前言
当我们3月下旬微调完Mixtral 8x7B之后(更多详见:七月论文大模型:含论文的审稿、阅读、写作、修订 ),下一个想微调的就是llama2 70B
- 因为之前积攒了不少微调代码和微调经验,所以3月底apple便通过5K的paper-review数据集成功微调llama2 70B,但过程中也费了不少劲
- 考虑到最后的成功固然令人欣喜,但真正让一个人或一个团队快速涨经验的还是那些在训练过程中走过的踩过的各种坑以及走过的各种弯路,所以本文第一部分我会把apple在训练中的遇到各种报错信息而一步步debug、或各种搜Google、搜GitHub的过程都整理出来
进入到4月份之后,我们先针对数据折腾了一把,毕竟数据质量通常是一个项目效果的天花板,然数据质量的提升不是短短一两周的事情,考虑到为并行加速
三太子进入70B微调组,和apple一起继续拿之前处理好的数据继续微调70B,但这一次是用15K的数据量了
第一部分 通过1.5K条paper-review数据微调LLaMA2 70B
1.1 GPU配置情况:8张80G的A100
以下是训练过程中GPU的占用情况
- git lfs clone https://huggingface.co/NousResearch/Llama-2-70b-chat-hf ,这个命令运行结束后,硬盘占用为518GB
- 配置环境开始训练后,硬盘占用为522GB
- 训练完成后硬盘占用为566GB
- merge_lora完成后硬盘占用为694GB,训练结束时内存占用262GB
观测到训练过程中显存最高占用为570GB,故建议使用80GB*8卡训练
1.2 1.5K数据的运行过程记录
- 03-19 3:55 flash_attn 设置成false和true都会报错q_len %d should be divisible by group size %d,且每张卡报错by group size后面数字不同
raise ValueError("q_len %d should be divisible by group size %d." % (q_len, group_size))
ValueError: q_len 8454 should be divisible by group size 2113.
最终,修改train.py中的文件引用:即把from attention.llama_attn_replace import replace_llama_attn改成如下图所示,解决报错
- 03-19 8:53 8*A100 成功开始训练 1500 条数据

- 03-19 9:34 apple按照阿旬建议,多卡训练,需要修改配置文件参数

- 03-19 13:09 1500 条数据训练成功完成,2 epoch 用时 3小时07 分

第二部分 开始训练 5000 条数据
2.1 5K数据的训练全程
2.1.1 第一阶段:flash_attn频频出问题
