_seq_len=1024,max_batch_size=len(prompts),device=device)print('ALL OK') # 打印模型构建成功的消息# 对模型进行推理print("Inferenceing the model
附录:
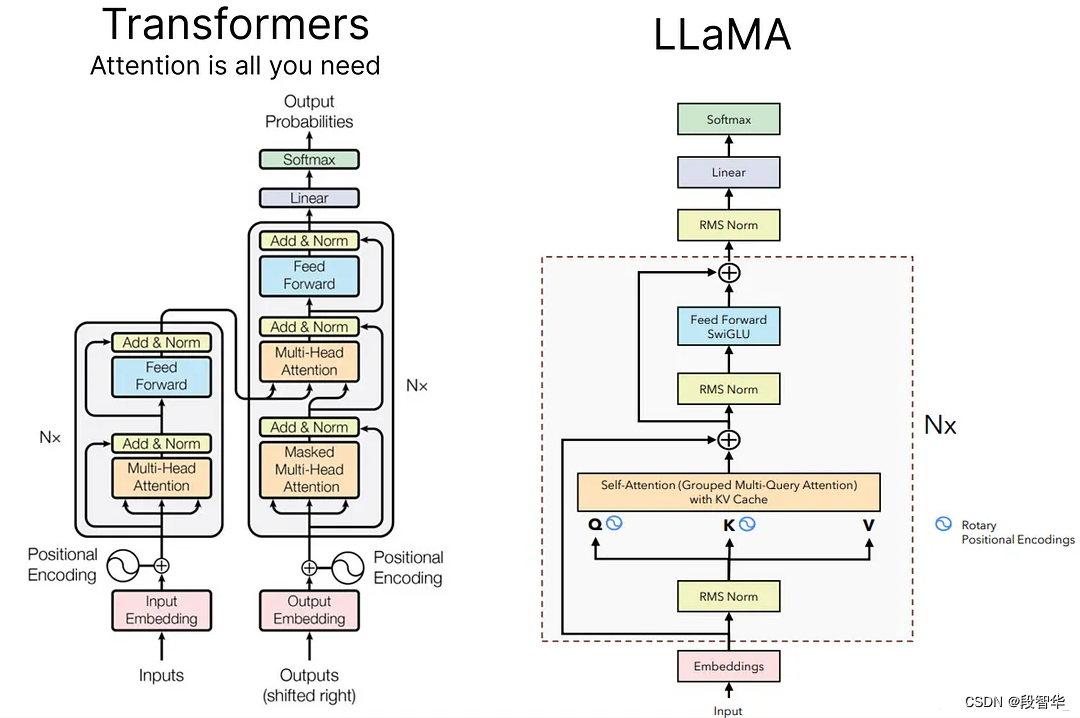
使用 PyTorch 从头开始构建 Llama2 架构:
所有模型都是从头开始构建的,包括 GQA(分组查询注意)、RoPE(旋转位置嵌入)、RMS Norm、前馈块、编码器(因为这仅用于推理模型)、SwiGLU(激活函数)
https://github.com/viai957/llama-inference
## LLaMA - Large Language Model with Attentionimport torch
import torch.nn.functional as F
import math
import torch.nn as nn
from tqdm import tqdm
from dataclasses import dataclass
from typing import Optional@dataclass
class ModelArgs:dim: int = 4096n_layers: int = 32n_heads: int = 32 # Number of heads for the queriesn_kv_heads: Optional[int] = None # Number of heads for the keys and values. If None, defaults to n_headsvocab_size: int = -1 # This will be set when we load the tokenizermultiple_of: int = 256 ffn_dim_multiplier: Optional[float] = None # If None, defaults to 4.0norm_eps: float = 1e-5# Needed for KV cachemax_batch_size: int = 32max_seq_len: int = 2048device: str = Nonedef precomputed_theta_pos_frequencies(head_dim: int, seq_len: int, device: str, theta: float = 10000.0):# As written in the paper, the dimentions o the embedding must be evenassert head_dim % 2 == 0, "The head_dim must be even"# Built the theta parameters# According to the formula theta_i = 10000 ^ (-2(i-1)/dim) for i = [1,2,3,..dim/2]# Shape: (head_dim / 2)theta_numerator = torch.arange(0, head_dim, 2).float()# Shape : (head_dim / 2)theta = 1.0 / (theta ** (theta_numerator / head_dim)).to(device)# Construct the positions (the "m" parameter)# shape: (seq_len)m = torch.arange(seq_len, device=device)# multiply each theta by each position using the outer product# shape : (seq_len) outer_product * (head_dim / 2) -> (seq_len, head_dim / 2)freq = torch.outer(m, theta).float()# we can computer complex numbers in the polar form c = R * exp(i * m * theta), where R = 1 as follow# shape: (seq_len, head_dim/2) -> (seq-len, head_dim/2)freq_complex = torch.polar(torch.ones_like(freq), freq)return freq_complexdef apply_rotary_embeddings(x: torch.Tensor, freq_complex: torch.Tensor, device: str):# We transform the each subsequent pair of tokens into a pair of complex numbers# shape : (B, seq_len, head_dim) -> (B, seq_len, h, head_dim / 2)x_complex = torch.view_as_complex(x.float().reshape(*x.shape[:-1], -1, 2))# shape : (seq_len, head_dim / 2) -> (1, seq_len, 1, head_dim / 2)freq_complex = freq_complex.unsqueeze(0).unsqueeze(2)# shape : (B, seq_len, h, head_dim / 2) * (1, seq_len, 1, head_dim / 2) = (B, seq_len, h, head_dim / 2)x_rotate = x_complex * freq_complex# (B, seq_len, h, head_dim / 2) -> (B, seq_len, h, head_dim/2 ,2)x_out = torch.view_as_real(x_rotate)# (B, seq_len, h, head_dim/2, 2) -> (B, seq_len, h * head_dim / 2 * 2)x_out = x_out.reshape(*x.shape)return x_out.type_as(x).to(device)def repeat_kv(x: torch.Tensor, n_rep: int)-> torch.Tensor:batch_size, seq_len, n_kv_heads, head_dim = x.shapeif n_rep == 1:return xelse:return (# (B, seq_len, n_kv_heads, 1, head_dim)x[:, :, :, None, :].expand(batch_size, seq_len, n_kv_heads, n_rep, head_dim).reshape(batch_size, seq_len, n_kv_heads * n_rep, head_dim))class SelfAttention(nn.Module): def __init__(self, args: ModelArgs):super().