最近有位做医疗项目的同学咨询有一批人员的身高、体重、性别、年龄、心电图、是否有心脏病等数据是否可以根据这些数据预测某个人是否有心脏病的迹象。这当然是可以的,AI机器学习不就是干这事的吗?这是一个典型的分类算法。根据这些人体特征来判断是否存在潜在的疾病。问题是如何对心电图进行特征提取,提取出相关的特征,让模型进行学习和训练。
拿到数据后,第一步,我们首先来看一下数据。
一、数据探索
1、读入数据
导入numpy、pandas、matplotlib三大件,读入数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv('data_csv.csv')
df
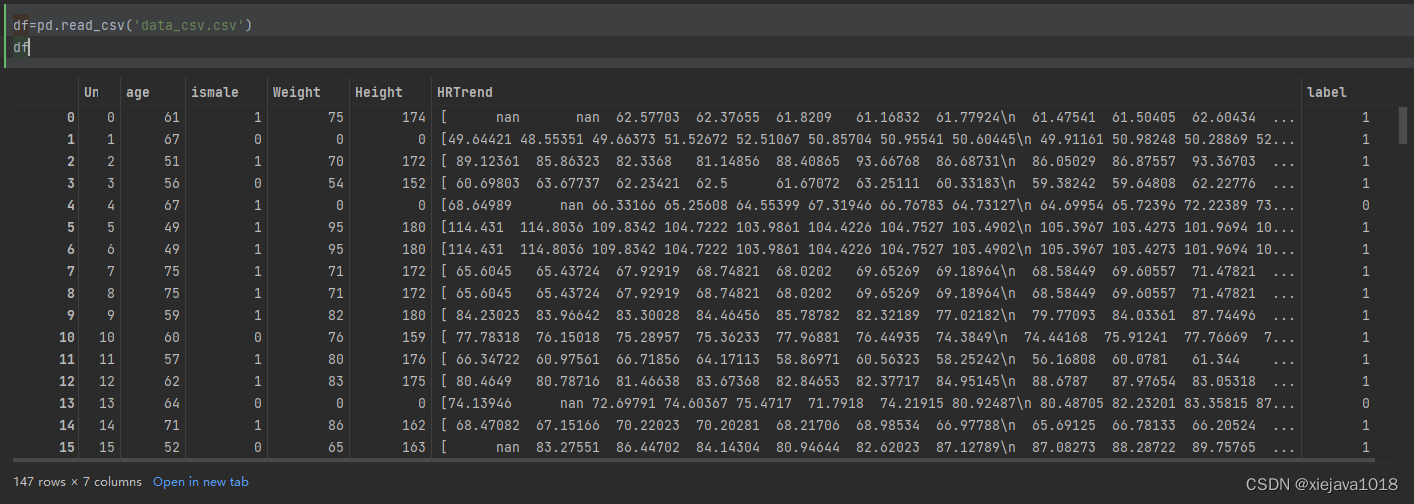
数据集中有age年龄、ismale性别、Weight身高、Height体重、HRTrend心电图、label是否有心脏病(1,是有心脏病、0是无心脏病)
这里看到主要的几个关键性的指标。HRTrend是csv中载入的时候数据是文本字符串格式,还有nan及\n等字符串,我们要将这些数据进行清洗规则化,将其转化为数组。
2、数据处理
先拿一个样本数据来看看数据的情况。对它进行相应的处理,包括去掉回车换行符、去多余空格、然后以空格作为分隔形成数组。
HRTrend_Data=df['HRTrend'][1][1:len(df['HRTrend'][1])-1]
HRTrend_Data=HRTrend_Data.replace('\n','') #替换掉换行符
HRTrend_Data=HRTrend_Data.replace('nan',str(0)) #将nan补0
HRTrend_Data=re.sub(' +', ' ', HRTrend_Data).strip() #去掉多余的空格
HRTrend_Data=np.asarray([float(s) for s in HRTrend_Data.split(' ')]) #将字符串通过空格分隔,转换成数组
pd.DataFrame(HRTrend_Data).plot()
HRTrend_Data