- 03-19 18:00 发现训练至 0.48epoch 2小时30分,到batch_id:164 2624条数据报错./aten/src/ATen/native/cuda/Indexing.cu:1141: indexselectLargeIndex: block: [613,0,0], thread.[61,0,0]Assertion`srcIndex<srcSelectDimsize` failed.
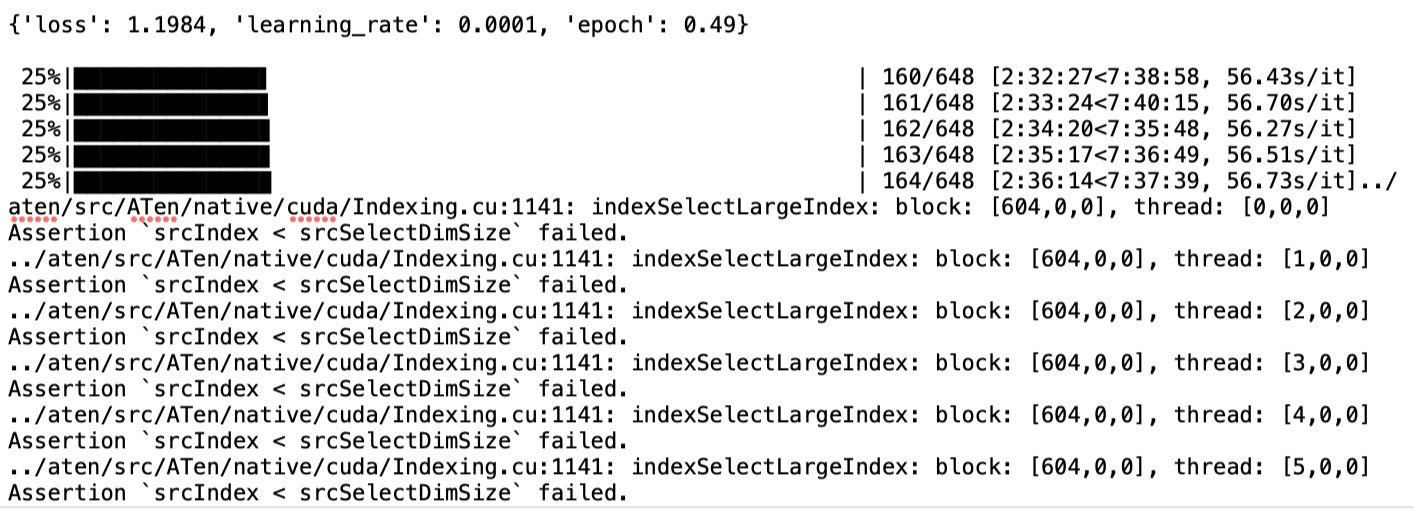

- 03-19 23:11 之前的训练过程中dataset没加padding
即如阿荀所说:“我的这个dataset是没实现padding的,所以要用datacollator来做”,故需要在train.py中更正使用DataCollatorForSeq2Seq# 分别计算输入、输出合适的截断# `output_ids` 在整个序列(包括 `input_format_ids` 和 `output_ids`)中所占的比例,然后这个比例乘以最大序列长度,得到的结果就是输出序列的最大长度max_output_len = int(self.max_seq_length * (len(output_ids) / (len(input_format_ids) + len(output_ids))))max_output_len = max(max_output_len, 1) # 至少保留1个token的outputmax_input_len = self.max_seq_length - max_output_len# 对输入、输出进行截断if len(input_format_ids) > max_input_len:input_format_ids = input_format_ids[:max_input_len]if len(output_ids) > max_output_len:output_ids = output_ids[:max_output_len]
然并卵,修改后训练仍有index报错# 加载训练集和验证集if args.sft:# train_dataset = VicunaSFTDataset(args.train_file, tokenizer, args.max_seq_length)train_dataset = Llama2SFTDataset(args.train_file, tokenizer, args.max_seq_length)# data_collator = SFTCollator(tokenizer, args.max_seq_length, -100)data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer,pad_to_multiple_of=8 if tokenizer.padding_side == "right" else None, # for shift short attentionlabel_pad_token_id=-100)else:train_dataset = PretrainDataset(args.train_file, tokenizer, args.max_seq_length)data_collator = PretrainCollator(tokenizer, args.max_seq_length, -100)data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer,pad_to_multiple_of=8 if tokenizer.padding_side == "right" else None, # for shift short attentionlabel_pad_token_id=-100) - 03-20 1:51 考虑到阿荀建议“看下目前用llama_attn_replace_sft能不能训,不能的话可能可以考虑切换下llama_attn_replace”
故apple在train.py中更正回train.py引用文件llama_attn_replace使用,可修改后训练仍有index报错 - 03-20 4:00 尝试搜索到的解决方案,将结尾pading改为eos,修改后训练仍有index报错
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer,pad_to_multiple_of=8 if tokenizer.padding_side == "right" else None, # for shift short attentionlabel_pad_token_id=tokenizer.eos_token_id) - 03-20 10:11 尝试搜索到的解决方案https://github.com/lm-sys/FastChat/issues/2038,将训练数据中的特殊token清洗,修改后训练仍有index报错

- 03-20 11:25 取训练数据2400-2880行,对应batchsize id:150-180,直接训练这个区间 1 epoch,epoch结束后有一个warning,除此之外是没有报错的

- 03-20 12:03 训练过程中,在阿荀建议下,尝试关掉flash_attn,训练未开始就会有多个单卡报错OOM
至于原因,可能是如阿荀所说:“单张不够这长度,因为longqlora的lora是用32位精度的,而70b的产生的kv cache会比7b的大很多”
- 03-20 15:23 使用python -m bitsandbytes查看bnb没有编译问题,在阿荀建议下,apple将flash_attn降到2.3.3版本,修改后训练仍有index报错
2.1.2 第二阶段:用上DeepSpeed Zero3,且验证flash_attn得开
- 一开始以为longlora论文中使用deepspeed stage3(当然其只用lora没有用qlora),实现了llama70b训练(但后来才发现,longlora论文中微调70B时,flash_attn其实是加了的)
我们也可以使用stage3优化,这个可以实现关闭flash_attn的情况下,在多卡训练70b,故
