目录
概况
常用高级图形
条形图
csv文件导入
csv文件导出
R语言sep函数
seq函数
with函数
直方图和密度估计图
盒型图
boxplot()
正态QQ图
散点图
pairs()散点矩阵图
曲线图
curve()
三维图
动态三维图
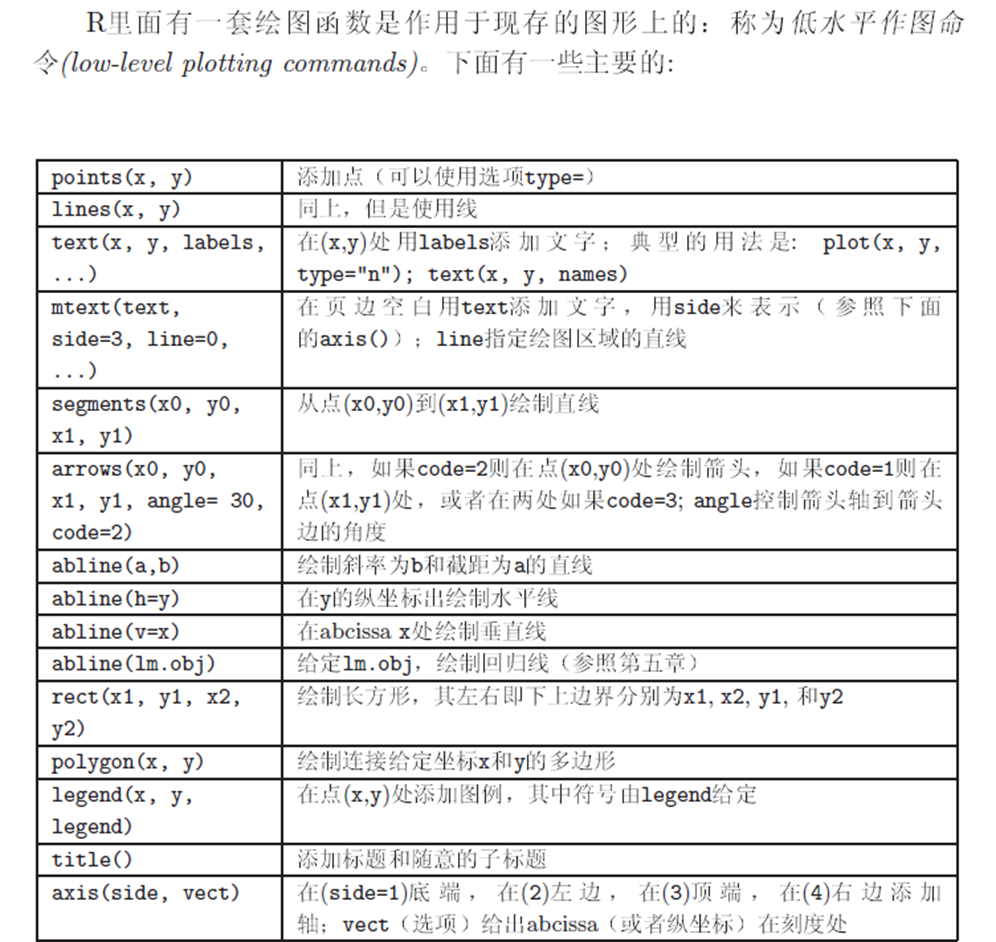
低级图形函数
abline()
lines()
legand()增加图例
axis()坐标轴
text()给图内区域添加文字
locator()和identify()
图形的参数
例子:用图形参数解决barplot图形横坐标值过宽
图形元素控制
坐标轴与坐标刻度
图形边空
一页多图
图形输出
PDF输出
PNG输出
包含多种中文字体的图形
其他图形
相关系数图
万字带你入门绘图
概况
R语言的前身是S语言, S语言的设计目的就是交互式数据分析、绘图。 所以绘图是R的重要功能。
R有最初的基本绘图, 这是从S语言继承过来的, 还有一些功能更易用、更强大的绘图系统, 如lattice、ggplot2。 基本绘图使用简单, 灵活性强, 但是为了做出满意的图形需要比较多的调整。 这里先讲解R语言的基本绘图功能。
R的基本绘图功能有两类图形函数: 高级图形函数, 直接针对某一绘图任务作出完整图形; 低级图形函数,在已有图形上添加内容。 具备有限的与图形交互的能力(函数locator 和identify)。
绘图命令首先可以分成三个基本的类
- 高级绘图命令在图形设备上产生新的图区,它可能包括坐标轴、标签、标题等。plot(),hist()…
- 低级画图命令在已存在的图上添加更多的图形元素,如额外点、线和标签。 lines(),points(),legend(),title(),axis()…

