一、环境
win10
vs2022
cmake最新版
cuda 11.8
二、LibTorch下载
PyTorch![]() https://pytorch.org/
https://pytorch.org/
注意:我选择了preview版本。因为最新的MKL目前已经不兼容libtorch230了。
三、LibTorch使用
libtorch解压后如下图:
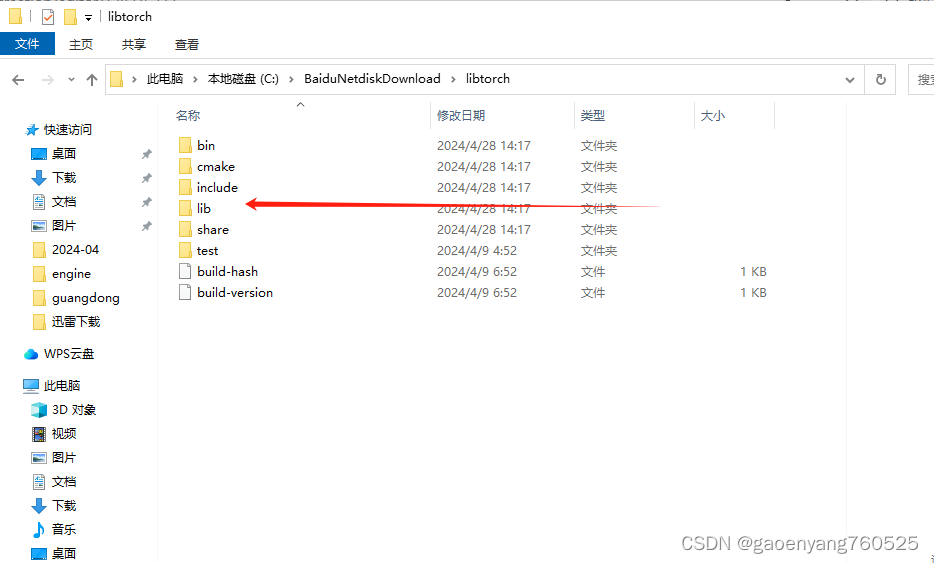
最核心的是include和lib这两个文件夹。
另外,我的CUDA路径如下图

1、include问题

2、lib问题
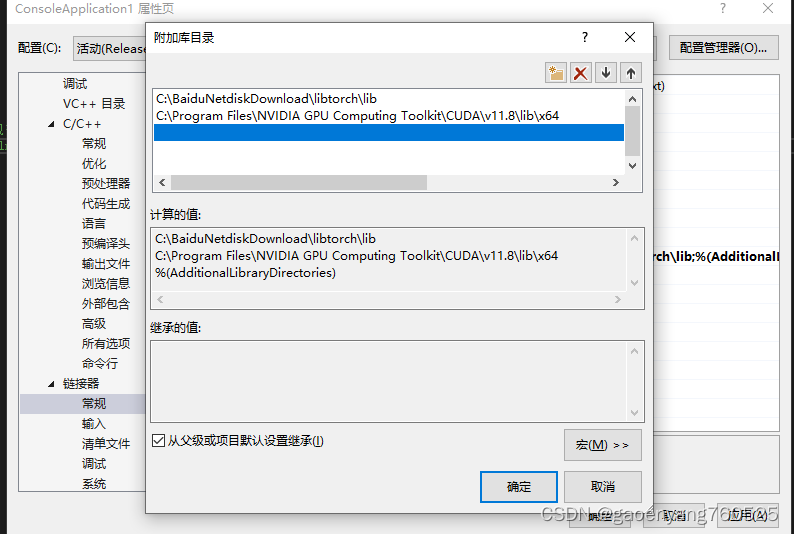
3、附加依赖项(我添加的不够多,你可在实践中继续添加)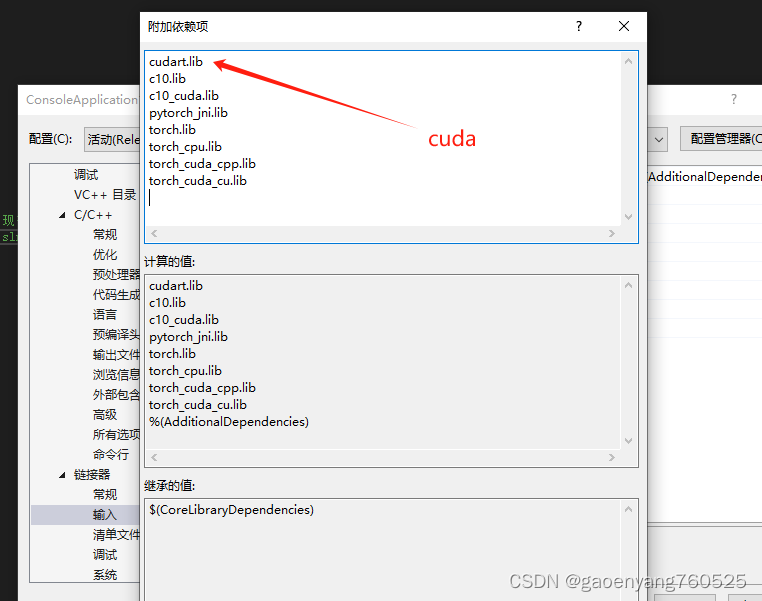
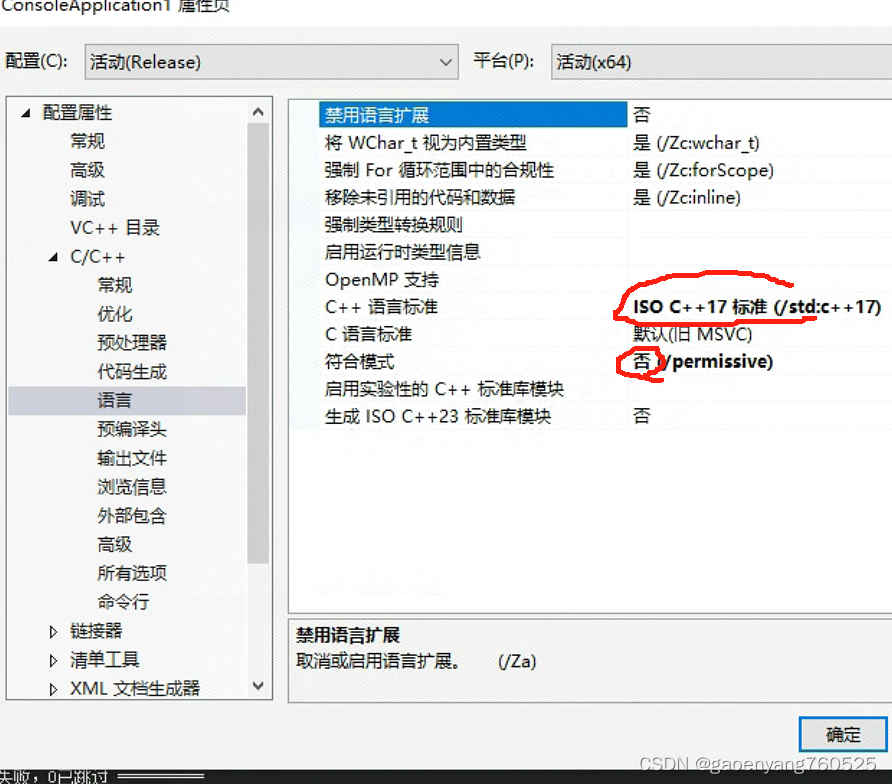
4、两项设置:
(1)把《符合模式》改为否;
(2)《c++语言标准》》改为17
5、添加系统变量
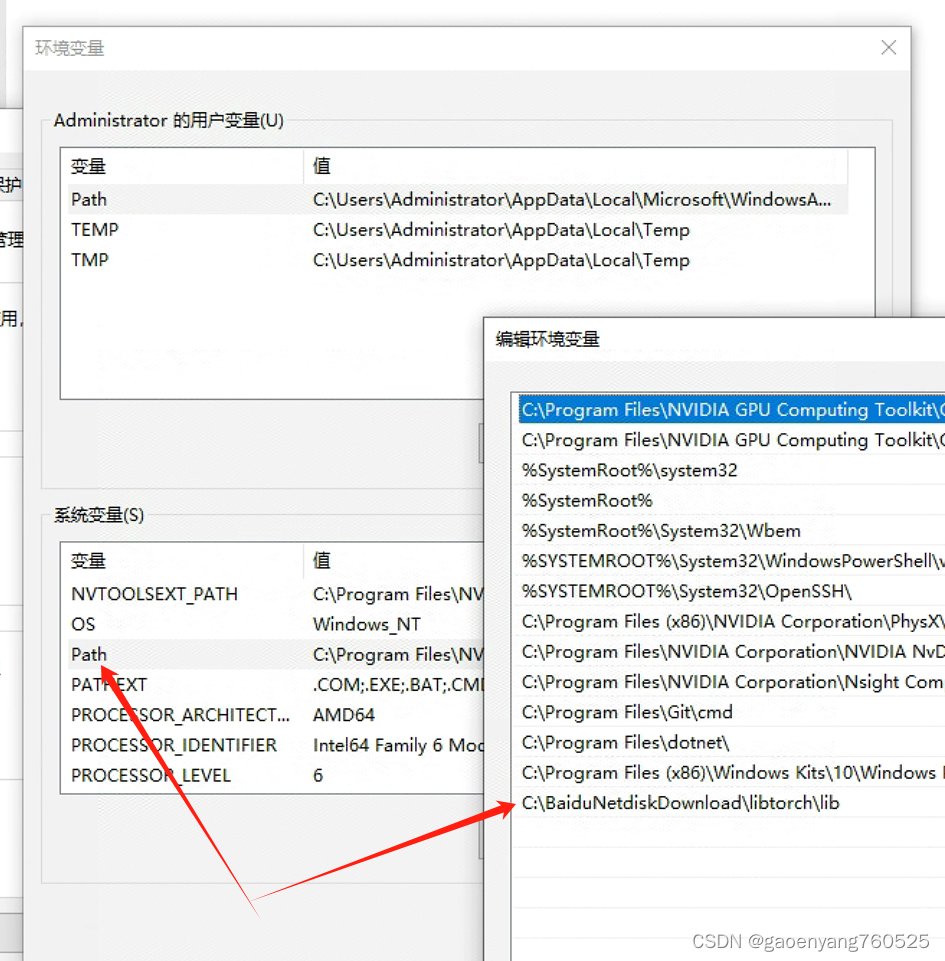
6、启用CUDA
/INCLUDE:?warp_size@cuda@at@@YAHXZ
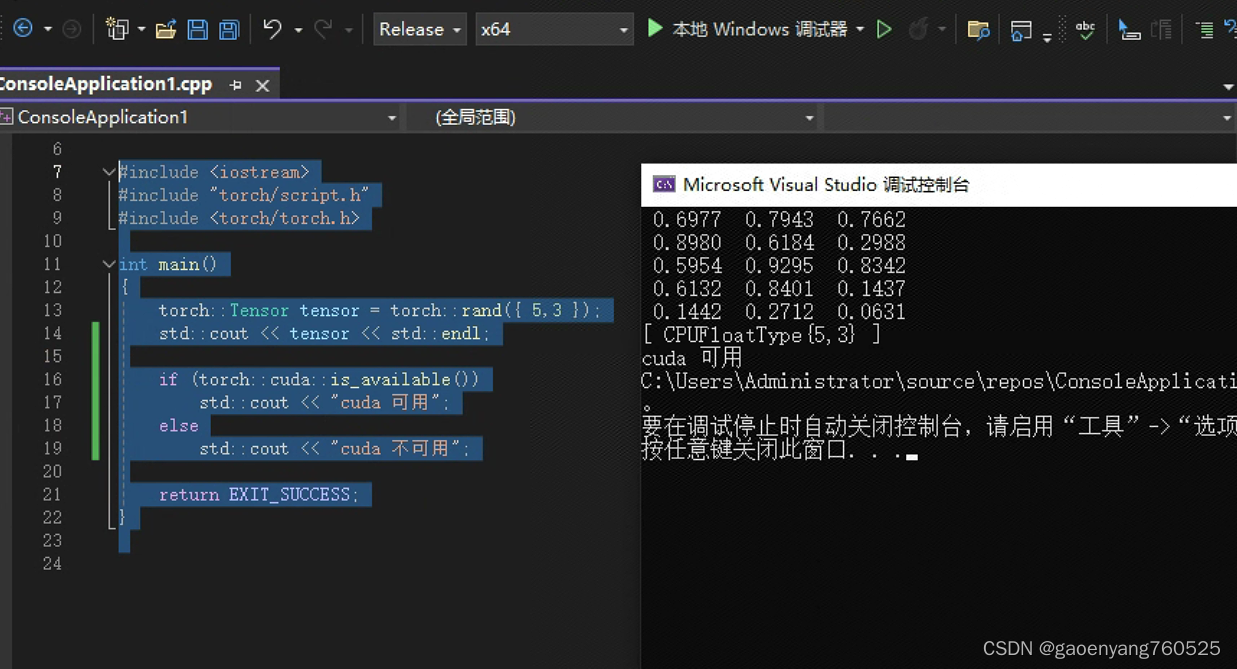
四、示例代码
#include <iostream>
#include "torch/script.h"
#include <torch/torch.h>int main()
{torch::Tensor tensor = torch::rand({ 5,3 });std::cout << tensor << std::endl;if (torch::cuda::is_available())std::cout << "cuda 可用";elsestd::cout << "cuda 不可用";return EXIT_SUCCESS;
} 
五、更复杂代码
// ConsoleApplication1.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//#include <iostream>
#include "torch/script.h"
#include <torch/torch.h>#include <torch/torch.h>#include <cstddef>
#include <cstdio>
#include <iostream>
#include <string>
#include <vector>#include<torch/torch.h>
#include<cstddef>
#include<iostream>
#include<vector>
#include<string>
// 继承自Module模块
struct Net : torch::nn::Module
