初始爬虫
前言引入
随着大数据时代的来临,网络爬虫在互联网中的地位将越来越重要。互联网中的数据是海量的,如何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的。 我们感兴趣的信息分为不同的类型:如果只是做搜索引擎,那么感兴趣的信息就是互联网中尽可能多的高质量网页;如果要获取某一垂直领域的数据或者有明确的检索需求,那么感兴趣的信息就是根据我们的检索和需求所定位的这些信息,此时,需要过滤掉一些无用信息。前者我们称为通用网络爬虫,后者我们称为聚焦网络爬虫。
什么是爬虫?
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
-
简单一句话就是代替人去模拟浏览器进行网页操作。
为什么需要爬虫?
-
为其他程序提供数据源 如搜索引擎(百度、Google等)、数据分析、大数据等等。
企业获取数据的方式?
-
1.公司自有的数据
-
2.第三方平台购买的数据 (百度指数、数据堂)
-
3.爬虫爬取的数据
Python做爬虫的优势
-
PHP : 对多线程、异步支持不太好
-
Java : 代码量大,代码笨重
-
C/C++ : 代码量大,难以编写
-
Python : 支持模块多、代码简介、开发效率高 (scrapy框架)
爬虫的分类
爬虫的合法性
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被禁止,但是利用爬虫技术获取数据这一行为是具有违法甚至是犯罪的风险的。
http与https协议概念
1.什么是协议?
网络协议是计算机之间为了实现网络通信而达成的一种“约定”或者”规则“,有了这种”约定“,不同厂商的生产设备,以及不同操作系统组成的计算机之间,就可以实现通信。
2.HTTP协议是什么?
HTTP协议是超文本传输协议的缩写,英文是Hyper Text Transfer Protocol。它是从WEB服务器传输超文本标记语言(HTML)到本地浏览器的传送协议。 设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。 HTPP有多个版本,目前广泛使用的是HTTP/1.1版本。有些网站运用的是http/2.0版本。
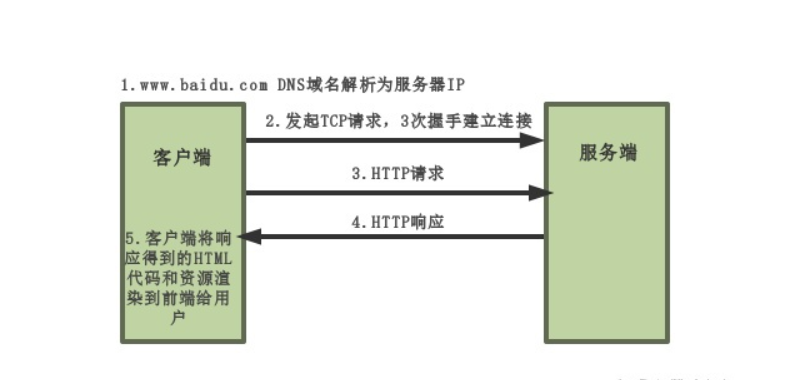
3.HTTP原理(了解)
HTTP是一个基于TCP/IP通信协议来传递数据的协议,传输的数据类型为HTML 文件,、图片文件, 查询结果等。 HTTP协议一般用于B/S架构(浏览器/服务器结构)。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。
4.HTTP特点(了解)
-
http协议支持客户端/服务端模式,也是一种请求/响应模式的协议。
-
简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。
-
灵活:HTTP允许传输任意类型的数据对象。传输的类型由Content-Type加以标记。
-
无连接:限制每次连接只处理一个请求。服务器处理完请求,并收到客户的应答后,即断开连接,但是却不利于客户端与服务器保持会话连接,为了弥补这种不足,产生了两项记录http状态的技术,一个叫做Cookie,一个叫做Session。
-
无状态:无状态是指协议对于事务处理没有记忆,后续处理需要前面的信息,则必须重传。