常用高级图形
条形图
这里会大量碰到barplot函数的运用,建议大家去这个博主的博客里看看,很详细.👉barplot详解
我们在d.cancer这个数据框存储了肺癌病人放疗的一些数据,这些数据可以从以下文件读入
cancer.csv
id age sex type v0 v1
1 70 F 腺癌 26.51 2.91
2 70 F 腺癌 135.48 35.08
3 69 F 腺癌 209.74 74.44
4 68 M 腺癌 61 34.97
5 67 M 鳞癌 237.75 128.34
6 75 F 腺癌 330.24 112.34
7 52 M 鳞癌 104.9 32.1
8 71 M 鳞癌 85.15 29.15
9 68 M 鳞癌 101.65 22.15
10 79 M 鳞癌 65.54 21.94
11 55 M 腺癌 125.31 12.33
12 54 M 鳞癌 224.36 99.44
13 55 F 腺癌 12.93 2.3
14 75 M 腺癌 40.21 23.96
15 61 F 腺癌 12.58 7.39
16 76 M 鳞癌 231.04 112.58
17 65 M 鳞癌 172.13 91.62
18 66 M 鳞癌 39.26 13.95
19 F 腺癌 32.91 9.45
20 63 F 腺癌 161 122.45
21 67 M 鳞癌 105.26 68.35
22 51 M 鳞癌 13.25 5.25
23 49 M 鳞癌 18.7 3.34
24 49 M 鳞癌 60.23 50.36
25 F 鳞癌 223 25.59
26 M 鳞癌 145.7 35.36
27 M 鳞癌 138.44 11.3
28 M 鳞癌 83.71 76.45
29 M 鳞癌 74.48 23.66
30 F 腺癌 42.7 5.97
31 M 鳞癌 142.48 68.46
32 F 鳞癌 46.97 27.32
33 F 鳞癌 170.63 74.76
34 F 鳞癌 67.37 54.52
csv文件导入
csv是最常用的数据源格式,具有通用性与普遍性,导入csv文件到R也有众多方法。
- 方法1:使用Rstudio导入

