1. 解决了什么问题?
目前的目标检测器很少能做到快速训练、快速推理,并同时保持准确率。直觉上,推理越快的检测器应该训练也很快,但大多数的实时检测器反而需要更长的训练时间。准确率高的检测器大致可分为两类:推理时间久的的训练时间久的。
推理时间久的检测器一般依赖于复杂的后处理逻辑或沉重的检测 head。尽管这些设计能提升准确率和收敛速度,但是推理速度很慢,不适合实时应用。
为了降低推理速度,人们尝试去简化检测 head 与后处理,同时能维持准确率。CenterNet 的推理速度快,但是需要很长的训练时间,这是因为简化后的网络很难训练,过度依赖于数据增强和长训练周期。比如,CenterNet 在 MS COCO 数据集上需要训练 140 140 140个 epochs,而第一类方法只要训练 12 12 12epochs。
研究发现,如果 batch size 越大,可采取较大的学习率,二者之间服从某种线性关系。作者发现,从标注框编码更多的训练样本,与增大 batch size 的作用相似。与特征提取相比,编码特征、计算损失的时间微乎其微。这样我们就可以很低的代价来加快收敛。CenterNet 在回归目标的尺寸时,只关注目标的中心点,无法利用目标中心点附近的信息,造成收敛速度很慢。
2. 提出了什么方法?
为了平衡速度和准确率,作者提出了 TTFNet,它具有 light-head、单阶段和 anchor-free 的特点,推理速度很快。为了降低训练时间,作者发现从标注框中编码更多的训练样本,与增大 batch size 作用相似,从而可以增大学习率、加快训练过程。最后,在进行定位和回归时,提出利用高斯核来编码训练样本的方法。于是网络可以更好地利用标注框,产生更多的监督信号,实现快速收敛。通过高斯核构建出目标中心的附近区域,从该区域内提取训练样本。将高斯概率作为回归样本的权重使用,这样能更加关注于中心附近的样本。该方法能减少模糊的、低质量样本,无需 FPN 结构。此外,也无需预测偏移量来修正预测结果。
Motivation
编码更多的训练样本与增大 batch size 是相似的,都可以提供更多的监督信号。这里的“训练样本”是指标注框内编码的特征。在随机梯度下降(SGD)中,权重更新表示为:
w t + 1 = w t − η 1 n ∑ x ∈ B Δ l ( x , w t ) w_{t+1}=w_t - \eta\frac{1}{n}\sum_{x\in B}\Delta l(x,w_t) wt+1=wt−ηn1x∈B∑Δl(x,wt)
w w w是网络权重, B B B是训练集里的 mini-batch, n = ∣ B ∣ n=|B| n=∣B∣是 mini-batch size, η \eta η是学习率, l ( x , w ) l(x,w) l(x,w)是图像 x x x的损失计算。
对于目标检测任务,图像 x x x包含多个标注边框,这些边框会被编码为训练样本 s ∈ S x s\in S_x s∈Sx。 m x = ∣ S x ∣ m_x=|S_x| mx=∣Sx∣是图像 x x x中所有边框产生的样本个数。因此上式可写为:
w t + 1 = w t − η 1 n ∑ x ∈ B 1 m x ∑ s ∈ S x Δ l ( s , w t ) w_{t+1}=w_t - \eta \frac{1}{n}\sum_{x\in B} \frac{1}{m_x} \sum_{s\in S_x} \Delta l(s, w_t) wt+1=wt−ηn1x∈B∑mx1s∈Sx∑Δl(s,wt)
为了更简洁,我们假设 mini-batch B B B里的每张图像 x x x的 m x m_x mx都相等。对于每个训练样本 s s s,上式写为:
w t + 1 = w t − η 1 n m ∑ s ∈ B Δ l ( s , w t ) w_{t+1}=w_t - \eta \frac{1}{nm}\sum_{s\in B}\Delta l(s,w_t) wt+1=wt−ηnm1s∈B∑Δl(s,wt)
根据线性缩放规则,如果 batch size 乘以 k k k,则学习率也要乘以 k k k,除非网络变动很大,或使用了非常大的 mini-batch。只有当我们能假设 Δ l ( x , w t ) ≈ Δ l ( x , w t + j ) , j < k \Delta l(x,w_t)\approx \Delta l(x, w_{t+j}),j<k Δl(x,wt)≈Δl(x,wt+j),j<k时,用小 mini-batch B j B_j Bj跑 k k k次、学习率为 η \eta η,与用较大的 mini-batch ∪ j ∈ [ 0 , k ) B j \cup_{j\in [0,k)}B_j ∪j∈[0,k)Bj、学习率为 k η k\eta kη跑 1 1 1次是等价的。这里,我们只关注训练样本 s s s,mini-batch size ∣ B ∣ = n m |B|=nm ∣B∣=nm。作者提出了一个相似的结论:每个 mini-batch 内的训练样本个数乘以 k k k,则学习率乘以 l l l, 1 ≤ l ≤ k 1\leq l\leq k 1≤l≤k。