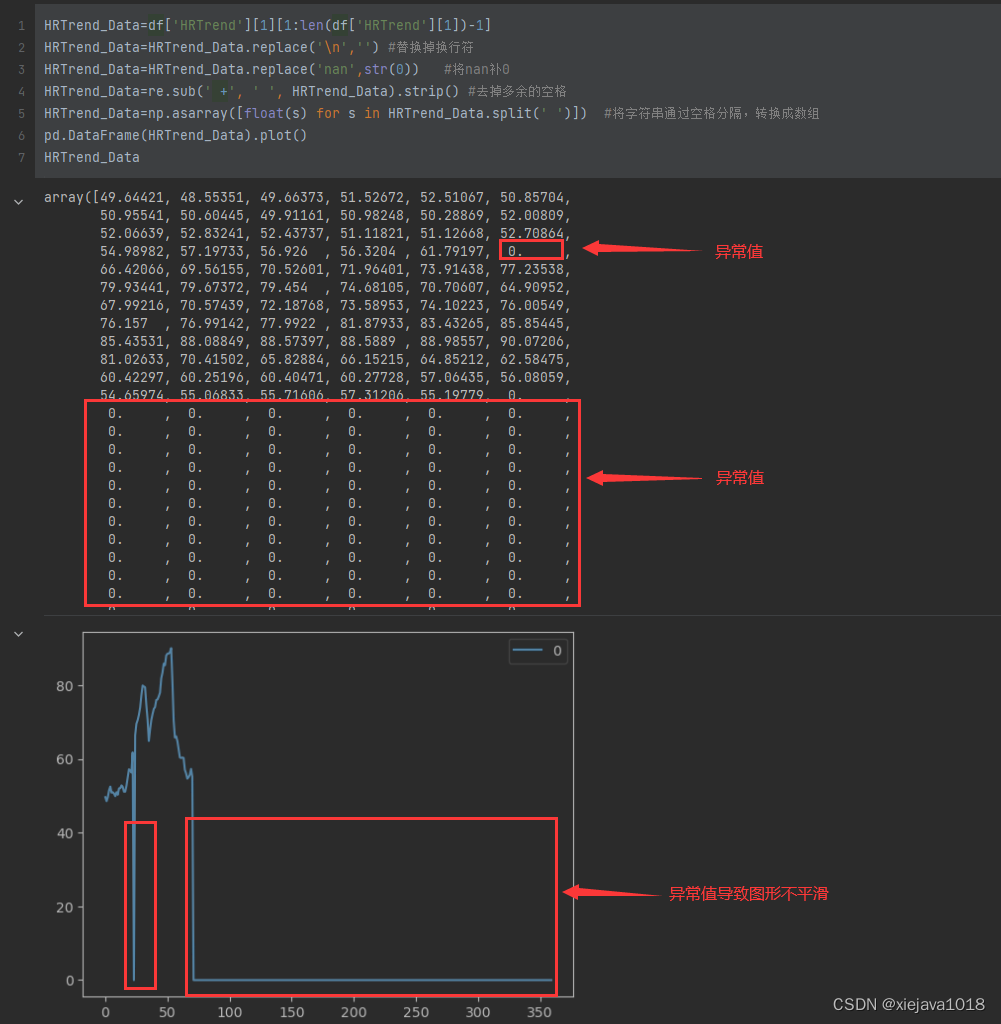
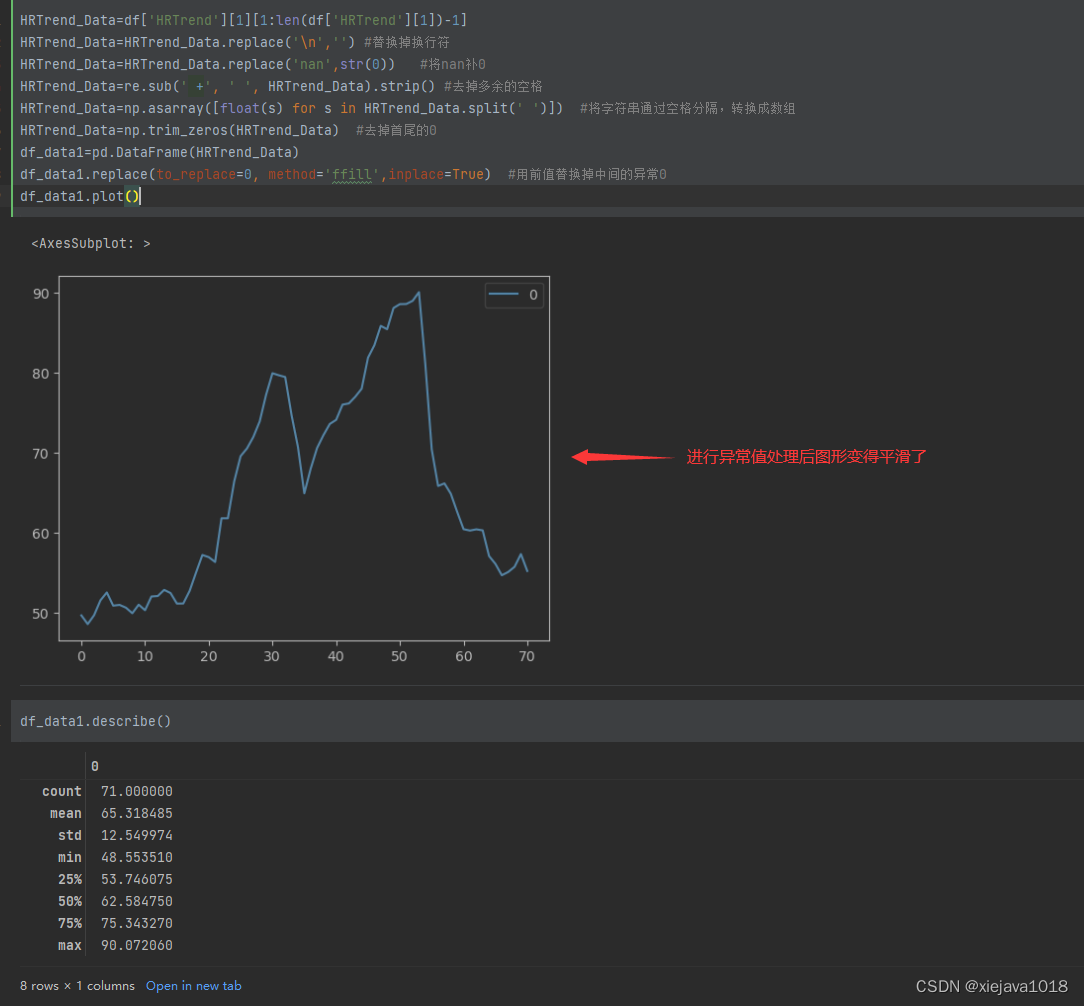
这个图形不是很规则不平滑,看数据是因为异常值太多,后面的数据都是0,这些0都是因为数据为Non补充进来的,有可能是应为数据采集的时候某个点位没有采集到。我们需要将这些异常值给处理掉。
对于中间为0的,我们可以通过采用前值填充或者后值填充(也就是用前面的值或后面的值来替代为0的值),后面全部为0的部分要去掉。应为会影响到一些关键性的特征,如均值、50%的值、70%的值等。
df_HRTrend1=pd.DataFrame(HRTrend_Data)
df_HRTrend1.describe()
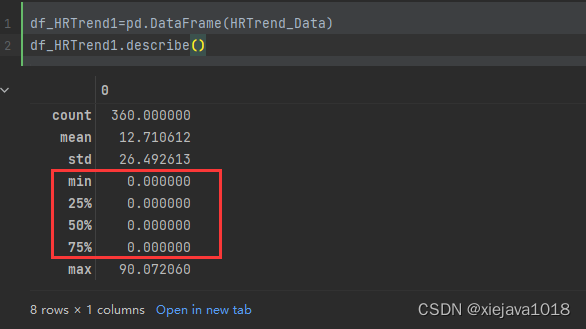
可以看到,这些异常值将会很大程度的影响一些关键特征,所以我们要处理异常值。
HRTrend_Data=np.trim_zeros(HRTrend_Data) #去掉首尾的0
df_data1=pd.DataFrame(HRTrend_Data)
df_data1.replace(to_replace=0, method='ffill',inplace=True) #用前值替换掉中间的异常0
df_data1.plot()
df_data1.describe()
把刚对一个样本处理的过程写成一个函数,应用到所有的样本数据。
def procdata(df_dataclumn):ary_data=df_dataclumn[1:len(df_dataclumn)-1]ary_data=ary_data.replace('\n','')ary_data=ary_data.replace('nan',str(0))ary_data=re.sub(' +', ' ', ary_data).strip()ary_data=np.asarray([float(s) for s in ary_data.split(' ')])ary_data=np.trim_zeros(ary_data)df_data=pd.DataFrame(ary_data)df_data.replace(to_replace=0, method='ffill',inplace=True)ary_data=df_data.valuesreturn ary_datadf['HRTrend']=df['HRTrend'].map(procdata)