在R中的右侧pane中,有import dataset选项,如果安装了readr包,也提供了该包的图形界面操作。操作简单,但是有个问题,如果csv格式路径包含了中文,就会出现乱码,然后无法导入。该方法对国内用户支持不友好,如果想用此法导入数据的话,只能把csv文件重命名并放至纯英文的文件夹中。
- 方法2:内置函数
R中内置了读入csv格式的函数:read.csv函数,该函数是由read.table函数改的特定函数,使用逗号作为分隔符,同时header与fill这两个参数默认为TRUE。
#读入csv文件 #把路径换成自己的文件路径 df <- read.csv("C:/Users/Administrator/Desktop/a文件.csv") #read.csv2,适用于小数点为“,”的csv文件 df <- read.csv2("C:/Users/Administrator/Desktop/b文件.csv") #小技巧,弹窗选择文件 df <- read.csv(file.choose())
使用内置函数导入csv文件,则不存在中文路径的问题,同时还提供了导入以小数点为“,”的csv文件。对于单一csv文件,使用file.choose函数进行图形界面选择,更加简单方便。
可能遇到的问题:导入中文csv文件,容易出现乱码。
#中文乱码处理 df <- read.csv( "C:/Users/Administrator/Desktop/a文件.csv", fileEncoding = "GBK", #指定文件的编码 encoding = "GBK" #指定编码 )
使用fileEncoding参数指定文件的编码,能解决大部分导入出现中文乱码的问题。如果导入后在R中显示出现乱码,增加encoding参数指定编码,也能解决大部分问题。
- 方法3:使用readr包
readr包又是Hadley Wickham大神贡献的R包之一,相比于内置函数,readr包读入的速度更快。该包的函数与内置函数相对应,并以read_XXX形式命名。
#readr包 df.readr <- read_csv("C:/Users/Administrator/Desktop/a文件.csv") #同样提供读入小数点为“,”的csv文件 df.readr <- read_csv2("C:/Users/Administrator/Desktop/a文件.csv")
readr包能够自动解析导入文件列的类型,这对于规整的数据来说很方便,但在我工作中,需要导入的文件常常有非法的字符,比如运费这一列,数据类型应该为数值型,但经常出现“--”这种字符串,表示无。readr包会将该值强制转换为NA,在后续的处理中,新增计算列的时候,比如销售总额 = 销售额+运费,则导致该值为NA,为了避免出现这类问题,我通常在导入数据的时候,设置为纯文本导入,然后再做处理。
#设置纯文本导入 df.readr <- read_csv( "C:/Users/Administrator/Desktop/a文件.csv", locale = locale(encoding = "GBK"), #指定编码 col_types = cols(.default = col_character()) #纯文本读入 )
同样的,如果出现中文乱码,使用locale参数设置编码。col_types参数设置各列的类型。
对于未知文件编码的csv文件,readr包提供了一个函数来判断文件编码。
#判断编码 > guess_encoding("C:/Users/Administrator/Desktop/a文件.csv") # A tibble: 1 x 2 encoding confidence <chr> <dbl> 1 ASCII 1
返回一个数据框,encoding为文件编码,confidence是该编码的置信值,越高越有可能是这个编码。
- 方法4:使用data.table包
data.table包是另一个处理数据的利器,对于GB级的数据更加高效。该包提供了一个函数读入csv文件,相比于上面几个方法,其速度是最快。
#data.table包 df.datatable <- fread("C:/Users/Administrator/Desktop/a文件.csv") #指定编码 df.datatable <- fread("C:/Users/Administrator/Desktop/a文件.csv",encoding = "UTF-8")
fread函数提供的编码很少,”UTF-8“,”Latin-1“,默认是”unknown“,所以对中文的支持不太友好,在使用该函数的时候,建议把csv文件的编码转换为”UTF-8“。
csv文件导出
- 方法1:内置函数
R提供了write.csv函数导出数据,该函数也是write.table函数的特定版。
#导出文件 write.csv(df, file = "C:/Users/Administrator/Desktop/导出文件.csv") #与read.csv2对应 write.csv2(df, file = "C:/Users/Administrator/Desktop/导出文件.csv") #指定编码 write.csv( df, file = "C:/Users/Administrator/Desktop/导出文件.csv", fileEncoding = "UTF-8" #导出文件编码 )
- 方法2:readr包
与read_XX函数一样,readr包提供write_XX函数。
#readr包 write_csv(df, path = "C:/Users/Administrator/Desktop/导出文件.csv") write_csv2(df, path = "C:/Users/Administrator/Desktop/导出文件.csv")
可惜的是,该系列函数不提供编码,在我的工作中,使用sql server导入数据并处理后(在R中无乱码情况),使用该函数导出数据,中文会出现乱码。原因不明,如果有哪位童靴知道的望告知。
为了解决上面的问题,我使用了该包的另一个函数。
#导出文件乱码解决方法 write_excel_csv(df, path = "C:/Users/Administrator/Desktop/导出文件.csv")
改用此函数导出数据,能够解决上面中文乱码的问题。
- 方法3:data.table包
data.table包也有对应的导出函数,同样的,使用sql server导入的数据,在导出的时候也出现了乱码,而该函数也无参数指定编码。
对于UTF-8编码的文件,使用该函数,速度是最快的。
#data.table包 fwrite(df, file = "C:/Users/Administrator/Desktop/导出文件.csv")
- readr包更为全面,推荐使用该包替换内置函数;
- data.table包速度最快,符合编码且数据量大可优先使用;
- Rstudio傻瓜式操作,但对中文不友好;
cancerData <- read.csv("cancer.csv",fileEncoding = "GBK", encoding = "GBK" )
注意:cancer.csv文件要放在主目录下

