Location: Beijing
1 大模型剪枝

剪枝的分类:结构化修剪对于简化大型语言模型和提高其效率尤其相关。非结构化修剪关注的是选择性地去除单个权重,旨在消除网络中不那么关键的连接。
修剪的基于阶段的分类:修剪可以在训练前、训练期间或训练后。
2 大模型持续学习
2.1 持续学习与基于持续学习的剪枝
持续学习侧重于在动态环境中适应大型语言模型,从而在不丢失先验知识的情况下实现持续学习。
在持续学习领域,剪枝的作用有助于有效地维护和进化神经网络结构,COPAL提出一种优化LLM的新方法,该方法绕过了再训练过程。
2.2 在LLM中持续修剪的缺点
持续修剪涉及到对不断进化的模型权重进行修剪,而不失去预训练的LLM的原始能力。
2.2.1 持续剪枝
持续剪枝在重点和方法上不同于基于持续学习的剪枝。基于持续学习的剪枝只是在不断进化的环境中使用剪枝来管理网络复杂性。相比之下,持续修剪是指在整个生命周期中发生的无训练修剪过程。面对所有遇到的数据集,持续剪枝会动态地调整相关的权重。
2.2.2 持续剪枝中的权重停滞(WS)
如果对已经归零的修剪权值保持不变,这导致在将模型从一个数据集转换到另一个数据集时没有响应。称这个概念为“权重停滞”(WS)。在下面是从校准引导的修剪策略中观察到的权重停滞的数学见解。
考虑到权值的重要性,以 W i ∗ = ∣ W i ⋅ R i ∣ \mathbf{W}_i^*=|\mathbf{W}_i\cdot\mathcal{R}_i| Wi∗=∣Wi⋅Ri∣作为剪枝过程的基础,其中 R i \mathcal{R}_i Ri是用一些标准对权值 W i \mathbf{W}_i Wi进行缩放或排序。对于给定的数据集 i i i、掩膜0器(原文叫mask) M i \mathcal{M}_{i} Mi和 I \mathcal{I} I作为指标函数,得到的修剪权值矩阵 W i p \mathbf{W}_{i}^{p} Wip如下:
M i = I ( W i ∗ < T s ) = { 0 if w i ∗ < T s , w i ∗ ∈ W i ∗ 1 otherwise. , W i p = W i ⋅ M i . (1) \begin{aligned}&\mathcal{M}_{i}=\mathcal{I}(\mathbf{W}_{i}^{*}<\mathcal{T}_{s})=\begin{cases}0&\text{if }\mathbf{w}_{i}^{*}<\mathcal{T}_{s},\mathbf{w}_{i}^{*}\in\mathbf{W}_{i}^{*}\\1&\text{otherwise.}\end{cases}, \\&\mathbf{W}_{i}^{p}=\mathbf{W}_{i}\cdot\mathcal{M}_{i}.\end{aligned}\tag{1} Mi=I(Wi∗<Ts)={01if wi∗<Ts,wi∗∈Wi∗otherwise.,Wip=Wi⋅Mi.(1)
式中,阈值 T s \mathcal{T}_{s} Ts根据目标的稀疏比 s s s浮动,可以看出该公式的作用就是如果某个权值没有达到给定条件就置0,达到了就不变。
然而,对于下一个数据集 i + 1 i+1 i+1,需要剪枝的权重 W i + 1 = W i p \mathbf{W}_{i+1}=\mathbf{W}_i^p Wi+1=Wip,这个初始矩阵 W i + 1 \mathbf{W}_{i+1} Wi+1已经有一组修剪(零)权重。最终这一次剪枝之后的权重矩阵如下:
M i + 1 = I ( W i + 1 ∗ < T s ) = I ( ∣ W i ⋅ R i + 1 ∣ ⋅ ∣ M i ∣ < T s ) = M i , W i + 2 = W i + 1 = W i ⋅ M i . (2) \begin{aligned} &\mathcal{M}_{i+1} =\mathcal{I}\left(\mathbf{W}_{i+1}^*<\mathcal{T}_s\right) \\ &=\mathcal{I}(|\mathbf{W}_{i}\cdot\mathcal{R}_{i+1}|\cdot|\mathcal{M}_{i}|<\mathcal{T}_{s})=\mathcal{M}_{i}, \\&\mathbf{W}_{i+2} =\mathbf{W}_{i+1}=\mathbf{W}_i\cdot\mathcal{M}_i. \end{aligned}\tag{2} Mi+1=I(Wi+1∗<Ts)=I(∣Wi⋅Ri+1∣⋅∣Mi∣<Ts)=Mi,Wi+2=Wi+1=Wi⋅Mi.(2)
总结一下如下图
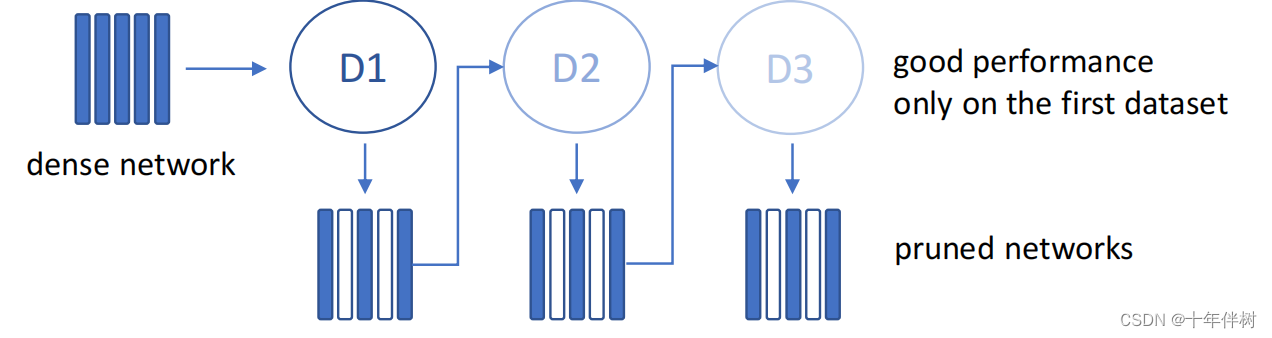
剪了个寂寞,这显然不合理。
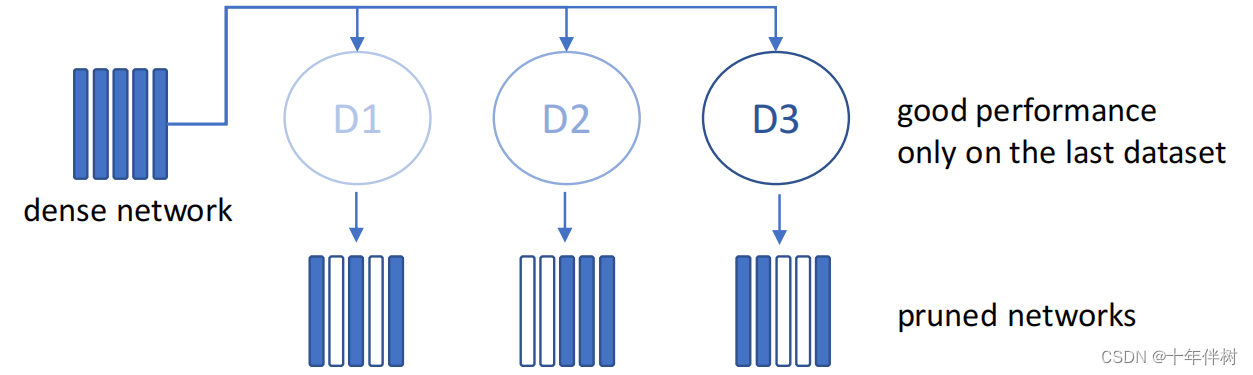
2.2.3 持续剪枝中的遗忘问题(Forgetting)
当使用新的校准数据集更新修剪后的模型权值时,可以观察到这种健忘现象,这将降低以前遇到的数据集或任务的性能,如图1.3
3 COPAL:基于敏感度分析的连续剪枝
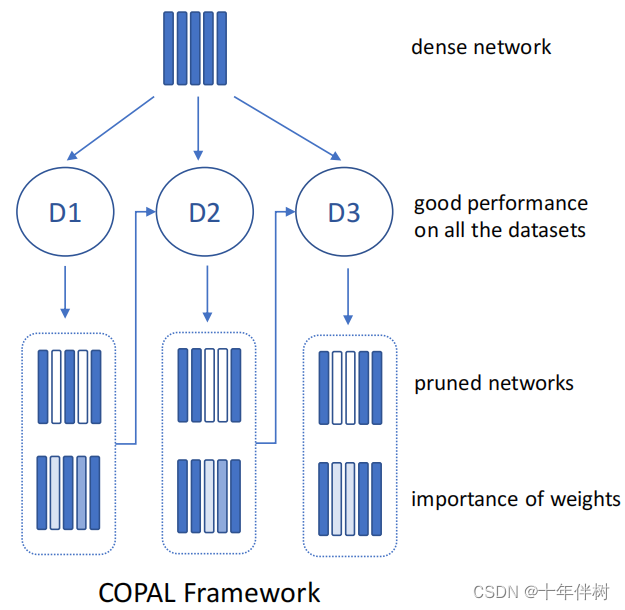
这篇文章的主要创新点是寻找关键权重的方法。
为了克服遗忘和权重停滞,提出了一个基于敏感度分析的连续神经网络剪枝框架。总结这种方法如图3.1
3.1 敏感度
对于神经网络的给定层,可以得出 y \mathbf{y} y对 d X j i d\mathbf{X}_j^i dXji和 d W d\mathbf{W} dW的敏感度,服从下式
d y j i = ∂ f ∂ X j i d X j i + ∂ f ∂ W d W (3) d\mathbf{y}_j^i=\frac{\partial f}{\partial\mathbf{X}_j^i}d\mathbf{X}_j^i+\frac{\partial f}{\partial\mathbf{W}}d\mathbf{W}\tag{3} dyji=∂Xji∂fdXji+∂W∂fdW(3)
在实际应用中用 Δ X j i \Delta\mathbf{X}_{j}^{i} ΔXji和 Δ W \Delta\mathbf{W} ΔW来代替 d X j i d\mathbf{X}_j^i dXji和 d W d\mathbf{W} dW可以对 y y y转化为灵敏度的表示如下式
S W i j = ∂ f ∂ W × Δ W , S X i j = ∂ f ∂ X i i × Δ X j i . (4) \begin{gathered} S_{\mathrm{W}}^{ij} =\frac{\partial f}{\partial\mathbf{W}}\times\Delta\mathbf{W}, \\ S_{\mathbf{X}}^{ij} =\frac{\partial f}{\partial\mathbf{X}_i^i}\times\Delta\mathbf{X}_j^i. \end{gathered}\tag{4} SWij=∂W∂f×ΔW,SXij=∂Xii∂f×ΔXji.(4)