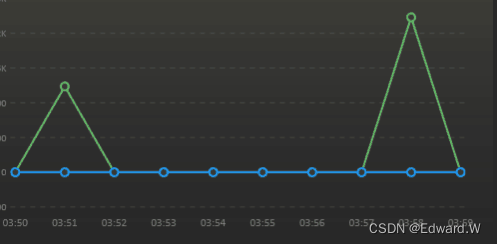
CenterNet 的推理速度很快,但训练时间很长。它在训练过程中使用了复杂的数据增强方法。尽管这些增强能提升训练准确率,但是收敛很慢。为了排除它们对收敛速度的影响,实验时不使用数据增强,而且加大学习率。如下图,较大的学习率能加快收敛,但是准确率下降,会造成过拟合。这是因为 CenterNet 在训练时只会在目标中心位置编码一个回归样本,这使得 CenterNet 必须依赖于数据增强和长训练周期。

Approach
Background
CenterNet 将目标检测任务分为两个部分:中心定位和尺寸回归。在定位任务,它采取高斯核输出热力图,网络在目标中心附近产生高激活值。在回归任务,将目标中心点的像素定义为训练样本,直接预测目标的宽度和高度。此外,它会预测目标因输出步长而造成的偏移。网络在推理时,目标中心点附近的激活值较高,NMS 可被替换为其它操作。为了去除 NMS,作者采取了与中心定位相似的策略,在高斯核中加入了边框的宽高比。CenterNet 没有考虑到这一点,不是最优的。
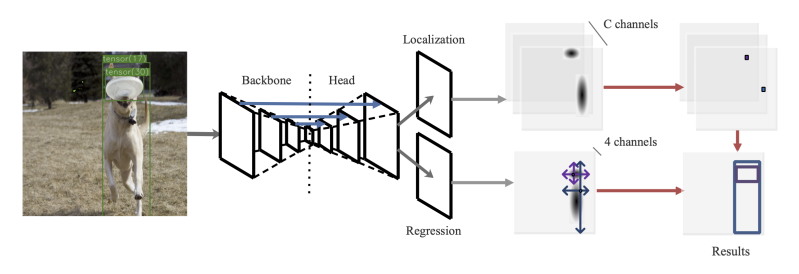
对于尺寸回归,作者将高斯区域内所有的像素点都当作训练样本。此外,使用目标大小和高斯概率计算出样本的权重,更好地利用信息。该方法无需预测偏移量来修正下采样造成的误差,因此更加简洁、高效。下图中,主干网络提取特征,然后上采样到原图 1 / 4 1/4 1/4分辨率。然后这些特征用于定位和回归任务。定位时,网络在目标中心输出高激活值。回归时,边框的高斯区域内的所有样本都能直接预测它到四条边的距离。
Gaussian Kernels for Training
给定一张图片,网络分别预测特征 H ^ ∈ R N × C × H r × W r \hat{H}\in \mathcal{R}^{N\times C\times \frac{H}{r}\times \frac{W}{r}} H^∈RN×C×rH×rW和 S ^ ∈ R N × 4 × H r × W r \hat{S}\in \mathcal{R}^{N\times 4\times \frac{H}{r}\times \frac{W}{r}} S^∈RN×4×rH×rW。前者表示目标中心点在哪,后者获取目标尺寸的信息。 N , C , H , W , r N,C,H,W,r N,C,H,W,r分别是 batch size、类别数、输入图像的高度和宽度、输出步长。实验中, C = 80 , r = 4 C=80,r=4 C=80,r=4。在定位和回归任务,都使用了高斯核,使用标量 α , β \alpha,\beta α,β来控制高斯核大小。
Object Localization
假设第 m m m个标注框属于第 c m c_m cm个类别,首先将它线性映射到特征图尺度。然后 2D 高斯核 K m ( x , y ) = exp ( − ( x − x 0 ) 2 2 σ x 2 − ( y − y 0 ) 2 2 σ y 2 ) \mathbf{K}_m(x,y)=\exp({-\frac{(x-x_0)^2}{2\sigma_x^2}}-\frac{(y-y_0)^2}{2\sigma_y^2}) Km(x,y)=exp(−2σx2(x−x0)2−2σy2(y−y0)2)用于输出 H m ∈ R 1 × H r × W r H_m\in \mathcal{R}^{1\times \frac{H}{r}\times \frac{W}{r}} Hm∈R1×rH×rW,其中 σ x = α ⋅ w 6 , σ y = α ⋅ h 6 \sigma_x=\frac{\alpha\cdot w}{6},\sigma_y=\frac{\alpha\cdot h}{6} σx=6α⋅w,σy=6α⋅h。最后,对 H m H_m Hm使用 element-wise max 操作,更新 H H H的第 c m c_m cm个通道。 H m H_m Hm由参数 α \alpha α、中心位置 ( x 0 , y 0 ) m (x_0,y_0)_m (x0,y0)m和边框大小 ( h , w ) m (h,w)_m (h,w)m决定。使用 ( ⌊ x r ⌋ , ⌊ y r ⌋ ) (\lfloor\frac{x}{r}\rfloor, \lfloor\frac{y}{r}\rfloor) (⌊rx⌋,⌊ry⌋)使中心点落在某像素点上。网络中,设定 α = 0.54 \alpha=0.54 α=0.54。
