Abstract
单棵树 (IT) 分割对于森林管理、支持森林清查、生物量监测或树木竞争分析至关重要。光探测和测距 (LiDAR) 是这方面的一项突出技术,优于竞争技术。航空激光扫描 (ALS) 经常用于森林记录,在树顶表面显示良好的点密度。尽管使用多回波 ALS 可以收集树冠下数据,但多叶森林中靠近地面区域的点数急剧下降,因此,可能需要地面激光扫描仪 (TLS) 来获取有关的可靠信息树干或生长不足的特征。该方法基于体积的 DBSCAN 聚类和圆柱体素化,显示出对从点云中获得的树木位置的高检测率(90%∼),以及低的委托和提交错误(准确性超过93%)。该方法包括敏感性评估,以计算最佳输入参数并使工作流程适应真实世界的数据。这种方法表明,森林管理可以受益于 IT 细分,使用手持式 TLS 来提高数据收集效率。
Keywords: TLS; individual tree; segmentation; DBSCAN; clustering; forest inventory
1. Introduction
森林被认为是地球表面的生物群落之一,包括全球最多样的生态系统。自1990年以来,原始森林覆盖的面积急剧减少了8000多万公顷,而超过1亿公顷的其他地区受到野火、虫害、入侵物种和不利极端事件等问题的影响,导致生物多样性下降[1]。生物多样性保护需要基于指导方针的森林管理,包括维护和监测生态系统连通性、景观异质性和林分结构复杂性[2]。森林管理的关键要素包括保护保护区和生产区,考虑收获单位的空间和时间处理、火灾管理以及这些程序如何影响森林结构和物种组成[2,3]。此外,气候变化下的造林系统会对生产、生物多样性和抵御自然灾害产生影响,因此需要改进替代管理方案[2,4]。
在这种情况下,改善森林管理需要空间和时间监测系统,利用遥感数据收集及时的信息并降低成本[5]。独立树检测(ITC)是一个关键过程,它能够自动检测关键指标的变化,并支持采取措施将它们的潜在影响降至最低[6]。
为此,最常用的技术之一是激光扫描(LS),这是一种主动遥感技术,可测量观察者(如飞机或地面)与激光束照射的表面之间的距离[7,8]。这些系统所获得的多重优势导致机载激光扫描(ALS)在森林调查中的快速应用[9]。
然而,由于复杂的林冠模式(经常出现重大遗漏和错误),激光雷达技术提供的单个树木分割能力不足,因此激光扫描仍未充分应用于某些目的[10]。分割过程可以理解为基于数据中的统计相似性或相似特征对对象进行识别和分组的过程[11]。2D遥感数据中的分割从很早以前就开始使用[12],并且有许多基于像素、边缘、区域和图形识别的方法用于图像分析[13,14]。
此外,还有基于树冠估计的单棵树分割方法,这些方法是针对ALS[15–17]获得的3D激光雷达数据实施的。将这些方法应用于由地面激光扫描仪(TLS)收集的点云经常失败,因为在树冠顶部表面缺乏良好的点密度。遮挡效应仍然限制了提取森林属性的处理效率[18],使得难以识别树顶和其他有用的特征来获得适当的分割结果[19]。因此,分类方法强烈依赖于数据采集源[20]。