df['Weight'].replace(to_replace=0, method='ffill',inplace=True) #去异常值
df['Height'].replace(to_replace=0, method='ffill',inplace=True) #去异常值
df
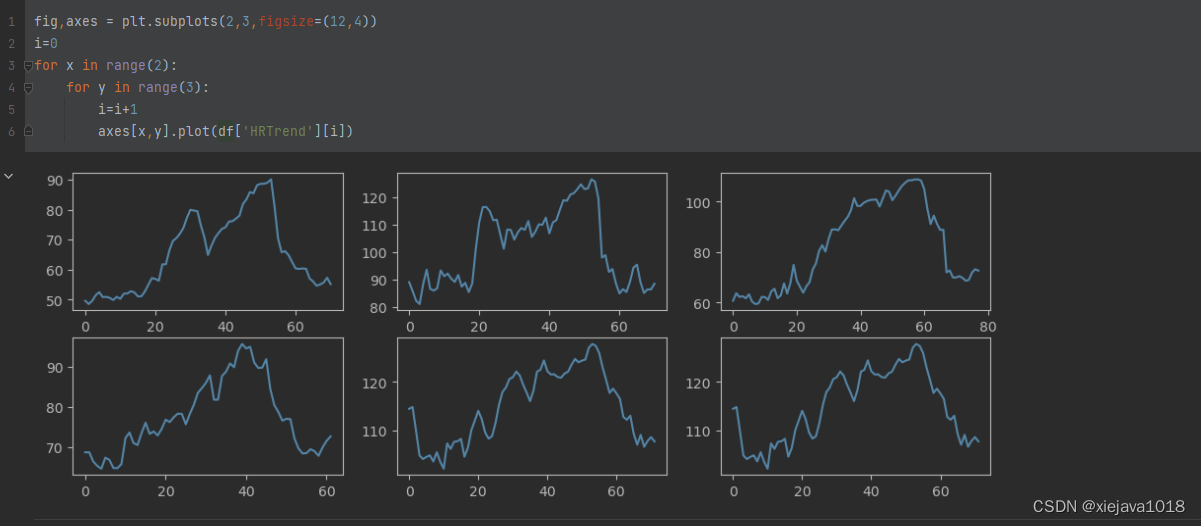
找前六个样本看看效果
fig,axes = plt.subplots(2,3,figsize=(12,4))
i=0
for x in range(2):for y in range(3):i=i+1axes[x,y].plot(df['HRTrend'][i])
二、特征工程及模型训练
方法一:通过描叙统计提取时序特征并进行模型训练
- 特征提取
有量纲时序特征提取包括以内容。
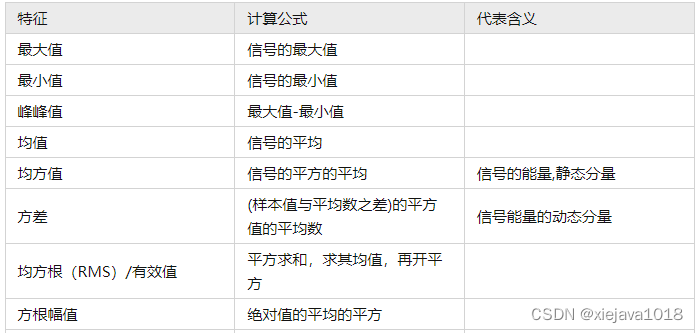
可以看到,大部分内容都可以通过describe()获取。可以写个函数方法来获取相关的特征值。
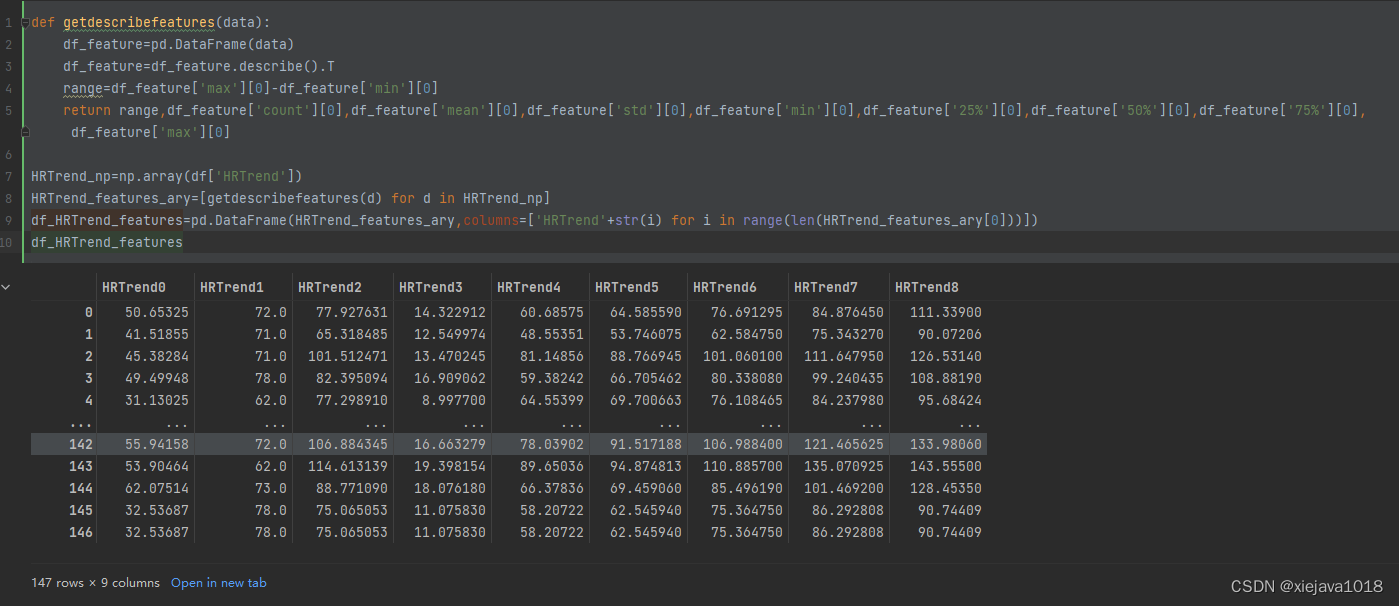
def getdescribefeatures(data):df_feature=pd.DataFrame(data)df_feature=df_feature.describe().Trange=df_feature['max'][0]-df_feature['min'][0]return range,df_feature['count'][0],df_feature['mean'][0],df_feature['std'][0],df_feature['min'][0],df_feature['25%'][0],df_feature['50%'][0],df_feature['75%'][0],df_feature['max'][0]HRTrend_np=np.array(df['HRTrend'])