{// 构造函数Net() :conv1(torch::nn::Conv2dOptions(1, 32, 3)), // kernel_size = 5conv2(torch::nn::Conv2dOptions(32, 64, 3)),fc1(9216, 128),fc2(128, 10){register_module("conv1", conv1);register_module("conv2", conv2);register_module("conv2_drop", conv2_drop);register_module("fc1", fc1);register_module("fc2", fc2);}// 成员函数:前向传播torch::Tensor forward(torch::Tensor x){// input:1*28*28x = torch::relu(conv1->forward(x)); //conv1:(28 - 3 + 1 = 26), 26*26*32// input:26*26*32x = torch::max_pool2d(torch::relu(conv2->forward(x)), 2);//conv2:(26 - 3 + 1 = 24),24*24*64; max_poolded:12*12*64 = 9216x = torch::dropout(x, 0.25, is_training());x = x.view({ -1, 9216 });// 9216*1// w:128*9216x = torch::relu(fc1->forward(x)); //fc1:w = 128*9216,w * x ->128*1x = torch::dropout(x, 0.5, is_training());// w:10*128x = fc2->forward(x);//fc2:w = 10*128,w * x -> 10*1x = torch::log_softmax(x, 1);return x;}// 模块成员torch::nn::Conv2d conv1;torch::nn::Conv2d conv2;torch::nn::Dropout2d conv2_drop;torch::nn::Linear fc1;torch::nn::Linear fc2;
};//train
template<typename DataLoader>
void train(size_t epoch, Net& model, torch::Device device, DataLoader& data_loader, torch::optim::Optimizer& optimizer, size_t dataset_size)