TLS数据树分段中的聚类方法已被广泛使用[21–24]。然而,此处介绍的方法显示了一种新的单棵树提取程序,该程序基于可应用于任何森林环境的圆柱体体素化的迭代DBSCAN聚类分析。该算法的基础依赖于树干识别;因此,在获取的点云中躯干越宽和分离得越多,分割的质量就越好。然而,在最后一节中,将对不同的输入参数进行敏感性研究,以开发此处介绍的方法的潜力。
这项工作的目标是基于使用背包移动系统收集的TLS数据的IT分段方法。本文组织如下:下一节说明了所使用的仪器设备、研究领域和分割算法的方法论,第三节报告了实验结果及其意义的讨论。最后一部分包括工作的主要结论以及未来的工作。
2. Materials and Methods
2.1. Instruments
在这项研究中,ZEB GO手持式激光扫描仪(见图1)用于数据采集。该系统的技术规格如表1所示。
ZEB-GO手持系统由2D激光扫描仪(波长为905纳米的1类激光器)和惯性测量单元(IMU)组成。这两个都安装在弹簧的顶部,弹簧本身安装在手柄上[25]。激光规格引用了≤30米的测量范围,但这不太可能在室外实现(由于环境太阳辐射)[18];仪器周围15-20米的测量范围更为现实[18,26]。扫描仪的手持部分(0.85千克)与背包中携带的数据记录器相连。当用户携带ZEB GO在环境中行走时,扫描头来回摆动,创建一个3D扫描场,以移动的速度捕捉数据。扫描仪是飞行时间(TOF)激光器,速率为43,000点/秒,视场水平为270度,垂直约为120度。没有收集关于返回信号强度的附加信息。
该系统包括一个背包系统,可以自动收集和记录难以通过标准GPS技术访问的数据,例如在地下洞穴[27,28]或室内建筑[29]。由于树冠下的森林被认为是GPS拒绝的区域,TLS基于IMU信息和Hokuyo系统收集的激光雷达数据来获得其位置和方向。同步定位和绘图(SLAM)方法支持森林的精确绘图。SLAM的概念是机器人可以被放置在未知的环境中,并有能力创建地图,然后导航到特定的目的地[30]。ZEB-GO重量轻(850 g)且不依赖GPS,这一事实使其成为难以接近区域的理想数据采集方法,例如树冠下和室内[30,31],如图1的右图所示。
当操作员穿过森林时产生的运动是测量技术的一个重要部分[32],因此根据[33]的结果,按照[18,32,33]中所做的那样,在研究区域的所有可能的树木之间进行行走测量路径,以最小化遮挡区域。
表1. [34]ZEB Go手持式激光扫描仪的技术规格。


图 1. 研究区域数据采集过程中使用的背负式激光雷达系统。
2.2. Study Area
该设备用于西班牙加利西亚O Xurés地区(8.1599714;41.9075281),如图2所示。它属于Baixa Limia-Serra do Xurés的自然公园,该公园被列为特别保护区(ASC) [35]。公园的植物区系以落叶林为特征,其中主要树种为槲栎、白桦、栓皮栎、杨桃、花楸和冬青,与一些特有植物共享空间,包括葡萄牙月桂和欧洲李树[35]。
2.3. Methodology
测量完成后,从TLS中获得该地块的原始点云。为了从该原始点云中获得IT位置,该方法包括如下四个步骤的序列:(I)基于手持TLS轨迹的异常值过滤,(ii)树干层减法,(iii)圆柱体体素化和聚类,以及(iv)浮动段的合并和噪声过滤。这个工作流程如图3所示。