03-22 13:51 设置flash_attn=false,修改配置文件,使用DeepSpeed Zero-3,报错ValueError: DeepSpeed Zero-3 is not compatible with `low_cpu_mem_usage=True` or with passing a `device_map`.需要注释掉train.py中的device_map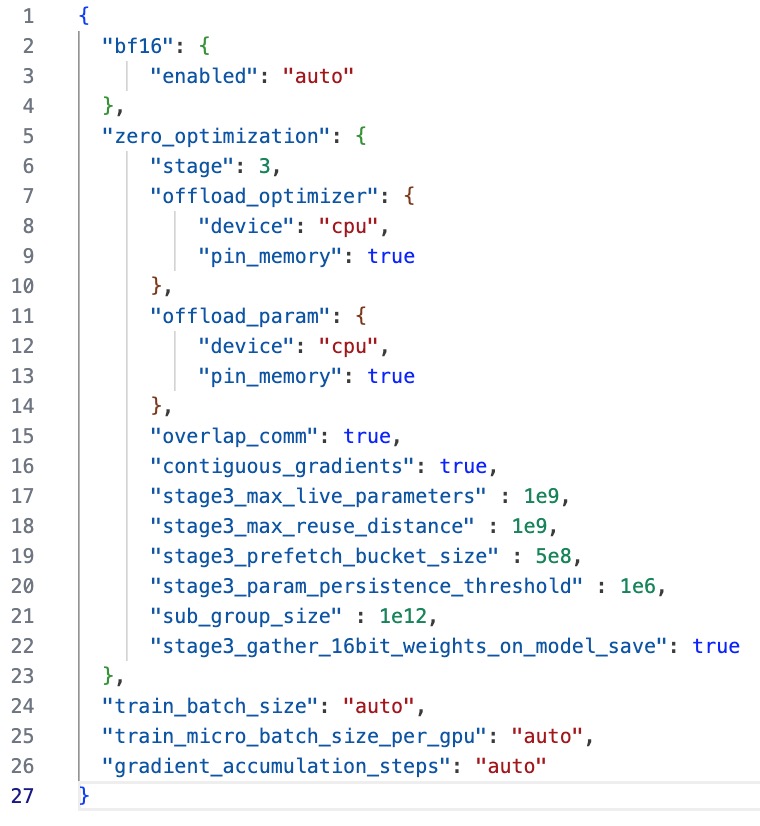
- 03-22 14:10 报错expected there to be only one unique element in {items}查找到解决方案
https://github.com/bigcode-project/starcoder/issues/96 https://huggingface.co/docs/peft/v0.10.0/en/accelerate/deepspeed - 03-22 16:30 更换为8*RTX A6000
quantization_config添加参数:bnb_4bit_quant_storage_dtype=torch.bfloat16
从运行bash命令到开始训练需要17分钟,进入训练后再次报错
expected there to be only one unique element in <generator object Init._convert_to_deepspeed_param.<locals>.all_gather_coalesced.<locals>.<genexpr> at 0x7f6ee96924a0> - 03-22 17:08 查到已经有人提交了修复这个问题的pr Enable ZeRO3 allgather for multiple dtypes (#4647) · microsoft/DeepSpeed@b8e1664 · GitHub,故pip uninstall deepspeed 然后pip install deepspeed 下载最新版本
然训练未开始便报错cuda out of memory,看来还是要用8*A100 - 03-22 19:48再次使用8*A100成功开始训练,最后在第四步报错,如果不开flash_attn,即使开了deepspeed stage3也会报显存不够的错误。torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 7.33 GiB (GPU 6; 79.15 GiB total capacity; 44.34 GiB already allocated; 6.52 GiB free; 70.42 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF

- 考虑到虽然调通了deepspeed stage3 发现即使A100*8,如果不加flash_attn,训练到第4个batch就会out of memory,即准备再打开flash_attn ,将所有buff一起叠加,看看是不是可以(相当于把longqlora、Zero3、flash attention都用上),故
03-22 20:10 使用8*A100,打开flash_attn,打开deepspeed stage3,开始训练
这次训练时显存占用呈周期涨落而不是一直上升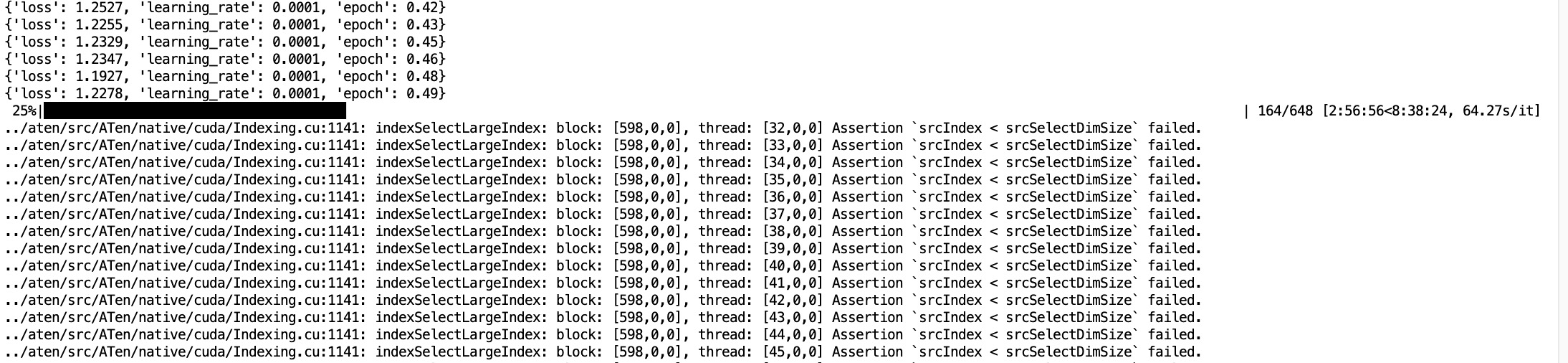
不过仍然结果还是会在batch id 16报错
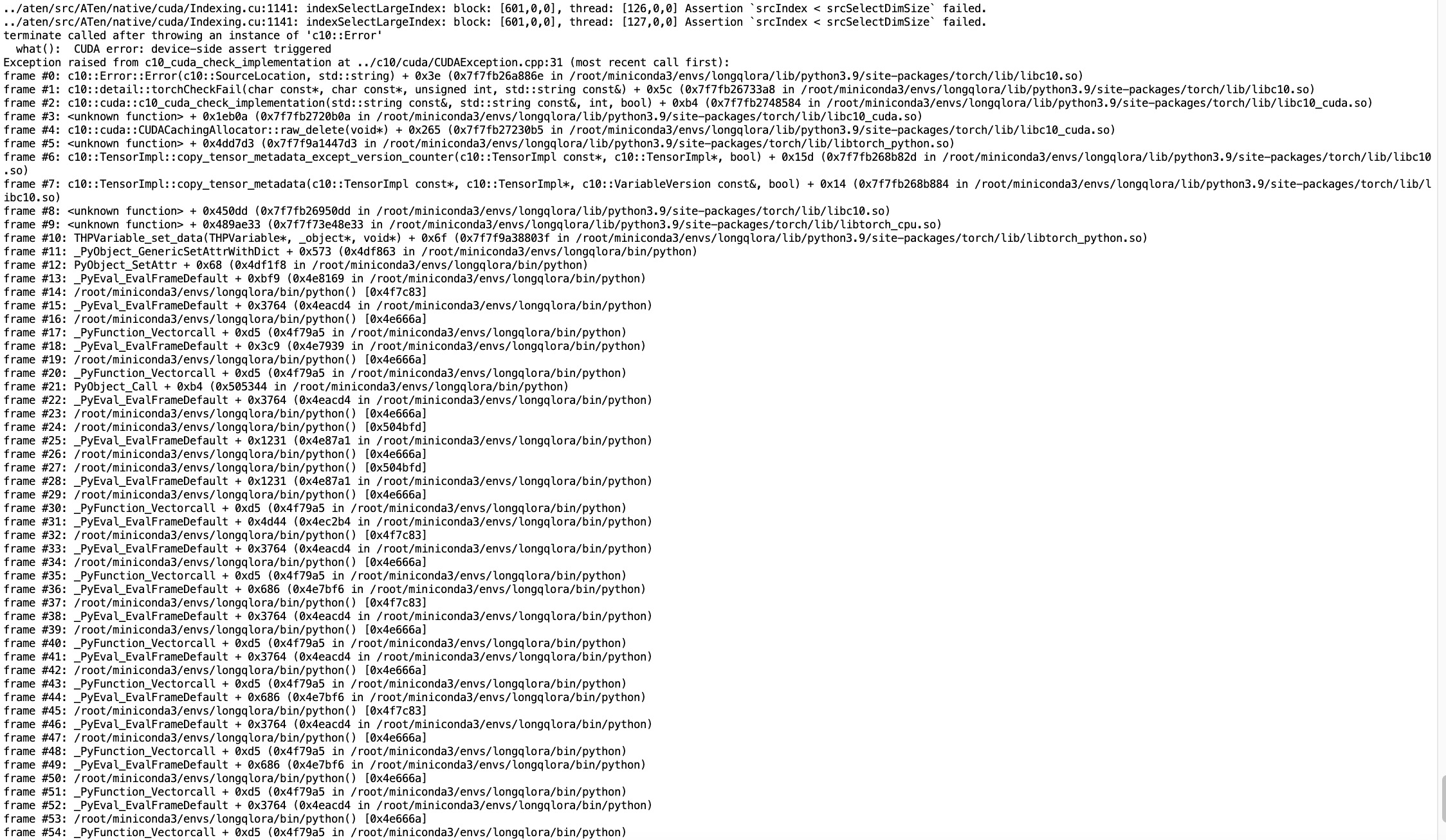
2.1.3 第三阶段:二分定位筛选有问题的那条数据
我建议apple,既然是跑的5000多条数据,那可以
- 考虑把引发异常的那条数据 先直接剔除掉,毕竟如果实在怀疑某些数据有问题的话,先删掉,哪怕最后有个3-4K数据 能跑下来,也算是先有个结果
- 之后 再慢慢找问题(总之,算是短期内 没办法的办法了,后续时间充足时,再好好找下 全面的原因)
故apple便开始用二分定位法去排查那条引起异常的数据
- 03-23 13:34 将5189数据从上到下的顺序分成3份,1-1730,1730-3460,3461-5189,分别测试查找问题数据所在的区间。第一份在运行至batch_id 33报错。
- 03-23 19:33 第二份1730条训练没有报错
- 03-23 21:25 之前下午第二份数据在训练中总的迭代次数是432,发现第三份数据在训练中总迭代次数是216,所以其它所有变量相同条件下,由于迭代数减小1/2训练总时间也缩减了1/2,不清楚这里是否正常,训练参数配置文件是相同的,不过1730条数据集第二份的大小是120MB,第三份的大小是50MB,是否是训练数据大小的原因导致训练时产生了自动调整。第三份1728条训练没有报错。
- 03-23 22:36 按顺序取出第一份数据的后半部分,866-1730行,训练中batch_id 18
报错。 - 03-23 22:55 按顺序取出第一份数据的前半部分,1-865行,训练没有报错。
- 03-24 00:28 按顺序取出第一份数据的,866-1298行,训练没有报错。
- 03-24 01:37 按顺序取出第一份数据的,1299-1500行,训练中batch_id 8报错。
- 03-24 02:32 按顺序取出第一份数据的,1501-1730行,训练没有报错。
- 03-24 03:13 按顺序取出第一份数据的,1299-1400行,训练没有报错。
- 03-24 03:46 按顺序取出第一份数据的,1401-1500行,训练中batch_id 1报错
- 03-24 05:08 从paper_review_5189.jsonl去除1401-1500行,最终使用5089条数据开始训练
相当于相当于最终筛到100条的区间,删掉后使用5089条数据微调成功(实在是不易啊,如apple所说:“筛选数据我是二分法,从昨天下午1点一直做到今早凌晨5点。”)
总之,12小时后训练成功,checkpoint文件夹和merge_lora文件夹结构如下