HRTrend_features_ary=[getdescribefeatures(d) for d in HRTrend_np]
df_HRTrend_features=pd.DataFrame(HRTrend_features_ary,columns=['HRTrend'+str(i) for i in range(len(HRTrend_features_ary[0]))])
df_HRTrend_features
将心电图提出的统计信息特征与年龄、性别、身高、体重等特征合并,形成特征集。
df_data=df[['age','ismale','Weight','Height','label']].join(df_HRTrend_features)
预留15个样本做最后的预测看效果。
df_train_data=df_data[0:len(df_data)-15] #训练数据
df_predict_data=df_data[len(df_data)-15:len(df_data)] #用于预测的数据
- 模型训练
from sklearn.metrics import f1_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifierx_tt, x_validation, y_tt, y_validation = train_test_split(x, y, test_size=0.2)
# 将训练集再切分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x_tt, y_tt, test_size=0.25)#将模型的名字和模型函数作为元组添加到列表当中存储;
models = []
models.append(("KNN",KNeighborsClassifier(n_neighbors=3))) #指定邻居个数
models.append(("SVM Classifier",SVC(C=1000)))
#可以通过参数C来控制精度,C越大要求精度越高; C——错分点的惩罚度#循环调用所有模型进行训练、预测
for clf_name, clf in models:clf.fit(x_train, y_train)xy_lst = [(x_train, y_train), (x_validation, y_validation), (x_test, y_test)]for i in range(len(xy_lst)):x_part = xy_lst[i][0] # 为遍历中的第0部分y_part = xy_lst[i][1] # 为遍历中的第1部分y_pred = clf.predict(x_part)print(i) # i是下标,0表示训练集,1表示验证集,2表示测试集print(clf_name, "ACC:", accuracy_score(y_part, y_pred))print(clf_name, "REC:", recall_score(y_part, y_pred))print(clf_name, "F-score:", f1_score(y_part, y_pred))
结果如下:
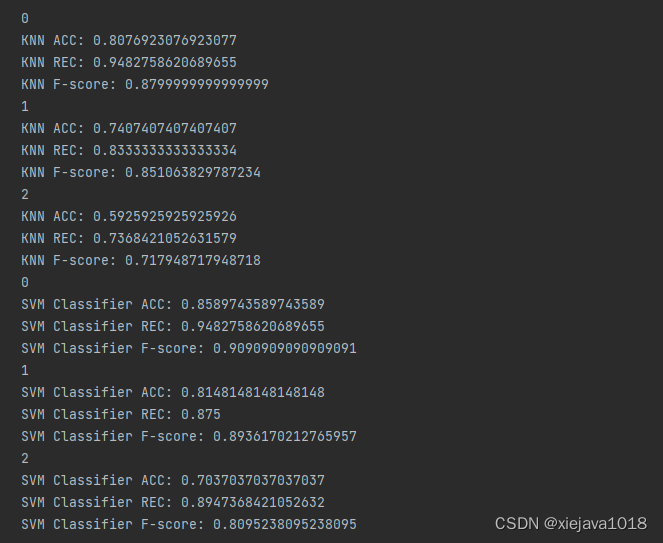
SVM分类模型的效果要稍好于KNN的模型,但整体效果还不是很好。应该是提取的特征还是不够。我们来试下通过tsfresh提取时序特征并进行模型训练。
方法二:通过tsfresh提取时序特征并进行模型训练
- 特征提取
tsfresh可以自动提取各种时间特征,可以参考官方文档,一般的取最大、最小、偏度、峰度等统计指标这些都自动化集成了。
https://tsfresh.readthedocs.io/en/latest/text/introduction.html
通过tsfresh提取时序特征代码如下:
from tsfresh import extract_features
from tsfresh import select_features
dfx_HRTrend=pd.DataFrame()