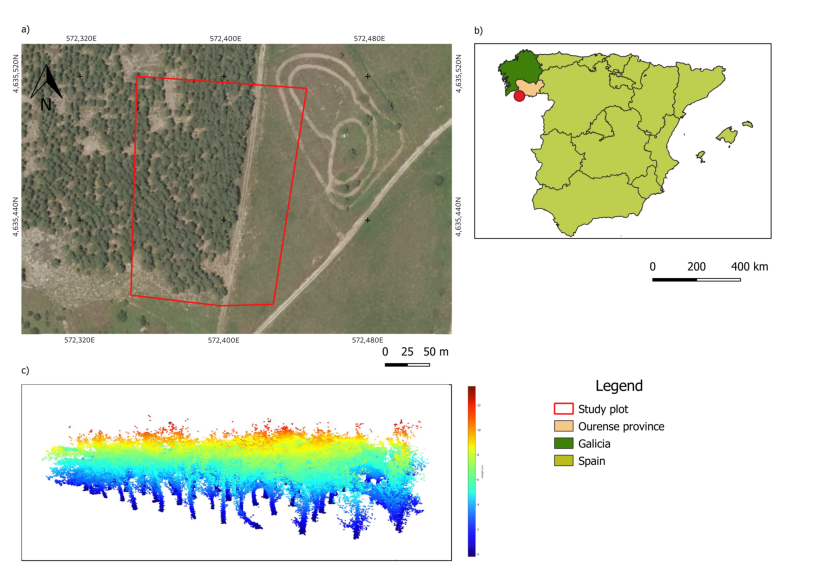
图 2. (a)该地块在研究区域的位置;(b)研究区在奥伦塞省的位置(西班牙);(c )收集的点云。
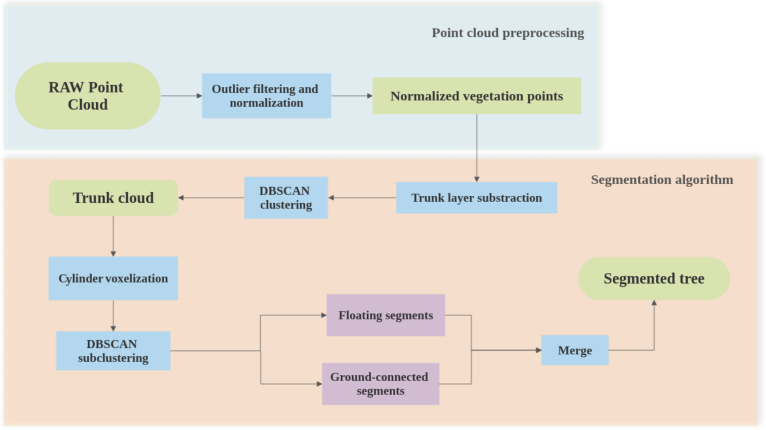
图 3. IT细分的工作流程。
2.3.1. Outlier Filter
异常值过滤器的主要目的是擦除原始点云中位于要考虑的图之外的那些点。这些点属于被认为是噪声的树枝、树干或灌木。
由于离群值是在LS范围的极限附近收集的(在我们的例子中,直径为30 m ),因此将TLS的轨迹作为参考,对原始点云应用直接门过滤器。从轨迹的凸包中导出一个多边形,过滤多边形外超过距离阈值的所有点(图4)。
在这种变换之后,所得到的点云相对于数字地形模型(DTM)被归一化。按照[36]中介绍的程序应用点云标准化。
使用对高度轮廓[37]的膨胀和腐蚀操作,应用形态滤波器来将地面点与非地面点分开。生成的地面点通过反距离加权(IDW)进行插值并网格化以获得DTM图层。最后,使用DTM图层,对点高度进行归一化。
图 5 显示了原始点云和异常值过滤和高度归一化后的归一化点云。
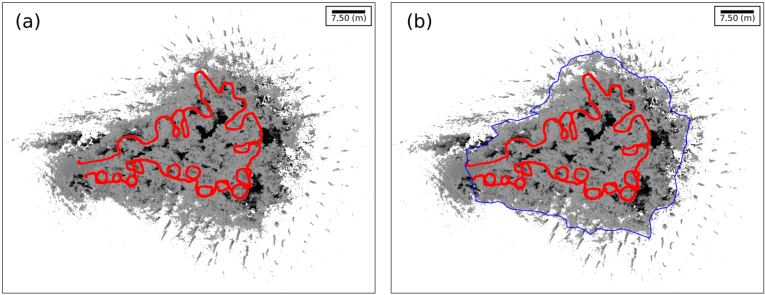
图 4. (a) 带有红色标记轨迹的完整原始点云。 (b) 从轨迹的蓝色凸包重建多边形。
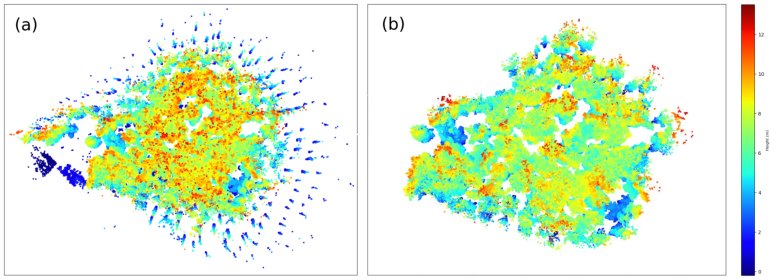
图 5. (a) 原始点云。 (b) 原始点云的异常值去除。
2.3.2. Trunk Layer Subtraction
归一化后的点云包括灌木、树干、树冠等植被点。此方法中单个树木检测的第一步包括在特定高度创建一个虚拟水平层,该水平层被标记为树干层。定义该层后,我们将属于该层的那些点标记为树干点,如图 6 所示。根据树干层的高度,可能会有灌木或低树冠点被错误标记为树干点。
为了将这些点过滤为主干候选,基于DBSCAN算法对主干点进行聚类分析[17]。主干层聚类分析的相应结果如图7所示。
DBSCAN聚类分析由三个输入参数定义:整个点云集合、点邻近半径ϵ\epsilonϵ和每个聚类的最小点数NminN_{\min }Nmin。在算法的这一步中,我们将ϵtrunk \epsilon_{\text {trunk }}ϵtrunk 定义为用于树干集群标识的DBSCAN半径。如下节所述,进行参数的敏感性评估,以获得点云的DBSCAN聚类分析的最佳参数。
在聚类之后,我们最终计算XY平面中每个I树干的质心,从而获得树位置的估计。为此,如图8所示,我们为主干簇中的所有nnn个点设置相同的统计权重,并计算其质心,如下所示:
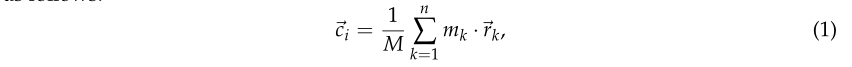
其中r⃗k≡r⃗k(x,y)\vec{r}_k \equiv \vec{r}_k(x, y)rk≡rk(x,y)代表kkk点在XY平面上的坐标。
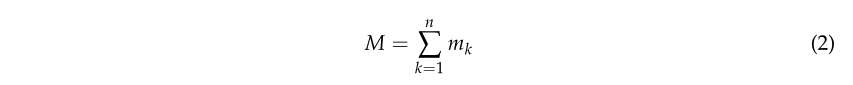
是簇的总质量。因此,我们有一个连续的质量分布,质心与总体积的几何中心相同[38]。

图 6. 点云的部分屏幕截图,树干簇候选以红色显示。