我们统计出男女个数并且用条形图来表示
res1 <- table(d.cancer[,'sex']); print(res1)
## sex
## F M
## 13 21
barplot(res1)

我们可以给表格增加标题,然后采用不同的颜色
barplot(res1, main="性别分布", col=c("brown2", "aquamarine1"))

R函数colors()可以返回R中定义的用字符串表示的六百多种颜色名字。 如head(colors(),6)

下面的函数可以用来挑选颜色, 鼠标点击画出的颜色就可以挑选, 结果返回挑选出的颜色名:
select.colors <- function(){nc <- length(colors())x <- rep(seq(26), 26)[1:nc]y <- rep(seq(26), each=26)[1:nc]cols <- colors()plot(x, y, type="p", pch=16, cex=2,col=cols)res <- cols[identify(x,y, labels=cols)]res
}
R语言sep函数
函数形式:rep(x, time = , length = , each = ,)
参数说明:
x:代表的是你要进行复制的对象,可以是一个向量或者是一个因子。
times:代表的是复制的次数,只能为正数。负数以及NA值都会为错误值。复制是指的是对整个向量进行复制。
each:代表的是对向量中的每个元素进行复制的次数。
length.out:代表的是最终输出向量的长度。
示例:
rep(1:4, 2) #对向量(1,2,3,4)复制两次
[1] 1 2 3 4 1 2 3 4
rep(1:4, each = 2) #对向量(1,2,3,4)中的每个元素复制两次
[1] 1 1 2 2 3 3 4 4
rep(1:4, each = 2, length.out = 4) #最后输出向量的长度为4
[1] 1 1 2 2
rep(x, …):将vector x的值循环n遍
rep(1:4, 2)
[1] 1 2 3 4 1 2 3 4
…: 除了x的其他参数,可以通过…传到其他方法里
times:整个数组循环几遍
rep(1:4, each = 2, times = 3)
[1] 1 1 2 2 3 3 4 4 1 1 2 2 3 3 4 4 1 1 2 2 3 3 4 4
each:每个element循环几遍
rep(1:4, each = 2) [1] 1 1 2 2 3 3 4 4 rep(1:4, c(2,2,2,2)) [1] 1 1 2 2 3 3 4 4 rep(1:4, c(2,1,2,1)) [1] 1 1 2 3 3 4
length.out 输出长度为多少
rep(1:4, each = 2, len = 4) [1] 1 1 2 2 #长了会被截掉 rep(1:4, each = 2, len = 13) [1] 1 1 2 2 3 3 4 4 1 1 2 2 3 #短了会根据前面规则补上
seq函数
seq()函数是产生等距间隔数列的函数,其使用格式为:
seq(from = 1, to = 1,by = ((to - from)/(length.out - 1)) ,length.out= NULL, length.out = NULL,...)
seq()函数中参数的名称、取值及意义
名称 取值及意义👇
from 数值,表示等间隔数列开始的位置,默认值为1
to 数值,表示等间隔数列结束的位置,默认值为1
by 数值,表示等间隔数列之间的间隔
length.out 数值,表示等间隔数列的长度
along.out 向量,表示产生的等间隔数列与向量具有相同的长度
注意:by, length.out 和along.with 3个参数只能输入一项。
> seq(0,1,length.out=11)[1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
> seq(1,9,by=2) [1] 1 3 5 7 9
> seq(1,9,by=pi) [1] 1.000000 4.141593 7.283185
> seq(10)[1] 1 2 3 4 5 6 7 8 9 10
我们运行了上述代码之后可以看到我们可以自行选择颜色

