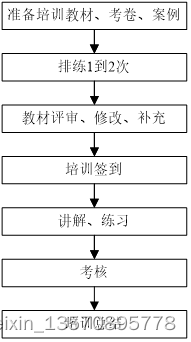
今天分享下在工作中的项目开发流程
1) Mysql hadoop hive oracle
hadoop: 实现海量数据的存储和计算
数据库: mysql Oracle
数据仓库: hive
2) 数据库和数据仓库都是将书库转为结构化数据处理(表数据)
联机事务处理 OLTP 数据库 面向事务进行数据处理 , 数据的增删改查
联机分析处理 OLAP 数据仓库 面向分析进行数据处理, 数据的存储和查询 一次写入多次读取
日常使用中,经常操作的是非结构化数据
文件(更多的是) 视频 音频 图片
文件数据转化为结构化数据
Kettle 读取文件数据存储到数据库,也可以将文件数据导入存储到数仓中
编程代码 Python
结构化数据的操作:使用 SQL structure query language 结构化查询语音
DDL 创建库表
DML 表数据的增删改
DQL 表数据的查询
DCL 权限管理
hive 在进行表数据操作时,是将表的数据拆成两部分操作
表数据包含
表的元数据 :表名 字段 字段类型 约束等 元数据就是对数据本身的描述
表行数据 hdfs 存储管理
MySQL 和 Oracle 是将表数据自己存储管理
3) 项目流程:
3-1 介绍
数仓形式: 离线数仓开发
线下到线上:
公司有线下的连锁商店,为了满足线上购物需求,开发了网站APP,小程序
在三方平台开设店铺
线下商店可以根据规模不同 进行商品批发或企业团购
线上到线下(京东,淘宝):
先有线上网站,引入新零售场景,开始发展线下,开设线下的实体商店以及自己的物流体系
3-4 开发需求介绍
销售需求
会员需求
供应链需求
商品需求
不同需求就是一个开发主题
需求开发完成后就会有新的需求产生
3-5 项目架构介绍
3-5-1
数仓分层架构
-- *** 数据是自上而下进行开发,上是尚有数据
-- 再导入数据时,直接将所有数据导入数仓,在根据需求从数仓中筛选数据进行计算
-- 该架构模式会造成数仓中存储大量无用数据
1. 用户数据
2. 订单数据
3. 商品数据
4. 业务需求
4-1. 计算用户总量
4-2 计算每天新增用户
4-3 计算每天存留用户量
4-4 月增用户
4-5 月留存用户量
5. 传统数仓架构,需求变化快
5-1 - 离线数仓架构
-- ***自下而上 先确认下游的计算需求,根据计算需求向上要计算的数据,将需要计算的数据导入数仓
-- 维度表 分组数据 (例如月 日 时间维度表 )
-- 事实表 计算内容作为事实表 (例如用户量 事实表)
1) 用户主题分析 用到时间维度表
2) 商品主题分析 用到时间维度表
每一个主题可能都用到时间维度表,但可能单位不同 有的是年月日 有的是时分秒 所以容易造成时间维度表的混乱 (命名很接
近) 所以采用 cif架构 将数仓架构划分为不同的层次以满足不同场景的需求, 比如 : ods dw dm 等 分层处理
5-2 技术架构
数仓架构描述的是数据处理流程
技术架构描述的是实现数仓用的技术组成
1) 数据源存储
1-1 MySQL
1-2 SQL Server
2) 数据导入 ETL
2-1 sqoop
2-2 datax
2-3 flume
2-4 kettle
3) 数据仓库
3-1 分布式存储 hdfs
3-2 分布式计算 mapreduce + hive
3-3 资源调度 yarn
4)数仓数据导出
4-2 datax
4-3 sqoop
4-4 kettle
5) 存储结果的数据库
5-1 mysql
5-2 sql server
5-3 oracle
6) 数据展示
6-1 fineBI
6-2 finereport
6-3 superset
6-4 powerBI