然而,在两个接近的树干的情况下,如果所使用的ϵtrunk \epsilon_{\text {trunk }}ϵtrunk 足够大,则两个树干被认为只有一个,导致错误的树识别。这个例子可以在图8b中看到,其中两个主干很接近,DBSCAN集群将它们合并到一个集群中。这种现象是算法开发过程中遗漏误差(EOME_{O M}EOM)的主要原因;最后几节对这一事实进行了讨论。
此外,ZEB-GO 切片的点似乎在茎的内部和外部,树干周围的点密度遵循高斯形状,模型位于横截面的轮廓中 [18](图 8)。这是进行适当的噪声过滤时需要考虑的一个重要因素。
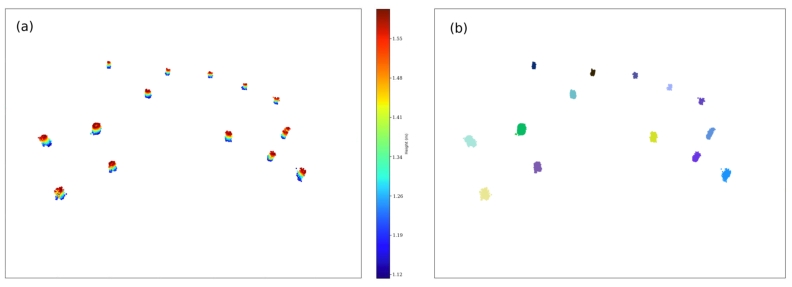
图 7. (a) 干线层减法。 (b) 通过 DBSCAN 进行个体中继识别。
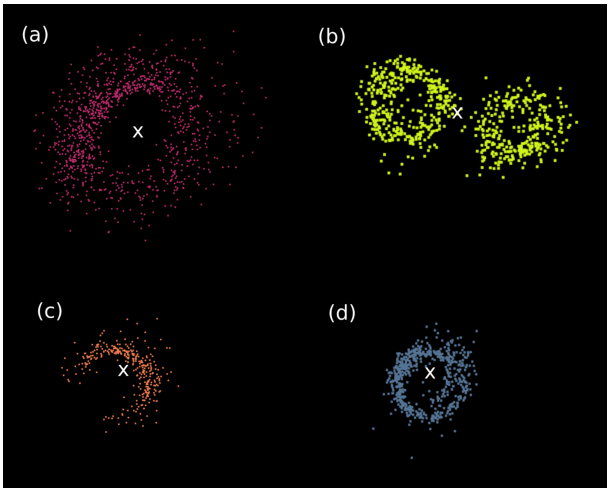
图 8. (a–d) 一些树干簇的横截面,其重心标记为白色十字。
2.3.3. Cylinder Voxelization
圆柱体素化支持属于同一棵树的簇中的点云的分割。
一旦获得树干质心估计(即树位置),就可以导出每个树干的最近邻居。树干与其最近邻居之间的距离定义为要分析以进行分割的圆柱体的候选半径。
以树干质心为圆心,计算出具有候选半径的无限圆柱体。该圆柱内的所有点相应地标记为圆柱点并分割为CiC_iCi点云。对于每个圆柱点云CiC_iCi,执行新的 DBSCAN 聚类分析。在该DBSCAN过程中,类似于主干层减法步骤,我们将邻居DBSCAN半径定义为圆柱,并且为了拒绝周围树冠的点,它的低值是期望的(优选地,具有一些小尺寸的簇,而不是只有一个大簇,因为下一步包括合并所有的子簇,遵循在圆柱体素化中不是所有的子簇都属于同一棵树的约束)。结果,很可能在CiC_iCi中的候选圆柱点内获得jjj个子集群CijC_i^jCij的过度分割,而不是只有一个子集群。图 9 中可以看到圆柱点云及其 DBSCAN 子聚类的示例,其中设置了较小的ϵcylinder\epsilon_{c y l i n d e r}ϵcylinder值,以便在一个圆柱体素化中包含多个子聚类。
这是一个迭代过程,为了节省计算资源,所有候选柱面点都被过滤掉,不在下一次迭代中考虑。当没有待标记的树干时,该过程停止。不属于任何圆柱体的点在圆柱体素化中被标记为废弃点。
2.3.4. Merging the Floating Segments and Noise Filtering
在圆柱体素化和子聚类之后,预计会有两种类型的聚类:地面连接和浮动部分,如图 9 的右面板所示。为了标记子聚类,通过比较它们在不同高度的点密度来评估垂直连续性。在检测到地面和候选子集群 CijC_i^jCij 之间存在不连续性的情况下,候选子集群被标记为浮动段。否则,候选子集群被标记为接地。
对于获取的航空 LiDAR 数据,这会导致性能不正确,因为树冠下的点密度较低,显示树干点很少。然而,在我们的案例中,由于该算法是为地面 LiDAR 开发的,因此完全避免了这个问题,对于一棵真正的树,总会有至少一个非常靠近地面的部分被认为是接地的。
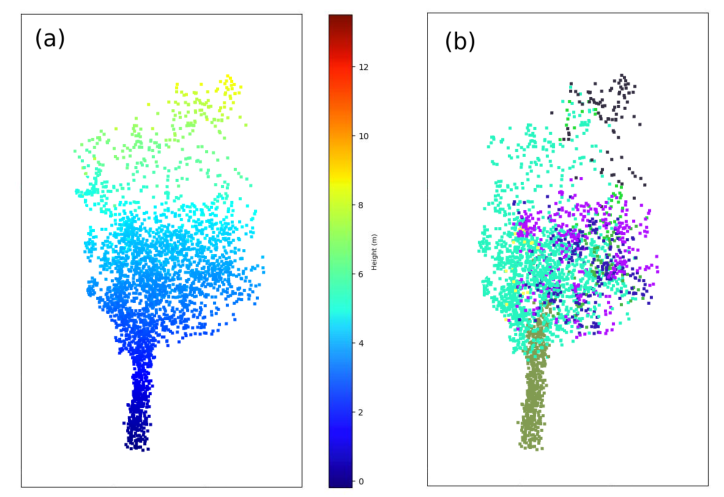
图 9.(a) 减去圆柱云。 (b) 圆柱点云的子聚类。
