
笔记整理:喻靖,浙江大学硕士,研究方向为大语言模型
论文链接:https://arxiv.org/pdf/2310.07793
发表会议:NAACL2024
摘要
随着大语言模型(LLMs)的迅速发展,人们对时间知识图谱(tKG)领域的兴趣日益增长。传统上,tKG领域的预测任务主要由基于嵌入和基于规则的方法主导。然而,这些方法在处理复杂的时间关系数据时存在显著局限性,特别是在应对数据规模、复杂的图结构,以及模型在不同数据集和时间切分下的适应性时。为了探索大语言模型在处理时间关系数据方面的潜力,本文提出了一种新的生成式预测框架GenTKG,该框架结合了基于检索的增强生成策略和少样本参数高效调优方法,以解决上述挑战。
1. 背景
时间知识图谱(tKG)是一个包含多重关系的有向图,节点间的边带有时间戳,表示随时间变化的世界知识。tKG任务的主要目标是在给定过去历史事件的基础上预测未来的事件。例如,在预测给定时间点的某个实体关系时,传统方法通常通过嵌入模型将时间四元组嵌入到隐空间中,或者通过挖掘图结构中的时间逻辑规则来进行预测。然而,这些方法在面对数据集的微小修改、时间分割的变化时表现出不足。此外,它们往往忽略了tKG中事件的语义信息,只注重隐式的结构性表示,缺乏跨领域和跨时间的泛化能力。
在将大语言模型应用于tKG的生成式预测任务时,存在两个主要挑战:
(1)模态差异:tKG的数据结构复杂,包含大量的时间四元组,这些数据难以适应大语言模型能够处理的序列化自然语言表达。
(2)计算成本:LLMs在处理如此大规模的时间知识图谱数据时,微调所需的计算成本极高,尤其是在需要几个月时间的大规模训练任务中。
2. 贡献
(1)开创了时间知识图谱生成式预测的新领域:GenTKG首次将指令调优的生成式大语言模型引入到时间知识图谱领域,并提出了一种新的检索增强生成框架,展示了LLMs在时间关系预测任务中的巨大潜力。