for i in df.index:df_i=pd.DataFrame(df['HRTrend'][i],columns=['HRTrend'])df_i['id']=idf_i['time']=np.array(range(1,len(df_i)+1))df_i['label']=df['label'][i]dfx_HRTrend=pd.concat(objs=[dfx_HRTrend,df_i])dfx_xtracted_features = extract_features(dfx_HRTrend,column_id="id", column_sort="time")
dfx_xtracted_features
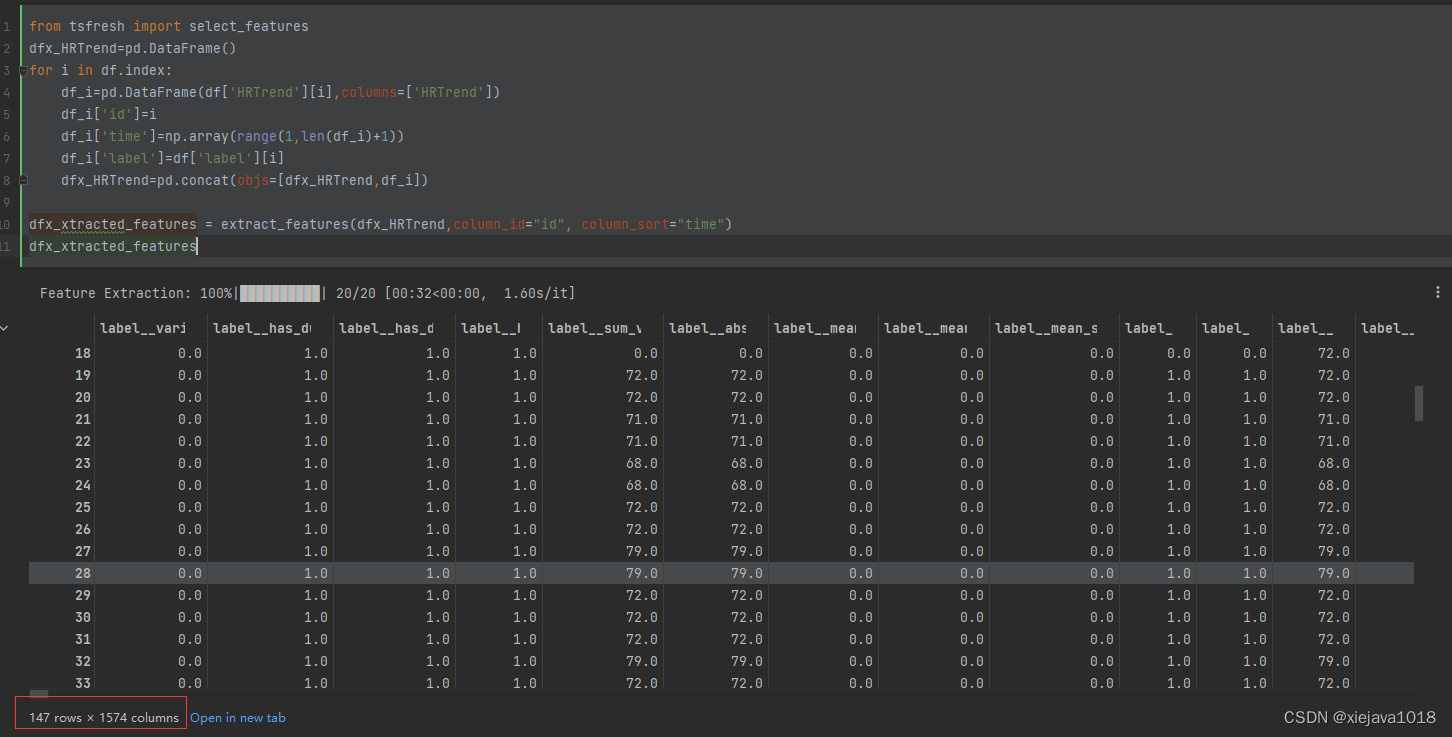
可以看到tsfresh自动提取了1574colums的特征,但是我们要选取与标签有相关性的特征。tsfresh可以自动做到这一点,通过tsfresh的select_features传入特征和标签来选择与标签有相关性的特征,
from tsfresh.utilities.dataframe_functions import impute
impute(dfx_xtracted_features)
df_HRTrend_features = select_features(dfx_xtracted_features, df['label'])
df_HRTrend_features
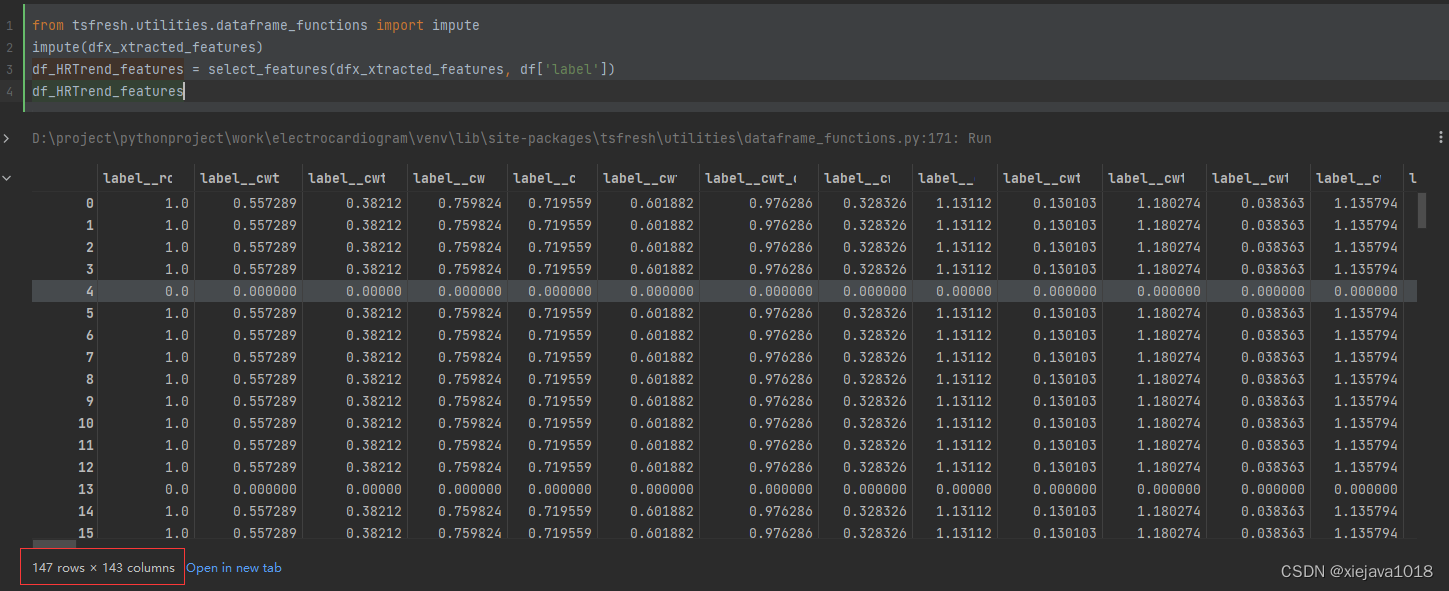
通过特征选择自动选取了有相关性的143个特征,比前面缩减了很多,有利于提高模型训练的效率和精度。
我们再来看一下模型训练的效果。
同样将心电图通过tsfresh提出的时序特征与年龄、性别、身高、体重等特征合并,形成特征集。
df_data=df[['age','ismale','Weight','Height','label']].join(df_HRTrend_features)
预留15个样本做最后的预测看效果。
df_train_data=df_data[0:len(df_data)-15] #训练数据
df_predict_data=df_data[len(df_data)-15:len(df_data)] #用于预测的数据
