一、题目
定义一个 pipeline,并且将 earthquakes 索引的文档进行更新
- pipeline 的 ID 为 earthquakes_pipeline
- 将
magnitude_type的字段值改为大写 - 如果文档不包含
batch_number,增加这个字段,将数值设置为 1 - 如果已经包含
batch_number,字段值 + 1
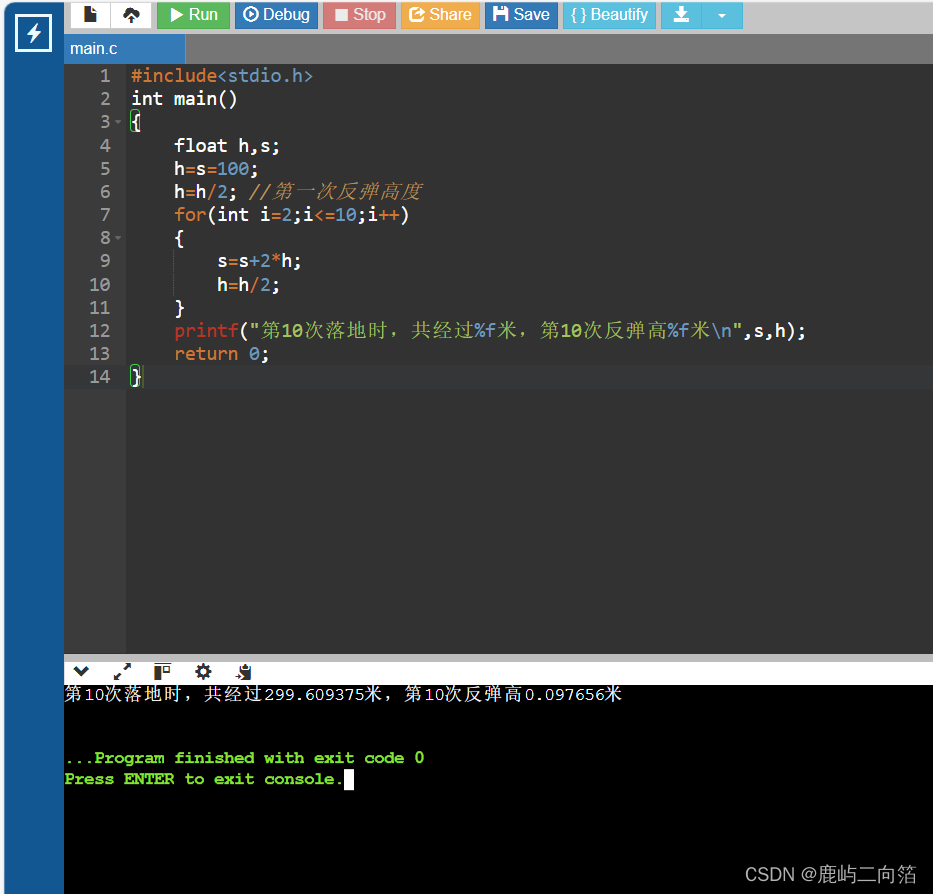
# 定义索引结构
PUT earthquakes
{"mappings": {"properties": {"name": {"type": "text"},"level": {"type": "integer"},"magnitude_type": {"type": "keyword"},"batch_number": {"type": "integer"}}}
}# 批量导入数据
POST earthquakes/_bulk
{"index":{}}
{"name":"111","level":1,"magnitude_type":"small","batch_number":22}
{"index":{}}
{"name":"222","level":2,"magnitude_type":"big"}
1.1 考点
- Ingest pipelines
- Update by query
1.2 答案
# 验证管道是否按照预期执行
POST _ingest/pipeline/_simulate
{"pipeline": {"processors": [{"script": {"lang": "painless","source": """ctx['batch_number'] = ctx['batch_number'] + 1;""","if": "ctx.batch_number != null"}},{"set": {"field": "batch_number","value": 1,"if": "ctx.batch_number == null"}},{"uppercase": {"field": "magnitude_type"}}]},"docs": [{"_source": {"magnitude_type":"small"}},{"_source": {"magnitude_type":"small","batch_number":22}}]
}# 保留一份原始数据,防止更新出错
POST _reindex
{"source": {"index": "earthquakes"},"dest": {"index": "earthquakes_bak"}
}# 定义管道
PUT _ingest/pipeline/earthquakes_pipeline
{"processors": [{"script": {"lang": "painless","source": """ctx['batch_number'] = ctx['batch_number'] + 1;""","if": "ctx.batch_number != null"}},{"set": {"field": "batch_number","value": 1,"if": "ctx.batch_number == null"}},{"uppercase": {"field": "magnitude_type"}}]
}# 批量更新数据
POST earthquakes/_update_by_query?pipeline=earthquakes_pipeline# 检查结果
GET earthquakes/_search

二、题目
为 task1 索引中的文档增加一个新的字段 new_field,字段值为 field_a + field_b + field_c
其实这里我有个问题:
field_a、field_b、field_c的值都是数字类型么,要是字符类型咋办field_a、field_b、field_c的类型不同咋整
2.1 考点
- Ingest pipelines
- Update by query
2.2 答案
field_a、field_b、field_c都是数字
# 创建索引结构
PUT task1
{"mappings":{"properties":{"field_a":{"type":"integer"},"field_b":{"type":"integer"},"field_c":{"type":"integer"}}}
}# 批量写入数据
POST task1/_bulk
{"index":{}}
{"field_a":1,"field_b":2,"field_c":3}
{"index":{}}
{"field_a":3,"field_b":2,"field_c":3}
{"index":{}}
{"field_a":5,"field_b":2,"field_c":3}# 验证管道的正确性
POST _ingest/pipeline/_simulate