一旦所有子集群都被分类,合并浮动段包括将它们分配给最近的接地段。在图 10 中,有一个此过程前后点云状态的示例。在左侧面板中,有一些点组似乎与其对应的树不匹配,即浮动线段,因此在通过评估其垂直连续性来识别它们之后,将它们与最近的地面连接线段合并。在对所有圆柱点云重复此过程后,将剩下一组尚未进行任何分类的点。我们称它们为丢弃点,它们的分析将是算法过程的最后一步。
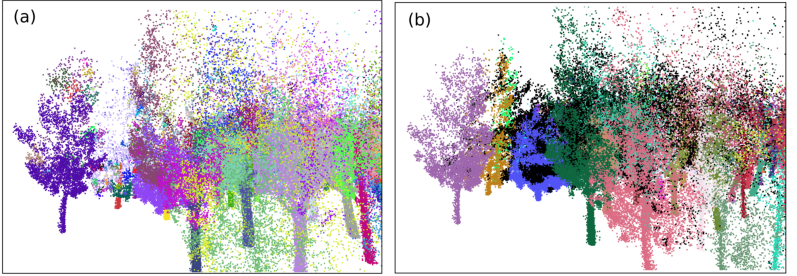
图 10. 此阶段点云的屏幕截图。 (a) 整个点集分为浮动和地面连接的簇。 (b) 按照本工作中解释的逻辑合并所有段(黑点表示在圆柱体素化过程中丢弃的所有点,并将在最后一步中正确分配给每个段)。
最后,研究了柱面体素化中的丢弃点。在树干层减法步骤中,通过提供所有树的位置的DBSCAN聚类来识别所有树干,然后,对于每个iii树干(具有重心ci(x,y)c_i(x, y)ci(x,y)),搜索阈值内最近的j树干簇(具有重心cj(x,y)c_j(x, y)cj(x,y))。一旦找到jjj树干,就制作一个以ci(x,y)c_i(x, y)ci(x,y)为中心的半径为dij=∣ci−cj∣d_{i j}=\left|c_i-c_j\right|dij=∣ci−cj∣的圆柱体,并存储位于该圆柱体中的整个点云集合CCC的所有点,从而创建圆柱体体素化CiC_{i}Ci集合。
迭代所有I个主干位置,我们知道标记的点由以下内容组成:
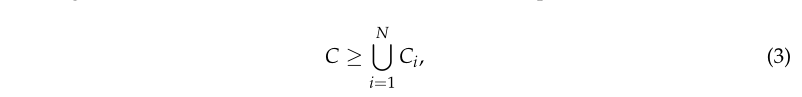
其中N是被识别的总片段数。然而,整个点云集合C可能大于所有CiC_iCi单个树集合的并集,因为在体素化步骤期间丢弃了一些点。如图11所示,即使一些点还没有关联,因此不属于任何圆柱体体素化,红色圆柱体联合也只与靠近其原始树的点重叠。如果我们将丢弃点定义为C∗C^*C∗,则可以得到如下结果:
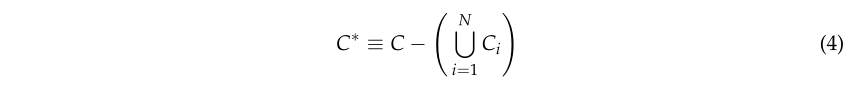
因此,丢弃的点是那些在所有圆柱的并集之外的点。这些点被过滤,并且如果它们到最近的片段集CiC_iCi的距离低于阈值距离d∗d^*d∗,则它们被添加到该片段,否则被丢弃。
在该过程结束时,根据所选择的d∗d^*d∗,没有被添加到任何片段集CiC_iCi的所有点都与噪声集N相关联。如果使用小的阈值噪声距离d∗d^*d∗,则噪声集N大于选择较大d∗d^*d∗的情况。该参数d∗d^*d∗因每片森林而异,因为它与树木的接近程度有关,因此为其建立最佳值对于所获得的每一个数据都是不同的。在第3.2节中,进行了敏感性评估,并示出了如何提高分割算法行为的良好性。
图 11. (a,b)点云的一些手动减去的树的两个视点。(c,d)体素化内部所有点的圆柱包络。在工作流程的最后一步中,将分析不在任何圆柱体内并因此在体素化中被丢弃的所有点。
2.4. Validation
验证包括定义和应用指标以获得方法的性能。文献中关于ALS处理的指标[10,39–42]不适用于我们的方法,因为TLS的观点不同。具体来说,在我们的例子中,树顶或最大树冠宽度不是感兴趣的参数。为了测量分割的性能,我们基于以下迭代过程将分割视为真阳性(TP)、假阴性(FN)和假阳性(FP)。