(2)低计算成本下的超越性能:通过极少样本的参数高效指令调优,GenTKG在计算资源极为有限的情况下实现了对传统方法的超越性能,展示了其在有限数据和计算资源下的优异表现。
(3)从数据学习到任务对齐的转变:GenTKG创新性地将传统的基于数据的学习转变为基于任务的对齐,通过指令调优,使大语言模型与时间知识图谱预测任务对齐,实现了更高效的任务执行。
(4)卓越的泛化能力:GenTKG展示了强大的跨数据集泛化能力和域内泛化能力,能够在不同数据集和时间切分下保持一致的高性能。
3. 方法
为了解决上述挑战,本文提出了一种新的检索增强生成框架GenTKG。该框架结合了基于时间逻辑规则的检索策略(Temporal Logical Rule-based Retrieval, TLR)和少样本参数高效指令调优策略(Few-shot Parameter-Efficient Instruction Tuning, FIT),能够在计算资源有限的情况下,以极少的训练数据实现对tKG的生成式预测。
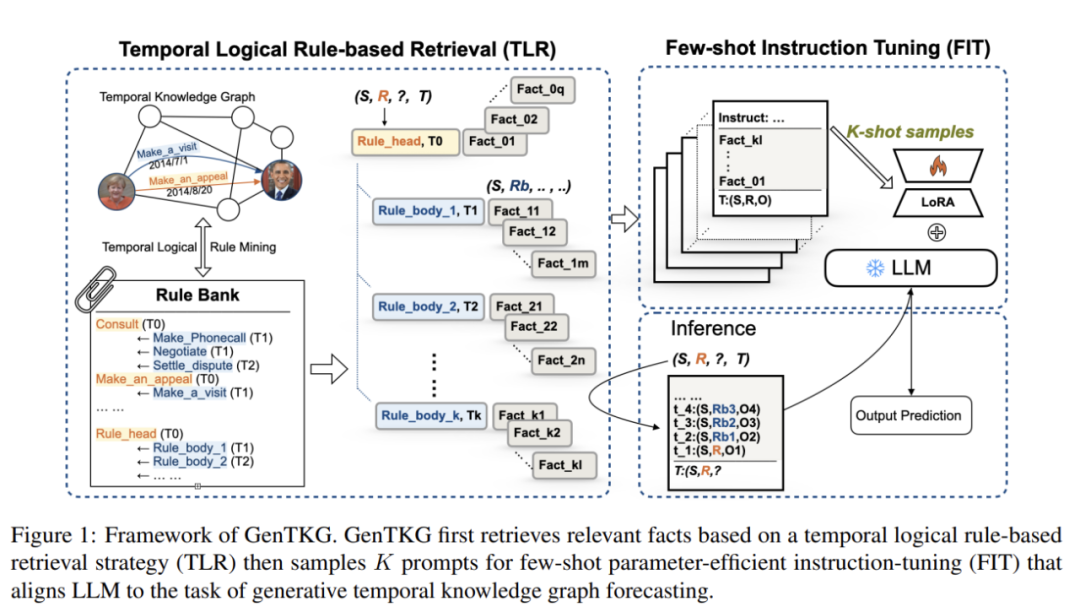
基于时间逻辑规则的检索策略(TLR):TLR策略通过挖掘tKG中的时间逻辑规则,构建了一个规则库。利用这些规则,可以检索出与给定查询在时间和逻辑上最相关的历史事实,并将这些历史事实按照时间顺序转换为自然语言,填充到为LLMs设计的特定提示模板中。尽管这些提示是以自然语言的形式出现,但它们隐含了tKG的结构信息,使得LLMs能够理解时间关系数据。
时间随机游走的过渡分布公式:为了检索与给定查询相关的历史事件,GenTKG使用了时间随机游走的概念,该过渡分布公式如下:
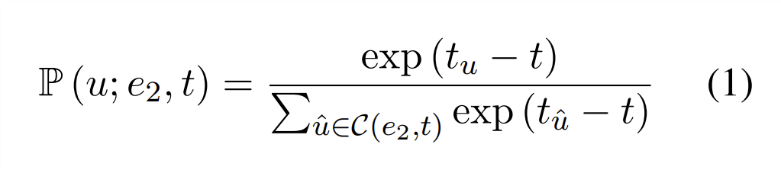
该公式确保检索出的历史事实在时间上更接近于当前查询,使得生成式预测更符合时间逻辑。
时间逻辑规则的定义:时间逻辑规则用于捕捉tKG中的时间模式,规则定义如下:
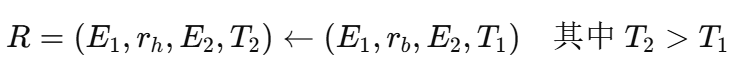
则的含义是,如果规则主体在时间 T1T_1T1 成立,那么在未来时间 T2T_2T2,规则头部也可能成立。
规则置信度的计算:规则置信度衡量时间逻辑规则的可靠性,其计算公式为:

置信度越高,表示规则在历史数据中成立的频率越高,因此被认为是更可靠的规则。
少样本参数高效指令调优策略(FIT):FIT策略通过指令调优,将LLMs与时间关系预测任务对齐,并将其重新定义为自回归生成任务。为了降低计算成本,本文采用了一种参数高效的微调方法(Low-Rank Adaptation, LoRA),仅需要极少的训练数据(少至16个样本)即可实现对tKG的高效调优。此外,FIT策略通过对任务指令、检索的历史事实输入以及生成的预测结果的精心设计,使LLMs能够在tKG任务上表现出色。

该图展示了用于微调语言模型的指令提示设计。提示分为三部分:任务指令(解释任务的定义),任务输入(包括检索到的历史事实),以及任务输出(预测的未来事件)。
4. 实验结果
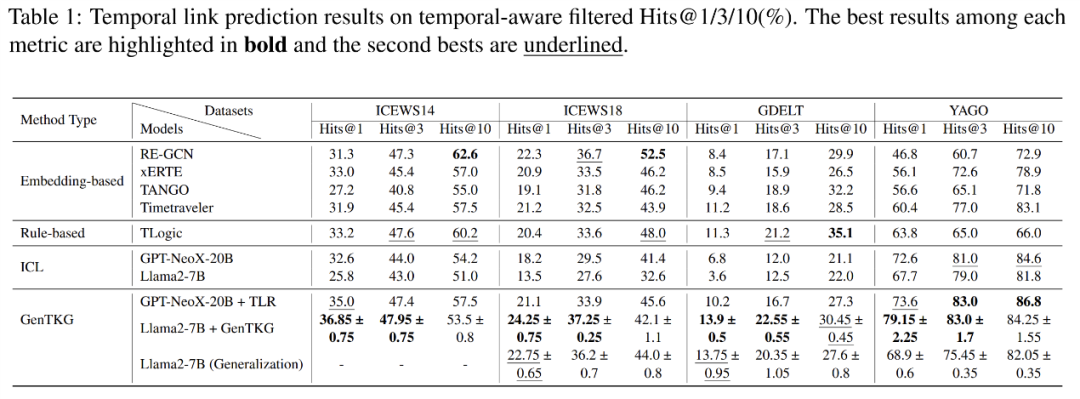
通过在多个tKG基准数据集上的广泛实验,GenTKG展示了其在计算资源有限的情况下,利用极少量的训练数据(如1024个样本)的超越性能。与传统方法相比,GenTKG在准确性上显著优于嵌入方法、基于规则的方法以及近期提出的基于上下文学习(ICL)的方法。此外,GenTKG还表现出了卓越的跨领域泛化能力,无需重新训练便能在多个未见过的数据集上取得优异的表现。