{//set "train" modemodel.train();size_t batch_idx = 0;for (auto& batch : data_loader){auto data = batch.data.to(device);auto targets = batch.target.to(device);optimizer.zero_grad();auto output = model.forward(data);auto loss = torch::nll_loss(output, targets);AT_ASSERT(!std::isnan(loss.template item<float>()));loss.backward();optimizer.step();// 每10个batch_size打印一次lossif (batch_idx++ % 10 == 0){std::printf("\rTrain Epoch: %ld [%5ld/%5ld] Loss: %.4f",epoch,batch_idx * batch.data.size(0),dataset_size,loss.template item<float>());}}
}template<typename DataLoader>
void test(Net& model, torch::Device device, DataLoader& data_loader, size_t dataset_size)
{torch::NoGradGuard no_grad;// set "test" modemodel.eval();double test_loss = 0;int32_t correct = 0;for (const auto& batch : data_loader){auto data = batch.data.to(device);auto targets = batch.target.to(device);auto output = model.forward(data);test_loss += torch::nll_loss(output, targets, /*weight=*/{}, torch::Reduction::Sum).template item<float>();auto pred = output.argmax(1);// eq = equal 判断prediction 是否等于labelcorrect += pred.eq(targets).sum().template item<int64_t>();}test_loss /= dataset_size;std::printf("\nTest set: Average loss: %.4f | Accuracy: %.3f\n",test_loss,static_cast<double>(correct) / dataset_size);
}int main()