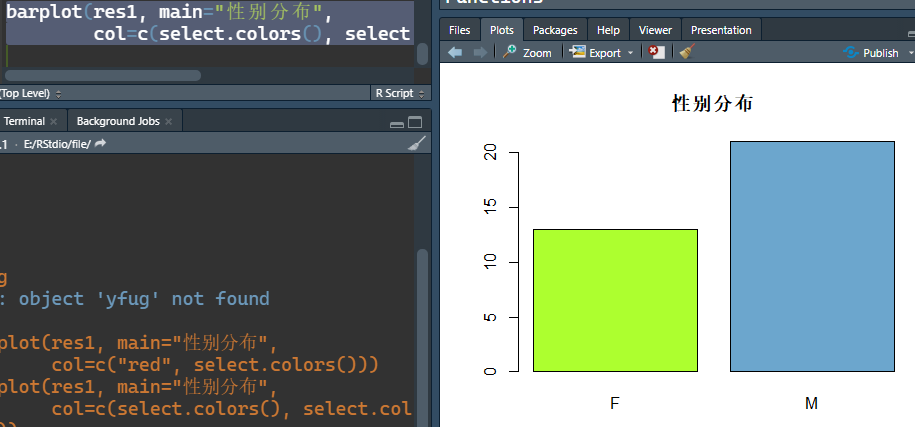
点击完两个颜色记得在命令行输入界面按esc退出,才可以显示出这个表格图
用width选项与xlim选项配合可以调整条形宽度,如
barplot(res1, width=0.5, xlim=c(-3, 5),main="性别分布", col=c("brown2", "aquamarine1"))

xlim可以用于plot函数作图,它的意思是xlim = c(<min>, <max>)。就是说缩放函数的x轴,范围在min与max之间。
经过我不断的试验,我发现F占据x轴的0位置,M占据x轴的1位置
hhh
按性别与病理类型交叉分组后统计频数,结果称为列联表:👇
res2 <- with(cancerData, table(sex, type)); res2

with函数
with()R语言中的函数用于通过评估函数参数内的表达式来修改 DataFrame 的数据。
用法: with(x, expr)
参数:
x: DataFrame
expr:修改数据的表达式
范例1:
# R program to modify data of an object# Calling predefined data set
BOD# Calling with() function
with(BOD, {BOD$demand <- BOD$demand + 1; print(BOD$demand)})
输出:
Time demand 1 1 8.3 2 2 10.3 3 3 19.0 4 4 16.0 5 5 15.6 6 7 19.8 [1] 9.3 11.3 20.0 17.0 16.6 20.8
范例2:
# R program to modify data of an object# Creating a data frame
df = data.frame( "Name" = c("abc", "def", "ghi"), "Language" = c("R", "Python", "Java"), "Age" = c(22, 25, 45)
)
df# Calling with() function
with(df, {df$Age <- df$Age + 10; print(df$Age)})
输出:
Name Language Age 1 abc R 22 2 def Python 25 3 ghi Java 45 [1] 32 35 55
用分段条形图表现交叉分组频数, 交叉频数表每列为一条:
barplot(res2, legend=TRUE)

这里的legend的意思就是需不需要加上标签名,

用并排条形图表现交叉分组频数, 交叉频数表每列为一组:
barplot(res2, beside=TRUE, legend=TRUE)

增加标题,指定颜色,调整图例位置,调整条形宽度:
barplot(res2, beside=TRUE, legend=TRUE,main='不同种类病人的性别',ylim=c(0, 20),xlim=c(-1, 6), width=0.6,col=c("brown2", "aquamarine1"))