__init__()self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads# Indicates the number of heads for the queriesself.n_heads_q = args.n_heads# Indiates how many times the heads of keys and value should be repeated to match the head of the Queryself.n_rep = self.n_heads_q // self.n_kv_heads# Indicates the dimentiona of each headself.head_dim = args.dim // args.n_headsself.wq = nn.Linear(args.dim, args.n_heads * self.head_dim, bias=False)self.wk = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wv = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wo = nn.Linear(args.n_heads * self.head_dim, args.dim, bias=False)self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim))self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_kv_heads, self.head_dim))def forward(self, x: torch.Tensor, start_pos: int, freq_complex: torch.Tensor):batch_size, seq_len, _ = x.shape #(B, 1, dim)# Apply the wq, wk, wv matrices to query, key and value# (B, 1, dim) -> (B, 1, H_q * head_dim)xq = self.wq(x)# (B, 1, dim) -> (B, 1, H_kv * head_dim)xk = self.wk(x)xv = self.wv(x)# (B, 1, H_q * head_dim) -> (B, 1, H_q, head_dim)xq = xq.view(batch_size, seq_len, self.n_heads_q, self.head_dim)xk = xk.view(batch_size, seq_len, self.n_kv_heads, self.head_dim)# (B, 1, H_kv * head_dim) -> (B, 1, H_kv, head_dim)xv = xv.view(batch_size, seq_len, self.n_kv_heads, self.head_dim)# Apply the rotary embeddings to the keys and values# Does not chnage the shape of the tensor# (B, 1, H_kv, head_dim) -> (B, 1, H_kv, head_dim)xq = apply_rotary_embeddings(xq, freq_complex, device=x.device)xk = apply_rotary_embeddings(xk, freq_complex, device=x.device)# Replace the enty in the cache for this tokenself.cache_k[:batch_size, start_pos:start_pos + seq_len] = xkself.cache_v[:batch_size, start_pos:start_pos + seq_len] = xv# Retrive all the cached keys and values so far# (B, seq_len_kv, H_kv, head_dim)keys = self.cache_k[:batch_size, 0:start_pos + seq_len]values = self.cache_v[:batch_size, 0:start_pos+seq_len] # Repeat the heads of the K and V to reach the number of heads of the querieskeys = repeat_kv(keys, self.n_rep)values = repeat_kv(values, self.n_rep)# (B, 1, h_q, head_dim) --> (b, h_q, 1, head_dim)xq = xq.transpose(1, 2)keys = keys.transpose(1, 2)values = values.transpose(1, 2)# (B, h_q, 1, head_dim) @ (B, h_kv, seq_len-kv, head_dim) -> (B, h_q, 1, seq_len-kv)scores = torch.matmul(xq, keys.transpose(2,3)) / math.sqrt(self.head_dim)scores = F.softmax(scores.float(), dim=-1).type_as(xq)# (B, h_q, 1, seq_len) @ (B, h_q, seq_len-kv, head_dim) --> (b, h-q, q, head_dim)output = torch.matmul(scores, values)# (B, h_q, 1, head_dim) -> (B, 1, h_q, head_dim) -> ()output = (output.transpose(1,2).contiguous().view(batch_size, seq_len, -1))return self.wo(output) # (B, 1, dim) -> (B, 1, dim)class FeedForward(nn.Module):def __init__(self, args: ModelArgs):super().__init__()# Assuming 'hidden_dim' is calculated as per your specificationshidden_dim = 4 * args.dimhidden_dim = int(2 * hidden_dim / 3) # Applying your specific transformationif args.ffn_dim_multiplier is not None:hidden_dim = int(args.ffn_dim_multiplier * hidden_dim)#hidden_dim = int(2 * hidden_dim / 3) # Applying your specific transformationhidden_dim = args.multiple_of * ((hidden_dim + args.multiple_of - 1) // args.multiple_of)self.w1 = nn.Linear(args.dim, hidden_dim, bias=False)self.w2 = nn.Linear(hidden_dim, args.dim, bias=False) # This layer seems to be missing in your original setupself.w3 = nn.Linear(args.dim, hidden_dim, bias=False) # Corrected to match checkpointdef forward(self, x: torch.Tensor):swish = F.silu(self.w1(x)) # Apply first transformationx_V = self.w3(x) x = swish * x_V # Apply contraction to original dimensionx = self.w2(x) # Apply optional additional transformationreturn xclass EncoderBlock(nn.Module):def __init__(self, args: ModelArgs):super().