首先,我们手动减去处理过的点云中的所有树,对于每个手动分割的树,按照与第2.3.2节相同的逻辑计算其在XY平面中的树干的质心。这些质心被认为是每个真实的树位置。一旦所有真实的树都被识别,迭代验证过程就开始了。
对于每个手动减去的树,搜索最近的树,并且它们之间的距离被定义为dmind_{\min }dmin。该距离被计算为对应点之间所有距离的平均值,从而获得聚类接近度的估计。然后,我们从算法中搜索距离dmind_{\min }dmin内最近的分段树(从现在起,它将被称为算法树)。如果任何算法树不在该半径内,则该真实树是假阴性(FN ),并且在进一步的迭代中不被考虑。
在半径dmind_{\min }dmin内至少有一个算法树的情况下,它所具有的点数将被概括为N∗N^*N∗。此外,迭代的实树的点数及其最接近的手动减去的点数分别被定义为N1N_1N1和N2N_2N2。
然后,下一个比较过程开始:
-
如果N∗>N1N^*>N_1N∗>N1 且N∗≥N1+N2N^* \geq N_1+N_2N∗≥N1+N2:
算法树与两个真实树(或更多)重叠,因此被认为是误报(FP ),不再考虑。 -
如果N∗>N1N^*>N_1N∗>N1 且N∗<N1+N2N^*<N_1+N_2N∗<N1+N2:
算法树与真实的树一致,并且包含一些比它应该包含的更多的点,所以它被认为是真阳性(TP ),并且将不再被考虑。 -
如果N∗≤N1N^* \leq N_1N∗≤N1:
算法树与真实树一致,但两者相比可能不完整。换句话说,算法树的大部分点被真正识别,但是真实的树仍然具有更多与其他算法树相关联的点,因此它被认为是真阳性(TP ),并且将不再被考虑。
示意性地,验证过程遵循图12所示的方案。应用这一度量,我们定义了以下置信估计量[40]:
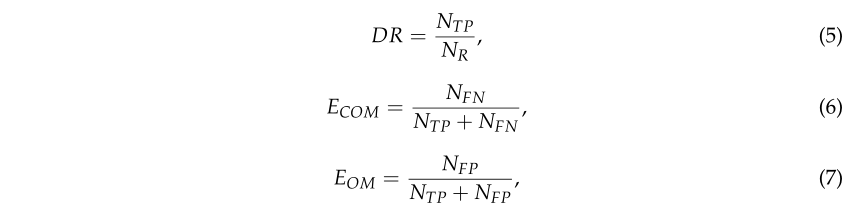
其中DR,ECOMD R, E_{C O M}DR,ECOM 和 EOME_{O M}EOM分别是检出率、委托误差和遗漏误差。另外,NTPN_{T P}NTP是真正检测到的树数(TP),NRN_RNR是真实的人工减去树数,NFNN_{F N}NFN是被分类为假阴性(FN)的树数,NFPN_{F P}NFP是被分类为假阳性的树数(计划生育)。
当一棵真正的树在应该检测到的时候没有真正检测到时,就会发生遗漏错误。另一方面,佣金错误则相反;当一个算法段被归类为一棵真正的树时,它们就会出现,而它不应该被归类为一棵真正的树。如第 2.3.2 节所述,对每个树干进行良好的识别,然后对每棵真实的树进行良好的识别,可以最大限度地减少遗漏错误。浮动段合并步骤是最小化委托误差的一个很好的过程,因为大多数可以被识别为真实树的浮动段与最近的地面连接树组合(这将是一棵真实的树,因为它有树干) , 这个事实导致了一个小的佣金错误。
综上所述,DBSCAN 参数,如 etrunk 和 eclinyl 以及噪声过滤的阈值距离 d* 是最重要的因素,因为算法的性能在很大程度上取决于它们,建立这些因素的可靠参考将有助于最大限度地减少遗漏和委托错误并最大化检测率,这将在下一节的敏感性评估中显示。

图 12. 验证期间使用的迭代过程。