直方图和密度估计图
用hist作直方图以了解连续取值变量分布情况.
例如,下面的程序模拟正态分布数据并做直方图:
x <- rnorm(30, mean=100, sd=1) print(round(x,2))

round函数
R 语言提供了一个内置函数 round(),它四舍五入到给定的位数,如果没有提供四舍五入的位数,它会将数字四舍五入到最接近的整数。
用法:round(x,digits=n)
参数:
x:要四舍五入的数字
digit:指定数字
范例1:
# R program to calculate round value # Using round() method answer1 <- round(2.356) answer2 <- round(2.356, digits = 2) answer3 <- round(2.5) answer4 <- round(2.5, digits = 1) print(answer1) print(answer2) print(answer3) print(answer4)
输出:
2
2.36
2
2.5
范例2:
# R program to calculate round value # Using round() method answer1 <- round(c(1.5, 2.6, -3, -3.4)) print(answer1)
输出:2 3 -3 -3
了解了round函数是怎么用的之后,我们回归上面的代码
x <- rnorm(30, mean=100, sd=1) print(round(x,2))
hist(x)

可以用main=、xlab=、ylab=等选项, 可以用col=指定各个条形的颜色,如:
hist(x, col=rainbow(15), main='正态随机数', xlab='', ylab='频数')
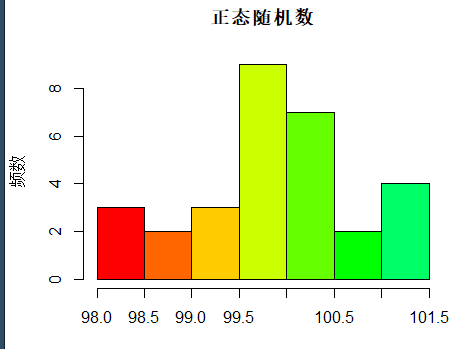
函数density()估计核密度。 下面的程序作直方图, 并添加核密度曲线:
tmp.dens <- density(x) hist(x, freq=FALSE,ylim=c(0,max(tmp.dens$y)),col=rainbow(15),main='正态随机数',xlab='', ylab='频数') lines(tmp.dens, lwd=2, col='blue')


density核密度
关于density作图详细教程建议大家看这篇博客👉R语言中density密度图绘制,这篇文章是用的ggplot2的package
盒型图
首先带大家介绍以下boxplot()函数
boxplot()
盒形图是数据集中数据分布情况的衡量标准。它将数据集分为三个四分位数。盒形图表示数据集中的最小值,最大值,中值,第一四分位数和第四四分位数。 通过为每个数据集绘制箱形图,比较数据集中的数据分布也很有用。
R中的盒形图通过使用boxplot()函数来创建。
语法
在R中创建盒形图的基本语法是
boxplot(x, data, notch, varwidth, names, main)
以下是使用的参数的描述 -
- x - 是向量或公式。
- data - 是数据帧。
- notch - 是一个逻辑值,设置为TRUE可以画出一个缺口。
- varwidth - 是一个逻辑值。设置为true以绘制与样本大小成比例的框的宽度。
- names - 是将在每个箱形图下打印的组标签。
- main - 用于给图表标题。
示例
我们用一个数据集 mtcars来创建一个基本的盒型图
下面我们首先看看mtcars数据集中的mpg和cyl列
input <- mtcars[,c('mpg','cyl')]
print(head(input))
注:这个数据集是R语言中已经存在的,大家可以直接利用
当我们执行上面的代码,它产生以下结果👇
> print(head(input))mpg cyl Mazda RX4 21.0 6 Mazda RX4 Wag 21.0 6 Datsun 710 22.8 4 Hornet 4 Drive 21.4 6 Hornet Sportabout 18.7 8 Valiant 18.1 6
创建盒型图
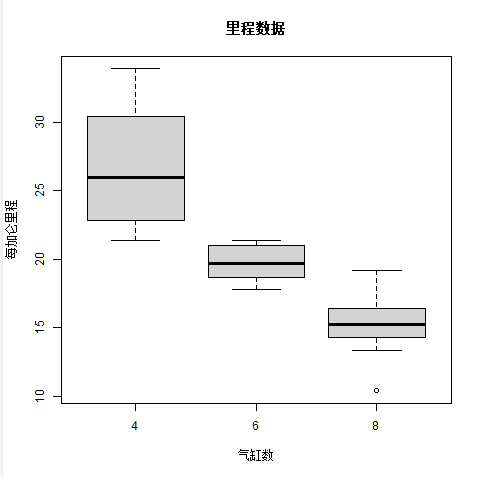
下面的脚本将为mgp(每加仑英里)和cyl(气缸数)列之间的关系创建一个盒型图.
# Give the chart file a name. png(file = "boxplot.png")# Plot the chart. boxplot(mpg ~ cyl, data = mtcars, xlab = "气缸数",ylab = "每加仑里程", main = "里程数据")# Save the file. dev.off()