__init__()self.n_heads = args.n_headsself.dim = args.dimself.head_dim = args.dim // args.n_headsself.attention = SelfAttention(args)self.feed_forward = FeedForward(args)# normalize BEFORE the self attentionself.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)# Normalization BEFORE the feed forwardself.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)def forward(self, x: torch.Tensor, start_pos: int, freqs_complex: torch.Tensor):# (B, seq_len, dim) + (B, seq_len, dim) -> (B, seq_len, dim)h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_complex)out = h + self.feed_forward.forward(self.ffn_norm(h))return outclass RMSNorm(nn.Module):def __init__(self, dim: int, eps: float = 1e-5):super().__init__()self.eps = eps# The gamma parameterself.weight = nn.Parameter(torch.ones(dim))def _norm(self, x: torch.Tensor):# (B, seq_len, dim) -> (B, seq_len, 1)return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, x: torch.Tensor):# dim : (B, seq_len, dim) -> (B, seq_len, dim)return self.weight * self._norm(x.float()).type_as(x)class Transformer(nn.Module):def __init__(self, args: ModelArgs) -> None:super().__init__()assert args.vocab_size != -1, "Vocab size must be set"self.args = argsself.vocab_size = args.vocab_sizeself.n_layers = args.n_layersself.tok_embeddings = nn.Embedding(self.vocab_size, args.dim)self.layers = nn.ModuleList()for _ in range(args.n_layers):self.layers.append(EncoderBlock(args))self.norm = RMSNorm(args.dim, eps=args.norm_eps)self.output = nn.Linear(args.dim, self.vocab_size, bias=False)# To precompute the frequencies of the Rotary Positional Encodingsself.freqs_complex = precomputed_theta_pos_frequencies(self.args.dim // self.args.n_heads, self.args.max_seq_len * 2, device=self.args.device)def forward(self, tokens: torch.Tensor, start_pos: int):# (B, seq_len)batch_size, seq_len = tokens.shapeassert seq_len == 1, "Only one token at a time can be processed"# (B, seq_len) -> (B, seq_len, dim)h = self.tok_embeddings(tokens)# Retrive the pairs (m, theta) corresponding to the positions [start_pos, start_pos + seq_len]freqs_complex = self.freqs_complex[start_pos:start_pos + seq_len]# Consecutively apply all the encoder layersfor layer in self.layers:h = layer(h, start_pos, freqs_complex)h = self.norm(h)output = self.output(h).float()return output
系列博客
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(一)Llama3 模型 架构
https://duanzhihua.blog.csdn.net/article/details/138208650
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(二)RoPE位置编码
https://duanzhihua.blog.csdn.net/article/details/138212328
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(三)KV缓存
https://duanzhihua.blog.csdn.net/article/details/138213306
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(四)分组多查询注意力
https://duanzhihua.blog.csdn.net/article/details/138216050
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(五)RMS 均方根归一化
https://duanzhihua.blog.csdn.net/article/details/138216630
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(六)SwiGLU 激活函数
https://duanzhihua.blog.csdn.net/article/details/138217261
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(七)前馈神经网络
https://duanzhihua.blog.csdn.net/article/details/138218095
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(八)Transformer块
https://duanzhihua.blog.csdn.net/article/details/138218614
探索和构建 LLaMA 3 架构:深入探讨组件、编码和推理技术(九)Llama Transformer架构
https://duanzhihua.blog.csdn.net/article/details/138219242
立即解锁无限学习的大门,快速报名,开启知识的奇妙旅程!