2.2 对5K训练数据结果的推理
- 03-24 18:39 开始推理285条测试数据
- 03-25 02:23 285条训练数据推理结束
- 在论文审稿效果上超过GPT4-1106,且70B只用了5K数据便和7B用的15K数据打平了


考虑到可能是数据只有5K,效果不一定好上,故如本文开头所说,我们接下来准备一方面提高数据质量,一方面准备用更大的比如15K数据微调
第三部分 15k运行过程记录
3.1 训练全过程
3.1.1 apple继续折腾
- 03-27 9:56 继续筛选paper_review_5189.jsonl中的1401-1500行,从中找到具体的报错数据,分析其特征,对15k数据进行清洗
取出文件中的第1401-1420行另存为output1.jsonl没有问题
取出文件中的第1421-1440行另存为output2.jsonl没有问题
取出文件中的第1441-1460行另存为output3.jsonl有报错
取出文件中的第1461-1480行另存为output4.jsonl没有报错
取出文件中的第1481-1500行另存为output5.jsonl没有报错 - 03-27 17:08 继续筛选paper_review_5189.jsonl中的1441-1460行
取出文件中的第1441-1445行另存为2output1.jsonl没有问题
取出文件中的第1446-1450行另存为2output2.jsonl没有问题
取出文件中的第1451-1455行另存为2output3.jsonl报错
取出文件中的第1456-1460行另存为2output4.jsonl没有报错 - 03-27 17:45 继续筛选paper_review_5189.jsonl中的1451-1455行
取出文件中的第1451行另存为3output1.jsonl没问题
取出文件中的第1452行另存为3output2.jsonl没问题
取出文件中的第1453行另存为3output3.jsonl报错
取出文件中的第1454行另存为3output4.jsonl
取出文件中的第1455行另存为3output5.jsonl
最终的问题数据是第1453行另存为3output3.jsonl报错 - 考虑到因为最开始用1.5k的数据微调llama7b时,打开flash_attn会有同样报错,故
03-30 5:52 经过1d18h使用A6000前置验证没有问题 - 03-30 13:06 开始使用8*A100配置环境下载basemodel正式训练,20h后查看到训练中断,可能是服务器平台的未知原因
- 03-30 16.01 重新恢复后,继续折腾

3.1.2 三太子接力apple:全力折腾
一开始三太子先试下5k数据,截断的逻辑也用的七月官网首页的「大模型线上营」中讲的
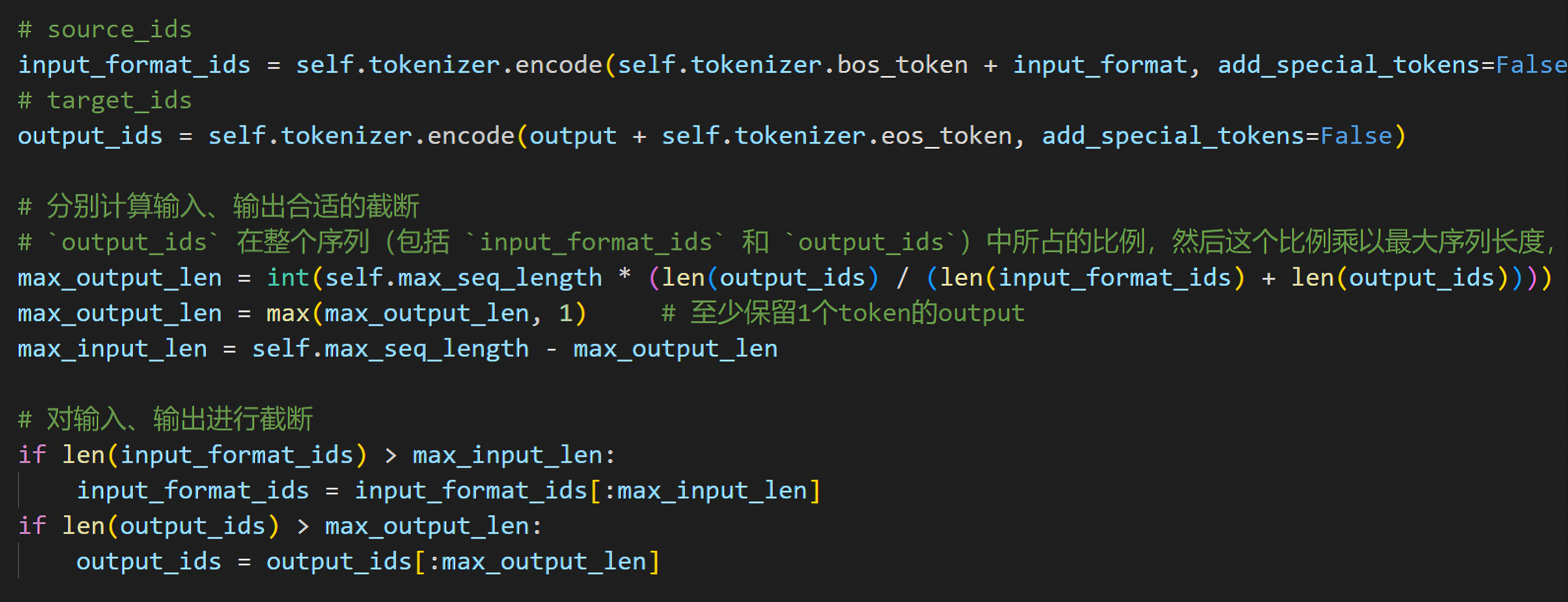
更多见七月官网首页的:大模型商用项目之审稿微调实战营
3.2 15K数据的结果评估
暂见于七月官网首页的:大模型商用项目之审稿微调实战营