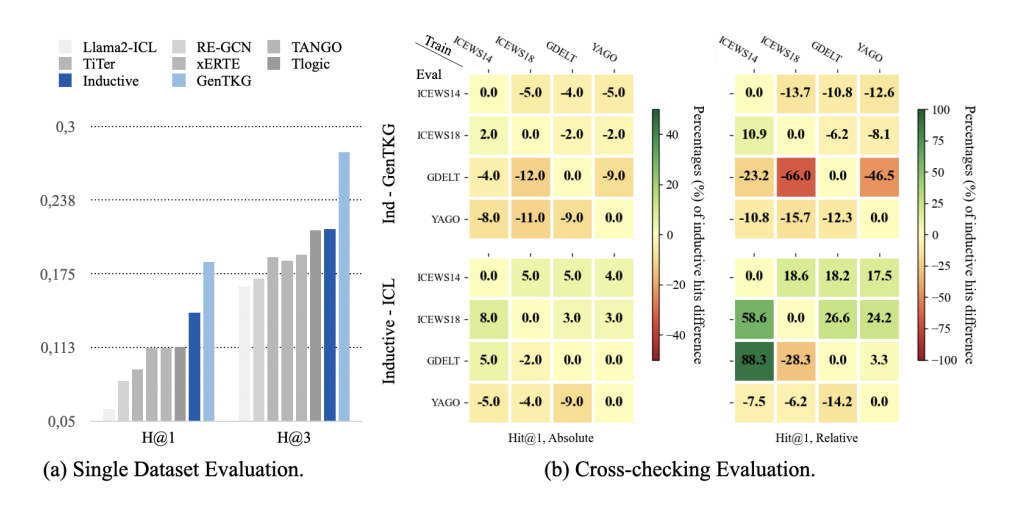
该图展示了GenTKG框架在跨领域泛化中的表现。在(a)小图中,GenTKG在ICEWS14数据集上训练,在GDELT数据集上评估,表现与在相同数据集上训练和评估的情况相当。(b)小图通过交叉检查不同训练和评估数据集,突出了GenTKG在不同领域中维持性能的能力。
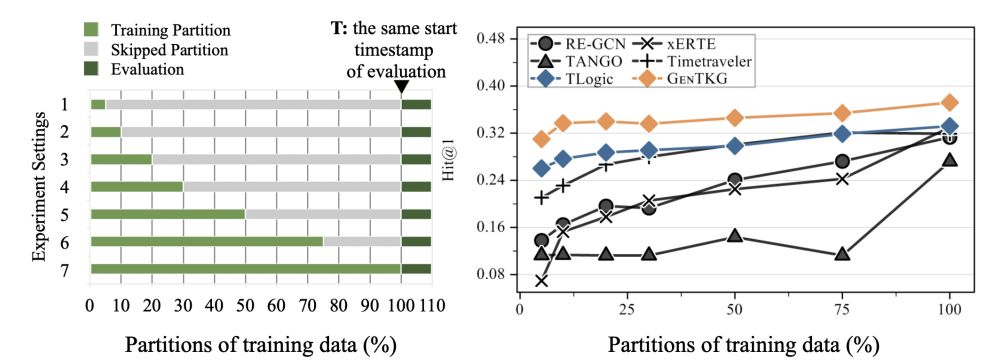
该图分析了GenTKG在同一数据集内使用不同训练数据分区时的泛化能力。即使在使用有限的训练数据(如原始数据的5%)的情况下,GenTKG依然优于传统方法,展示了其强大的性能和稳定性。
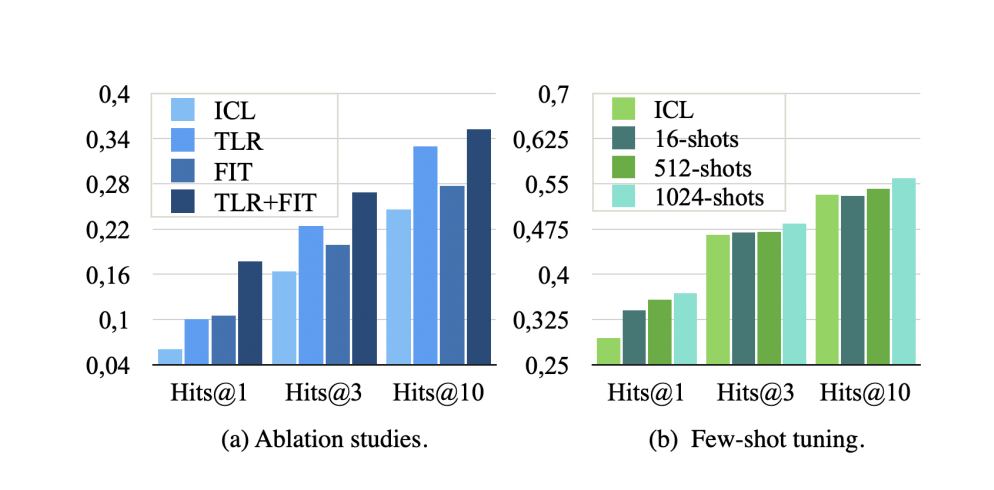
在(a)小图中可以看到,TLR和FIT阶段都显著提升了GenTKG的性能,结合使用这两个阶段能够获得最佳结果。(b)小图显示了增加少样本训练样本数量可以提高性能,强调了该框架在有限数据学习中的效率。
5. 总结
GenTKG通过结合时间逻辑规则的检索策略和少样本的参数高效指令调优,为大语言模型在时间知识图谱生成式预测中的应用开辟了新的前沿。该框架不仅在预测准确性和计算效率上表现出色,还展示了卓越的泛化能力,表明大语言模型在tKG领域中的巨大潜力和应用前景。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
![[C++ 核心编程]笔记 1 内存分区模型](https://i-blog.csdnimg.cn/direct/84ab5de008ad4cb6ab78bd1bdc4d1946.png#pic_center)