盒型图与凹口
我们可以绘制带有凹槽的盒形图,以了解不同数据组的中位数如何相互匹配。以下脚本将为每个数据组创建一个带有凹槽的盒形图形。
# Give the chart file a name.
png(file = "boxplot_with_notch.png")
#这个图片文件将存放在你的工作目录# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars, xlab = "气缸数",ylab = "每加仑里程", main = "里程数据",notch = TRUE, varwidth = TRUE, col = c("green","yellow","purple"),names = c("高","中","低")
)
# Save the file.
dev.off()

OK,学会了boxplot的基本运用,我们来看一些其他的运用
盒型图用于简洁得查看表现变量分布,如👇
with(cancerData, boxplot(v0))

其中中间粗线是中位数, 盒子上下边缘是四分之三和四分之一分位数, 两条触须线延伸到取值区域的边缘。
盒形图可以很容易地比较两组或多组,如👇
with(cancerData, boxplot(v0 ~ sex))

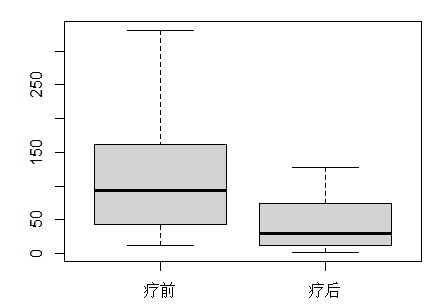
也可以画若干个变量的并排盒形图,如👇
with(cancerData,boxplot(list('疗前'=v0, '疗后'=v1)))
正态QQ图
QQ图是一种散点图,对应于正态分布的QQ图,就是由标准正态分布的分位数为横坐标,样本值为纵坐标的散点图(其他版本,有将 (x-m)/std 作为纵坐标,那么正态分布得到的散点图是直线:y=x)。要利用QQ图鉴别样本数据是否近似于正态分布,只需看QQ图上的点是否近似地在一条直线附近,图形是直线说明是正态分布,而且该直线的斜率为标准差,截距为均值,用QQ图还可获得样本偏度和峰度的粗略信息。
如果样本是按正态分布的,那么f(x)即是一个正态分布的概率密度函数。根据正态分布的特性,我们又可以推导出对应的标准正态分布的概率密度函数:y = f( (x-m)/std )其中m为样本均值(截距),std为样本标准差(斜率)。
设标准正态分布的概率密度函数为 y= f(n),既然这些值一一对应,则有:
(x-m)/std=n
即:x=n*std+m
这是一条斜率为样本标准差,截距为m的直线,就是在q-q图中代表着正态分布的直线。
用qqnorm和qqline作正态QQ图。 当变量样本来自正态分布总体时, 正态QQ图的散点近似在一条直线周围。


下面的程序模拟正态分布随机数,并作正态QQ图:
qqnorm(x) qqline(x, lwd=2, col='blue')

下面的程序模拟对数正态数据,并作正态QQ图:
z <- 10^rnorm(30, mean=0, sd=0.2) qqnorm(z) qqline(z, lwd=2, col='blue')