{"pipeline": {"processors": [{"script": {"lang": "painless","source": """ctx['new_field'] = ctx['field_a'] + ctx['field_b'] + ctx['field_c']; """}}]},"docs": [{"_source": {"field_a":5,"field_b":2,"field_c":3}}]
}# 创建管道
PUT _ingest/pipeline/my_pipeline
{"processors": [{"script": {"lang": "painless","source": """ctx['new_field'] = ctx['field_a'] + ctx['field_b'] + ctx['field_c']; """}}]
}# 更新索引数据
POST task1/_update_by_query?pipeline=my_pipeline# 检查结果
GET task1/_search
field_a、field_b、field_c都是字符串,相同的管道就是字符串的拼接
# 创建索引结构
PUT task1
{"mappings":{"properties":{"field_a":{"type":"keyword"},"field_b":{"type":"keyword"},"field_c":{"type":"keyword"}}}
}# 批量写入数据
POST task1/_bulk
{"index":{}}
{"field_a":"a","field_b":"2","field_c":"c"}
{"index":{}}
{"field_a":"1","field_b":"2","field_c":"3"}
{"index":{}}
{"field_a":"d","field_b":"d","field_c":"hello"}# 验证管道的正确性
POST _ingest/pipeline/_simulate
{"pipeline": {"processors": [{"script": {"lang": "painless","source": """ctx['new_field'] = ctx['field_a'] + ctx['field_b'] + ctx['field_c']; """}}]},"docs": [{"_source": {"field_a":"a","field_b":"2","field_c":"c"}}]
}# 创建管道
PUT _ingest/pipeline/my_pipeline
{"processors": [{"script": {"lang": "painless","source": """ctx['new_field'] = ctx['field_a'] + ctx['field_b'] + ctx['field_c']; """}}]
}# 更新索引数据
POST task1/_update_by_query?pipeline=my_pipeline# 检查结果
GET task1/_search
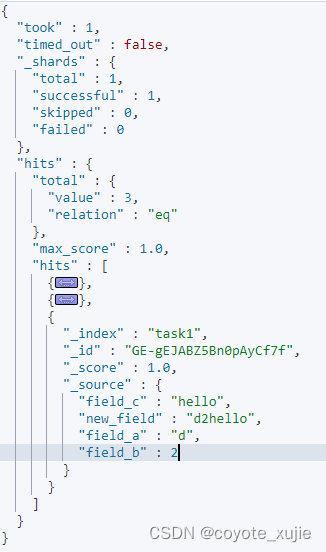
field_a、field_b、field_c是数字和字符串的混合,这里管道会统统当作字符串来处理,还挺有意思,和 java 一样。
# 创建索引结构
PUT task1
{"mappings":{"properties":{"field_a":{"type":"keyword"},"field_b":{"type":"keyword"},"field_c":{"type":"keyword"}}}
}# 批量写入数据
POST task1/_bulk
{"index":{}}
{"field_a":"a","field_b":2,"field_c":"c"}
{"index":{}}
{"field_a":"1","field_b":2,"field_c":"3"}
{"index":{}}
{"field_a":"d","field_b":2,"field_c":"hello"}# 验证管道的正确性
POST _ingest/pipeline/_simulate
{"pipeline": {"processors": [{"script": {"lang": "painless","source": """ctx['new_field'] = ctx['field_a'] + ctx['field_b'] + ctx['field_c']; """}}]},"docs": [{"_source": {"field_a":"1","field_b":2,"field_c":"3"}}]
}# 创建管道
PUT _ingest/pipeline/my_pipeline
{"processors": [{"script": {"lang": "painless","source": """ctx['new_field'] = ctx['field_a'] + ctx['field_b'] + ctx['field_c']; """}}]
}# 更新索引数据
POST task1/_update_by_query?pipeline=my_pipeline# 检查结果
GET task1/_search