3. Results and Discussions
3.1. Segmentation of Backpack Point Clouds
如前所述,研究区域位于 O Xurés(西班牙加利西亚),点云由约 300 万个点组成。我们在 Python 脚本 [43] 中实施了该方法,并使用 Open3D 库进行 3D 数据处理 [44],以提取具有定性和定量良好结果的 IT。与 [24,45-47] 中的其他类似方法相比,该程序的处理时间对于获取的点云是及时一致的(在 3-8 分钟的范围内),其中时间约为 2天,分别为 6.22 分钟、4 分钟和 4.78 分钟。此外,可以通过改变给定的输入参数来改进这项工作的处理时间。图 13–15 中显示了一些示例。

图 13. 分割点云的缩放屏幕截图。

图 14。整个点云分割的正交视图(以米为单位的几何比例)。
图 15. 分割点云的缩放屏幕截图。
3.2. Validation and Sensibility Assessment
为了验证该算法,我们选择了 O Xurés 的点云之一并对其进行了手动分割。这对于测试有效识别了多少棵树很重要。手动分割点云后,通过遍历所有手动分割并计算每个树干开始处的点的质心来定位每个树的位置。分割树的位置根据方法中解释的指标进行评估,将每棵树标记为 TP 、 FP 或 FN 。当一个段被认为是 TP 时,我们将其标记为匹配树,如图 16 的左面板所示。此外,图 16 的右面板显示了每个段与其实际树的偏差的散点图16,显示识别过程中的低错误。也有一些位置误差超过 1 m 的匹配树,但这是因为当某些段与最近的树的部分重叠时,它们被认为是 TP,从而创建远离其真实位置的树干质心。这棵树被视为 TP,因为它被有效地检测到,但减去的树位置有助于在图 16 的图 (b) 中产生散点误差。
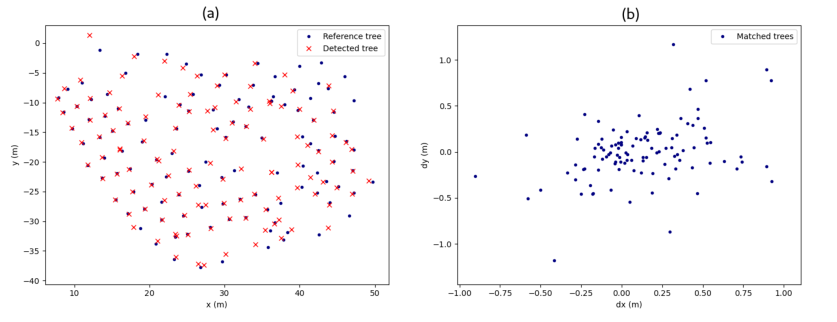
图 16. (a) 每棵减去树与其参考树之间的比较。 (b) 定位精度图。
等式(3)-(5)有助于实现分割算法的最佳输入参数。这些输入参数是在算法开发过程中使用的参数:树干识别的 DBSCAN 半径 (etrunk)、每个圆柱体素化内部使用的 DBSCAN 半径 (ecylumin) 以及在圆柱体素化步骤中过滤所有丢弃点的阈值噪声距离 (d *)。
如前所述,DBSCAN 约束和阈值噪声距离取决于案例研究,但由敏感性分析得出的建议估计量支持最佳参数的设置,如图 17 所示。
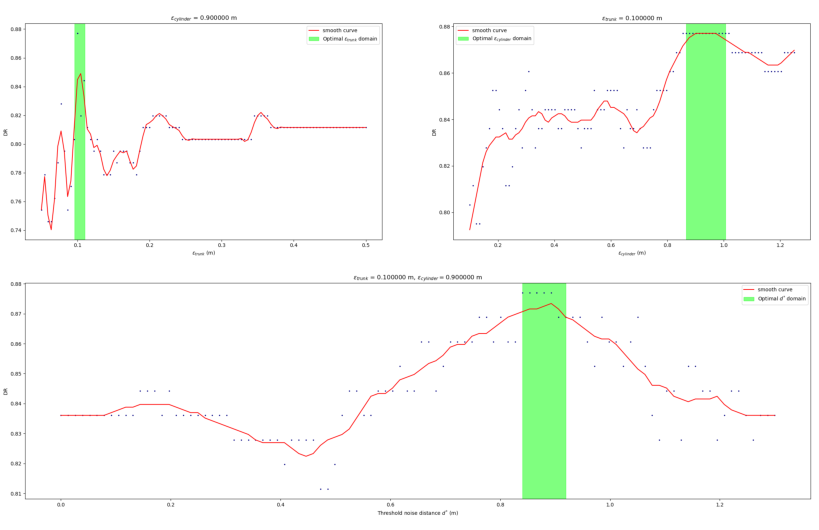
图 17. 不同输入参数的敏感性分析。
在研究区域中,etrunk(图 17 中的左上面板)显示出比其他输入参数对微小变化更敏感。我们将 etrunk 的最佳值设置为 0.1 m,因为它是该场景的最佳检测率。然而,我们将 etrunk 的最大限制设置为 0.5 m,因为更大的值对于我们研究区域的树干聚类分析是不现实的。
在其他情况下,对于 etrunk = 0.1 m,我们可以确定 ecilinder = [0.8, 1.0] m 的最佳窗口和 0.87 m 的阈值噪声距离。