S W i j S_{\mathbf{W}}^{ij} SWij和 S X i j S_{\mathbf{X}}^{ij} SXij分别是对 y j i \mathbf{y}_j^i yji对 W \mathbf{W} W和 X \mathbf{X} X的灵敏度量度,出于实际考虑,将公式4转化为下式
S W i j = f ( W + Δ W , x j i ) − y j i , S x i j = f ( W , x j i + Δ x j i ) − y j i . (5) S_{\mathbf{W}}^{ij}=f(\mathbf{W}+\Delta\mathbf{W},\mathbf{x}_{j}^{i})-\mathbf{y}_{j}^{i}, \\S_{\mathbf{x}}^{ij}=f(\mathbf{W},\mathbf{x}_{j}^{i}+\Delta\mathbf{x}_{j}^{i})-\mathbf{y}_{j}^{i}.\tag{5} SWij=f(W+ΔW,xji)−yji,Sxij=f(W,xji+Δxji)−yji.(5)
这些量分别反映了 W \mathbf{W} W和 X \mathbf{X} X对 y y y的扰动,总结以上可得下式:
d y j i = S W i j + S x i j (6) d\mathbf{y}_j^i=S_\mathbf{W}^{ij}+S_\mathbf{x}^{ij}\tag{6} dyji=SWij+Sxij(6)
3.2 关键权重的识别
将数据集 i i i中第 j j j个输入向量上的损失函数定义为 d y j i d\mathbf{y}_j^i dyji的欧几里得范数的平方如下式
L j i = ∥ d y j i ∥ 2 2 . (7) \mathcal{L}_j^i=\left\|d\mathbf{y}_j^i\right\|_2^2.\tag{7} Lji= dyji 22.(7)
可以认为 L j i \mathcal{L}_j^i Lji越大,误差越大。将其与公式3联立得
L j i = ∥ ∂ f ∂ x j i d x j i + ∂ f ∂ W d W ∥ 2 2 . (8) \mathcal{L}_j^i=\left\|\frac{\partial f}{\partial\mathbf{x}_j^i}d\mathbf{x}_j^i+\frac{\partial f}{\partial\mathbf{W}}d\mathbf{W}\right\|_2^2.\tag{8} Lji= ∂xji∂fdxji+∂W∂fdW 22.(8)
为了确定使 d y d\mathcal{y} dy最小的 W \mathbf{W} W,使上式 L j i \mathcal{L}_j^i Lji计算对 d W d\mathbf{W} dW的梯度,得
∇ d W L j i = 2 d y j i ∂ f ∂ W . (9) \nabla_{d\mathbf{W}}\mathcal{L}_{j}^{i}=2d\mathbf{y}_{j}^{i}\frac{\partial f}{\partial\mathbf{W}}.\tag{9} ∇dWLji=2dyji∂W∂f.(9)