将高斯分布的峰值点(边框中心像素点)当作正样本,其它像素点当作负样本。
给定预测 H ^ \hat{H} H^和定位目标 H H H:
L l o c = − 1 M { ( 1 − H ^ i j c ) α f log ( H ^ i j c ) if H i j c = 1 ( 1 − H i j c ) β f H ^ i j c α f log ( 1 − H ^ i j c ) , otherwise L_{loc} = -\frac{1}{M}\left\{ \begin{array}{ll} (1-\hat{H}_{ijc})^{\alpha_f}\log(\hat{H}_{ijc})\quad\quad\quad\quad\quad\quad\quad\text{if}\quad H_{ijc}=1 \\ (1-H_{ijc})^{\beta_f}\hat{H}^{\alpha_f}_{ijc}\log (1-\hat{H}_{ijc}),\quad\quad\quad \text{otherwise} \end{array} \right. Lloc=−M1{(1−H^ijc)αflog(H^ijc)ifHijc=1(1−Hijc)βfH^ijcαflog(1−H^ijc),otherwise
其中 α f , β f \alpha_f,\beta_f αf,βf是 focal loss 的超参。 M M M表示标注框的个数。 α f = 0.2 , β f = 4 \alpha_f=0.2,\beta_f=4 αf=0.2,βf=4。
Size Regression
给定特征图尺度上的第 m m m个标注框,用高斯核输出 S m ∈ R 1 × H r × W r S_m\in \mathcal{R}^{1\times \frac{H}{r}\times \frac{W}{r}} Sm∈R1×rH×rW, β \beta β控制高斯核大小。 S m S_m Sm中的非零区域叫做高斯区域 A m A_m Am。 A m A_m Am总是存在于第 m m m个边框内,因此被叫做 sub-area。
Sub-area 内每个像素都是一个回归样本。给定 A m A_m Am内的像素 ( i , j ) (i,j) (i,j)及输出步长 r r r,回归目标定义为 ( i r , j r ) (ir,jr) (ir,jr)到第 m m m边框四条边的距离,记做一个四维向量 ( w l , h t , w r , h b ) i j m (w_l,h_t,w_r,h_b)^m_{ij} (wl,ht,wr,hb)ijm。 ( i , j ) (i,j) (i,j)位置的预测框表示为:
x ^ 1 = i r − w ^ l s , y ^ 1 = j r − h ^ t s \hat{x}_1=ir-\hat{w}_ls, \quad\quad \hat{y}_1=jr-\hat{h}_ts x^1=ir−w^ls,y^1=jr−h^ts
x ^ 2 = i r + w ^ r s , y ^ 2 = j r + h ^ b s \hat{x}_2=ir+\hat{w}_rs, \quad\quad \hat{y}_2=jr+\hat{h}_bs x^2=ir+w^rs,y^2=jr+h^bs
s s s是个固定标量,扩大预测结果,从而降低优化难度。实验中 s = 16 s=16 s=16。预测框 ( x ^ 1 , y ^ 1 , x ^ 2 , y ^ 2 ) (\hat{x}_1,\hat{y}_1,\hat{x}_2,\hat{y}_2) (x^1,y^1,x^2,y^2)位于图像尺度,而非特征图尺度。
不存在于任何 sub-area 内的像素,在训练时会被忽略。如果一个像素同时存在于多个 sub-area(模糊样本),则训练 target 设为面积较小的目标。
给定预测结果 S ^ \hat{S} S^和回归目标 S S S,从 S S S中汇集训练目标 S ′ ∈ R N r e g × 4 S'\in \mathcal{R}^{N_{reg}\times 4} S′∈RNreg×4,及其对应的预测结果 S ′ ^ ∈ R N r e g × 4 \hat{S'}\in \mathcal{R}^{N_{reg}\times 4} S′^∈RNreg×4, N r e g N_{reg} Nreg表示回归样本数。如上式所做的,对于这些样本,解码出预测边框,及其对应的标注框。使用 GIoU 计算损失:
L r e g = 1 N r e g ∑ ( i , j ) ∈ A m GIoU ( B ^ i j , B m ) × W i j L_{reg}=\frac{1}{N_{reg}}\sum_{(i,j)\in A_m} \text{GIoU}(\hat{B}_{ij},B_m)\times W_{ij} Lreg=Nreg1(i,j)∈Am∑GIoU(B^ij,Bm)×Wij
B ^ i j \hat{B}_{ij} B^ij表示解码后的边框 ( x ^ 1 , y ^ 1 , x ^ 2 , y ^ 2 ) i j (\hat{x}_1,\hat{y}_1,\hat{x}_2,\hat{y}_2)_{ij} (x^1,y^1,x^2,y^2)ij, B m = ( x 1 , y 1 , x 2 , y 2 ) m B_m=({x}_1,{y}_1,{x}_2,{y}_2)_m Bm=(x1,y1,x2,y2)m表示图像尺度的第 m m m个标注框。 W i j W_{ij} Wij是样本权重,平衡各样本的损失。
因为目标尺度都不一样,大目标可能产生几千个样本,而小目标只能产生很少。损失归一化后,小目标的损失几乎都没了,这不利于检测小目标。因此,样本权重 W i j W_{ij} Wij发挥着重要作用,平衡损失。假定 ( i , j ) (i,j) (i,j)位于第 m m m个标注框的子区域 A m A_m Am内,
W i j = { log ( a m ) × G m ( i , j ) ∑ ( x , y ) ∈ A m G m ( x , y ) if ( i , j ) ∈ A m 0 if ( i , j ) ∉ A m W_{ij} = \left\{ \begin{array}{ll} \log(a_m)\times \frac{G_m(i,j)}{\sum_{(x,y)\in A_m} G_m(x,y)} \quad\quad\quad\quad\text{if}\quad (i,j)\in A_m \\ 0\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\text{if}\quad (i,j)\notin A_m \end{array} \right. Wij={log(am)×∑(x,y)∈AmGm(x,y)Gm(i,j)if(i,j)∈Am0if(i,j)∈/Am
其中 G m ( i , j ) G_m(i,j) Gm(i,j)是 ( i , j ) (i,j) (i,j)位置的高斯概率。 a m a_m am是第 m m m个边框的面积。该机制能更好地利用大目标的标注信息,保留小目标的信息。它也能突出目标中心附近的样本,减少模糊和低质量样本。
Total Loss
总损失 L L L包括了定位损失 L l o s L_{los} Llos和回归损失 L r e g L_{reg} Lreg,用两个标量加权。 L = w l o g L l o c + w r e g L r e g L=w_{log}L_{loc}+w_{reg}L_{reg} L=wlogLloc+wregLreg,本文设定 w l o c = 1.0 , w r e g = 5.0 w_{loc}=1.0, w_{reg}=5.0 wloc=1.0,wreg=5.0。
Overall Design
TTFNet 的结构如上图所示。主干使用 ResNet 和 DarkNet。主干提取特征后,上采样到原图的 1 / 4 1/4 1/4分辨率,用 Modulated Deform Conv 和上采样层实现,后面跟着 BN 层和 ReLU 层。
然后,上采样特征分别输入进两个 heads。定位 head 对目标中心附近的位置输出高激活值,而回归 head 直接预测这些位置到边框四条边的距离。因为目标中心对应特征图的局部极大值,用 2D 最大池化来抑制非极大值。然后用局部极大值来汇总回归结果。最后得到检测结果。
该方法充分利用了大中目标的标注信息,而小目标的提升有限。为了提升短训练周期中小目标的表现,通过短路连接来引入高分辨率、低层级特征。短路连接引入了主干网络第2、3、4阶段的特征,每个连接用 3 × 3 3\times 3 3×3卷积实现。短路连接的第2、3、4阶段的层数分别设为3、2、1,每层后跟着一个 ReLU,除了最后一个。