{torch::manual_seed(1);torch::DeviceType device_type;if (torch::cuda::is_available()){std::cout << "CUDA available! Training on GPU." << std::endl;device_type = torch::kCUDA;}else{std::cout << "Training on CPU." << std::endl;device_type = torch::kCPU;}torch::Device device(device_type);Net model;model.to(device);// load train dataauto train_dataset = torch::data::datasets::MNIST("C://BaiduNetdiskDownload//SimpleNet-main").map(torch::data::transforms::Normalize<>(0.1307, 0.3081)).map(torch::data::transforms::Stack<>());const size_t train_dataset_size = train_dataset.size().value();std::cout << train_dataset_size << std::endl;auto train_loader = torch::data::make_data_loader<torch::data::samplers::SequentialSampler>(std::move(train_dataset), 64);// load test dataauto test_dataset = torch::data::datasets::MNIST("C://BaiduNetdiskDownload//SimpleNet-main", torch::data::datasets::MNIST::Mode::kTest).map(torch::data::transforms::Normalize<>(0.1307, 0.3081)).map(torch::data::transforms::Stack<>());const size_t test_dataset_size = test_dataset.size().value();auto test_loader =torch::data::make_data_loader(std::move(test_dataset), 1000);// optimizertorch::optim::SGD optimizer(model.parameters(), torch::optim::SGDOptions(0.01).momentum(0.5));//trainfor (size_t epoch = 0; epoch < 5; epoch++){train(epoch, model, device, *train_loader, optimizer, train_dataset_size);test(model, device, *test_loader, test_dataset_size);}// savereturn 1;
}