对于 etrunks = 0.1 m、eccylinder = 0.9 m 和阈值噪声距离为 0.87 m 的输入参数,获得的最佳检测率为 86.885%(ECOM = 13.114% 和 EOM = 10.924%)。
一般来说,UA V LiDAR 点云中的森林分割算法在它们之间具有相似的检测率,从 26% 到 96% 不等(取决于所获取数据的方法和类型)[15]。例如,Sperclich 等人 [48] 对从 UA V 数据创建的摄影测量点云进行的个体树木检测进行了测试,他们实现了接近 90% 的 DR。其他类似的方法也被应用,如 [49],其中茎半径的距离自适应搜索方法的总体检测率为 76.1%,或者在 [22] 中,应用单扫描 TLS 以检测茎中的茎密集且均匀的森林,检测率为 88%。
在我们的方法中检测到的主要不便是对树干的敏感性,如图 17 左上面板所示。当两个或多个树干足够接近时,圆柱体素化假定落在圆柱内的所有树干都是一棵独特的树。如果研究区域的树干非常紧密 (O ∼ cm),则可能会发生这种情况。然而,这种情况具有挑战性,即使对于人类从业者也是如此。
另一个例子是树冠分割任务:如果有不止一棵树附近有树冠,将很难识别哪些点属于每棵树。这两种情况如图 18 所示。
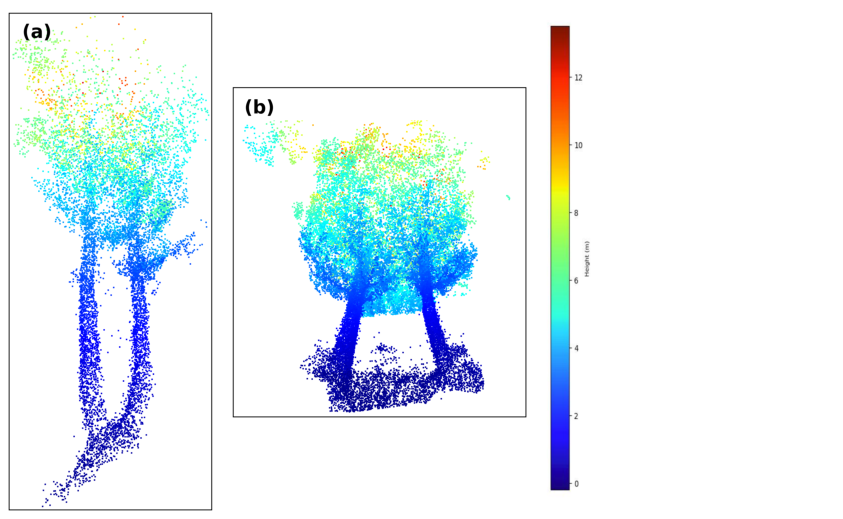
图 18. 硬人类分类树的示例。 (a) 可以解释为一两棵树的闭合树干。 (b) 附近有树冠的两棵树。
4. Conclusions
由于飞行器遵循的路径的可行性,机载激光扫描 (ALS) 的森林清查得到了快速应用。然而,对于这些仪器飞行困难的地方,激光扫描可能是一项艰巨的任务,在遮挡足够大的区域会导致信息不足。在文献中,地面激光扫描 (TLS) 显示可用于访问树冠下区域,但树冠表面的点密度较低。
考虑到 ALS 和 TLS 数据中的这些事实,开发了一些计算方法以提取森林特征,例如单个树的形状或树的位置。尽管如此,几乎所有方法都是针对特定类型的测量源设计的,这使得某些算法可以更好地处理空中或地面 LiDAR 数据。
这项工作的目的包括从西班牙加利西亚 O Xurés 的西班牙地区的背包 TLS 获得的原始点云中分割单棵树 (IT)。为此,设计并成功应用了一种分割算法,检测率很高。
所提出的方法需要一个标准化的点云作为输入数据,并提供相同的点云,其所有点都标有它们所属的 IT。如上一节所示,所获得的结果足以表明该技术可用于森林清查任务,实现了接近 90% 的检测率和较低的佣金和遗漏错误。
对于研究区域,研究了 DBSCAN 参数和阈值距离的变化,以尽量减少遗漏和委托误差。提高检测率的一种方法是实施卷积神经网络 (CNN)。使用背包 LiDAR 数据的各个树段训练此 CNN 将导致更复杂的模型,这可能会减少计算演算时间。此外,该网络可以通过数据增强创建人造树点云来帮助生成数据集。
尽管存在验证评估中提到的障碍,但开发的算法在林下植被和完全野生的自然环境中显示出良好的结果,这是IT级森林管理的基础。
论文链接
References





![基础算法[四]之图的那些事儿](https://img-blog.csdnimg.cn/485dba8af63d4f1da3bc430c88497283.png)