模型训练
from sklearn.metrics import f1_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifierx_tt, x_validation, y_tt, y_validation = train_test_split(x, y, test_size=0.2)
# 将训练集再切分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x_tt, y_tt, test_size=0.25)#将模型的名字和模型函数作为元组添加到列表当中存储;
models = []
models.append(("KNN",KNeighborsClassifier(n_neighbors=3))) #指定邻居个数
models.append(("SVM Classifier",SVC(C=1000)))
#可以通过参数C来控制精度,C越大要求精度越高; C——错分点的惩罚度#循环调用所有模型进行训练、预测
for clf_name, clf in models:clf.fit(x_train, y_train)xy_lst = [(x_train, y_train), (x_validation, y_validation), (x_test, y_test)]for i in range(len(xy_lst)):x_part = xy_lst[i][0] # 为遍历中的第0部分y_part = xy_lst[i][1] # 为遍历中的第1部分y_pred = clf.predict(x_part)print(i) # i是下标,0表示训练集,1表示验证集,2表示测试集print(clf_name, "ACC:", accuracy_score(y_part, y_pred))print(clf_name, "REC:", recall_score(y_part, y_pred))print(clf_name, "F-score:", f1_score(y_part, y_pred))
结果如下:
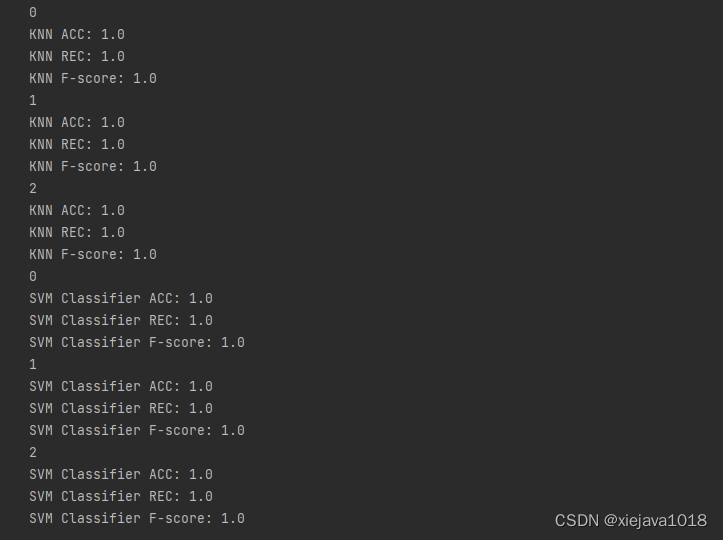
可以看到不管是KNN模型和SVM的模型都取得了不错的效果。
三、效果
最后我们来看一下,用预留的15个样本预测的效果。
pre_test_y=df_predict_data['label']
pre_test_x=df_predict_data.drop(columns='label')for clf_name, clf in models:for i in pre_test_x.index:y_predict=clf.predict(pre_test_x.loc[[i]])predict_result='预测错误!'if y_predict==pre_test_y.loc[[i]].values:predict_result='预测正确!'print('第'+str(i)+'个样本'+clf_name+' 预测y='+str(y_predict)+'--实际 y='+str(pre_test_y.loc[[i]].values)+' - '+predict_result)print('-'*10)
先是通过描叙统计提取时序特征并进行模型训练后模型预测的结果:
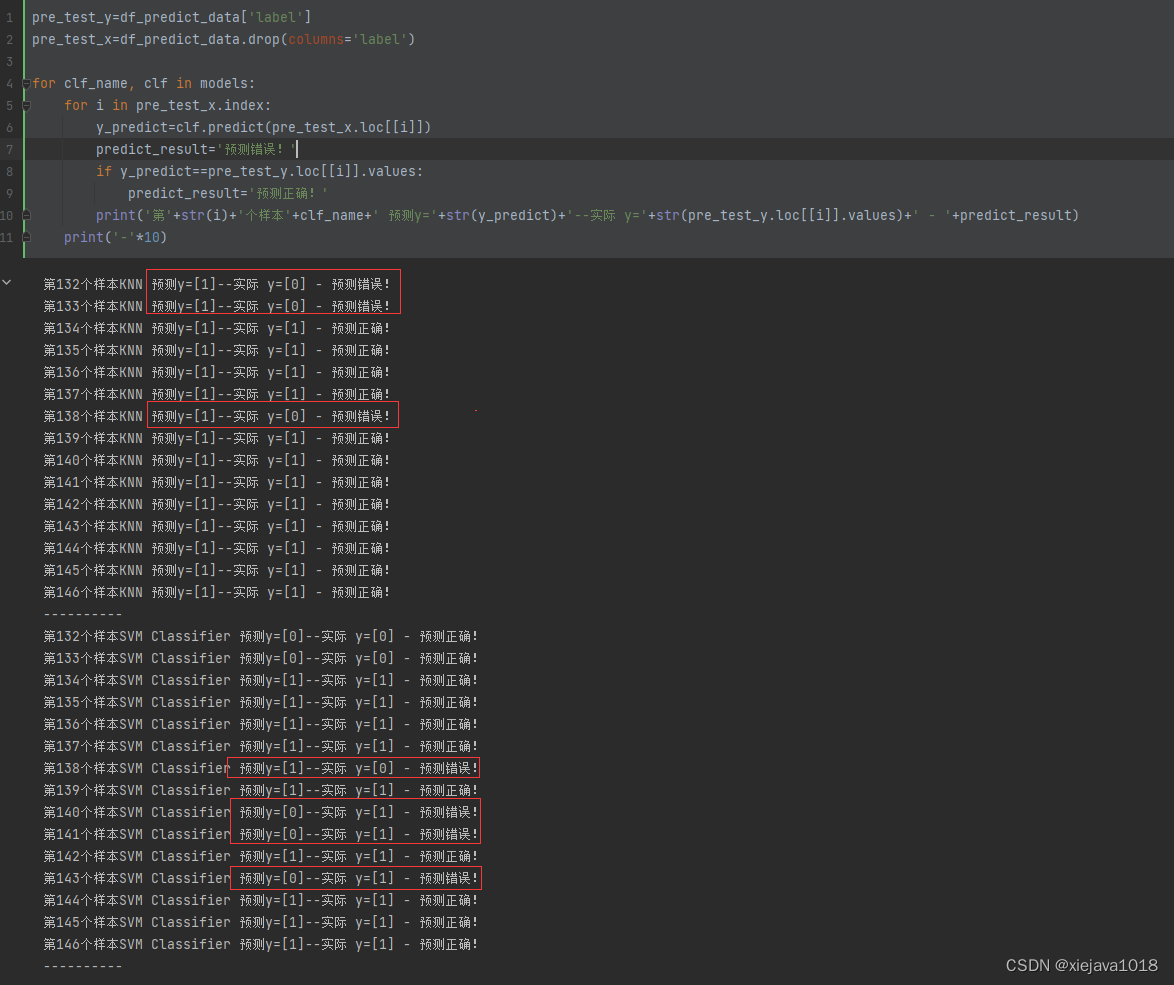
还是有不少预测错误了。
再来看通过tsfresh提取时序特征并进行模型训练后模型预测的结果:
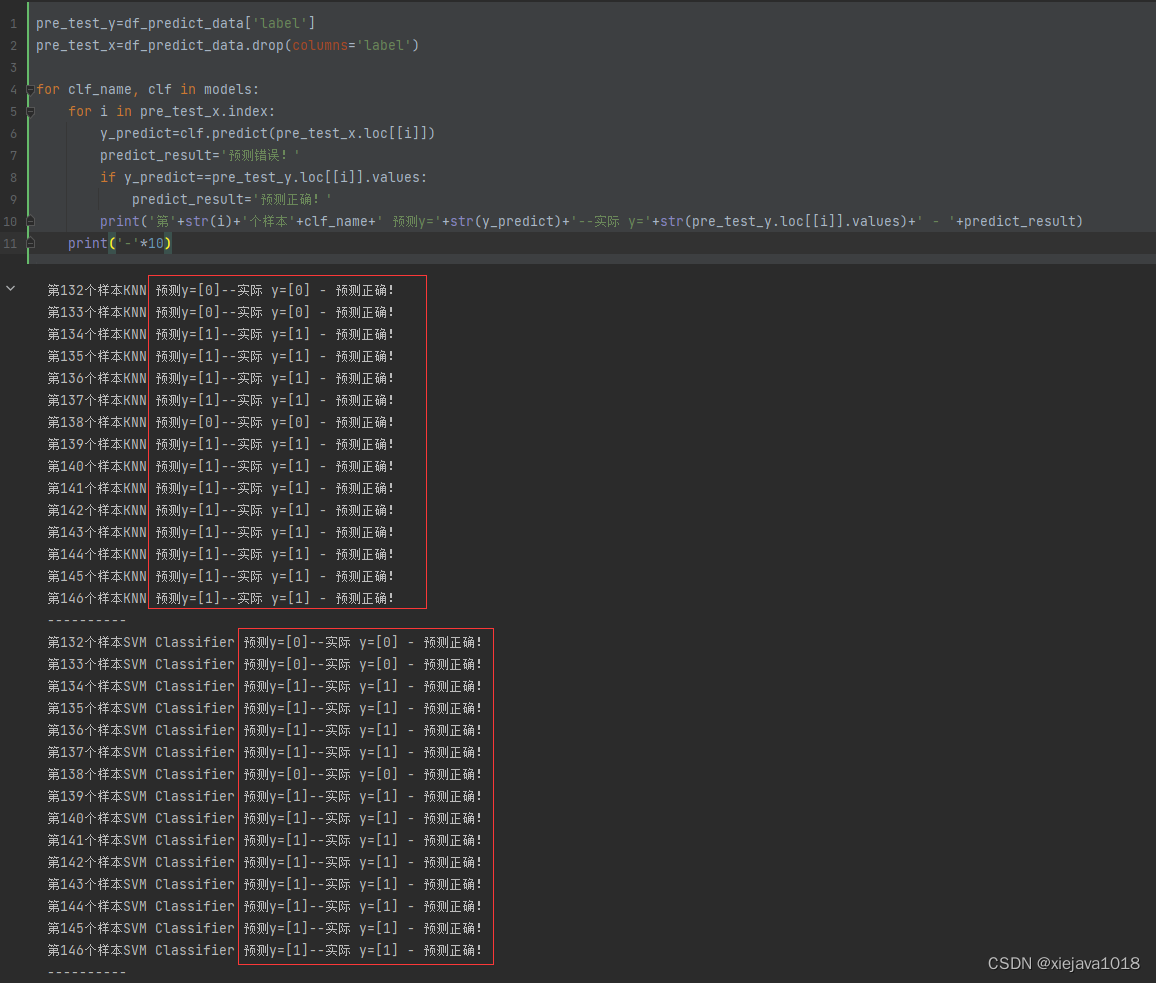
可以看到预留的15个样本都预测正确,取得了不错的效果!
本文通过心电图分类模型介绍了从数据处理、时序特征提取、模型训练和效果评估。验证了对于小数据量,通过tsfresh提取时序特征,往往能够取得很好的效果。
全部源代码及数据集见:https://download.csdn.net/download/fullbug/87369380
博客地址:http://xiejava.ishareread.com/


![基础算法[四]之图的那些事儿](https://img-blog.csdnimg.cn/485dba8af63d4f1da3bc430c88497283.png)