(证明略)通过 ∇ d W L j i \nabla_{d\mathbf{W}}\mathcal{L}_{j}^{i} ∇dWLji,可以得出输出灵敏度 d y j i d\mathcal{y}_{j}^{i} dyji的损失函数随权重灵敏度 d W d\mathbf{W} dW变化的关系。
这里引入 ∇ d W ′ L k \nabla_{d\mathbf{W}}^{\prime}\mathcal{L}^{k} ∇dW′Lk来得到 k k k个数据集的梯度的绝对值的和。这个量的绝对值大小对于理解损失函数对每个单独样本的敏感度很重要。通过关注这个量的大小,评估模型对 W W W和 x x x扰动的鲁棒性。 L k \mathcal{L}^{k} Lk是数据集 k k k的损失函数。
∇ d W ′ L k = ∑ i = 0 k ∑ j ∣ ∇ d W L j i ∣ = ∇ d W ′ L ~ k + ∇ d W ′ L k − 1 . (10) \begin{aligned} \nabla_{d\mathbf{W}}^{\prime}\mathcal{L}^{k}& =\sum_{i=0}^k\sum_j|\nabla_{d\mathbf{W}}\mathcal{L}_j^i| \\ &=\nabla_{d\mathbf{W}}^{\prime}\tilde{\mathcal L}^{k}+\nabla_{d\mathbf{W}}^{\prime}\mathcal{L}^{k-1}. \end{aligned}\tag{10} ∇dW′Lk=i=0∑kj∑∣∇dWLji∣=∇dW′L~k+∇dW′Lk−1.(10)
最后使用 L j i \mathcal{L}_j^{i} Lji沿 W \mathbf{W} W的方向导数 D \mathbf{D} D的大小来评估权重的重要性,方向导数 D \mathbf{D} D的大小用 W k ∗ \mathbf{W}_{k}^{*} Wk∗表示,公式表示为
W k ∗ = ∑ i = 0 : k ∑ j ∣ D W L j i ∣ = ∣ W ∣ ⋅ ∇ d W ′ L k = ∑ j ∣ W ⋅ ∇ d W L j k ∣ + W k − 1 ∗ (11) \begin{aligned}\mathbf{W}_{k}^{*}&=\sum_{i=0:k}\sum_{j}\left|D_{\mathbf{W}}\mathcal{L}_{j}^{i}\right|=|\mathbf{W}|\cdot\nabla_{d\mathbf{W}}^{\prime}\mathcal{L}^{k}\\&=\sum_{j}\left|\mathbf{W}\cdot\nabla_{d\mathbf{W}}\mathcal{L}_{j}^{k}\right|+\mathbf{W}_{k-1}^{*}\end{aligned}\tag{11} Wk∗=i=0:k∑j∑ DWLji =∣W∣⋅∇dW′Lk=j∑ W⋅∇dWLjk +Wk−1∗(11)
较高的 W k ∗ \mathbf{W}_{k}^{*} Wk∗值表明损失函数对沿 W \mathbf{W} W方向的权重的变化高度敏感,可以看出这些权重对模型的性能很重要。最终对 k k k个数据集的梯度的绝对值的和较小的权重进行剔除,就得到了剪枝后的模型。
COPAL1
reference
COPAL: Continual Pruning in Large Language Generative Models ↩︎