散点图
我们读入class.csv,以d.class数据为例,其中含有name,sex,age,height,weight等变量.
d.class <- read.csv("class.csv")
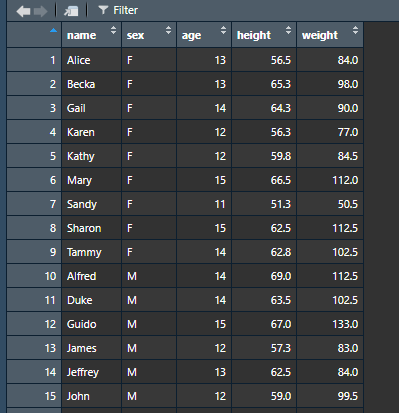
class.csv
体重对身高的散点图
plot(d.class$height,d.class$weight)
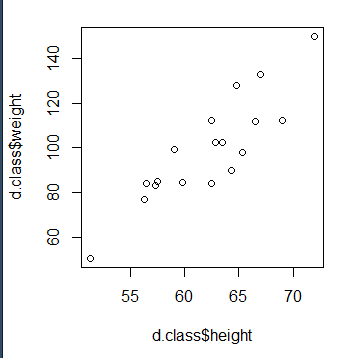
接下来我们用with()函数来简化数据框变量的访问格式
with(d.class,plot(height,weight))
得出的图跟上面一张图是一样的
我们在plot()函数内用main参数来增加一个标题
用xlab参数来指定横轴标注,用ylab参数指定纵轴标注,如:
with(d.class,plot(height,weight,main = '体重与身高关系',xlab='身高',ylab='体重'))

然后我们再用pch参数来指定不同散点形状,用col参数来指定颜色,用cex参数指定大小,如下👇
with(d.class,plot(height,weight,pch=16,col='blue',cex=2 ))

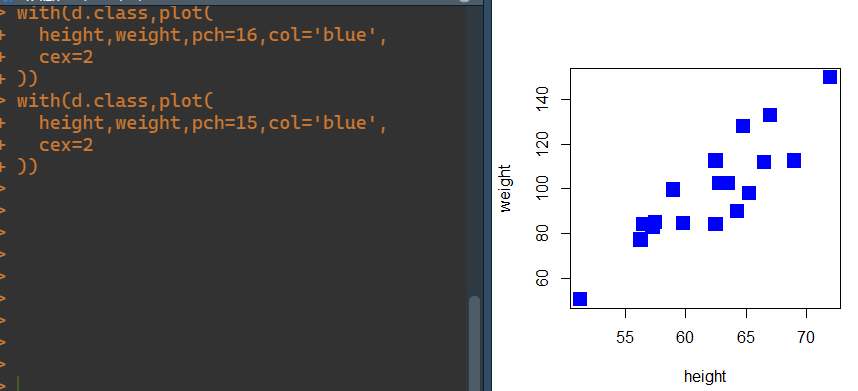
我们如果将pch改为15的话,图上的点就会变成正方形
用气泡大小表现第三维(年龄):
with(d.class,plot(height, weight,pch=16, col='blue',cex=1 + (age - min(age))/(max(age)-min(age))))
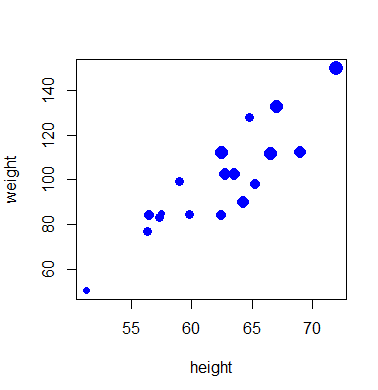
用气泡大小表现年龄, 用颜色区分性别:
with(d.class, plot(height, weight,main='体重与身高关系',xlab='身高', ylab='体重',pch=16, col=ifelse(sex=='M', 'blue', 'red'),cex=1 + (age - min(age))/(max(age)-min(age))))

这里我用select自己选了两个颜色,代码在上面已经展示过了

pairs()散点矩阵图
pairs(d.class[, c('age', 'height', 'weight')])

曲线图
curve()
curve 函数常用于绘制函数对应的曲线,确定函数的表达式,以及对应的需要展示的起始坐标和终止坐标,curve函数就会自动化的绘制在该区间内的函数图像
基本用法,代码示例:
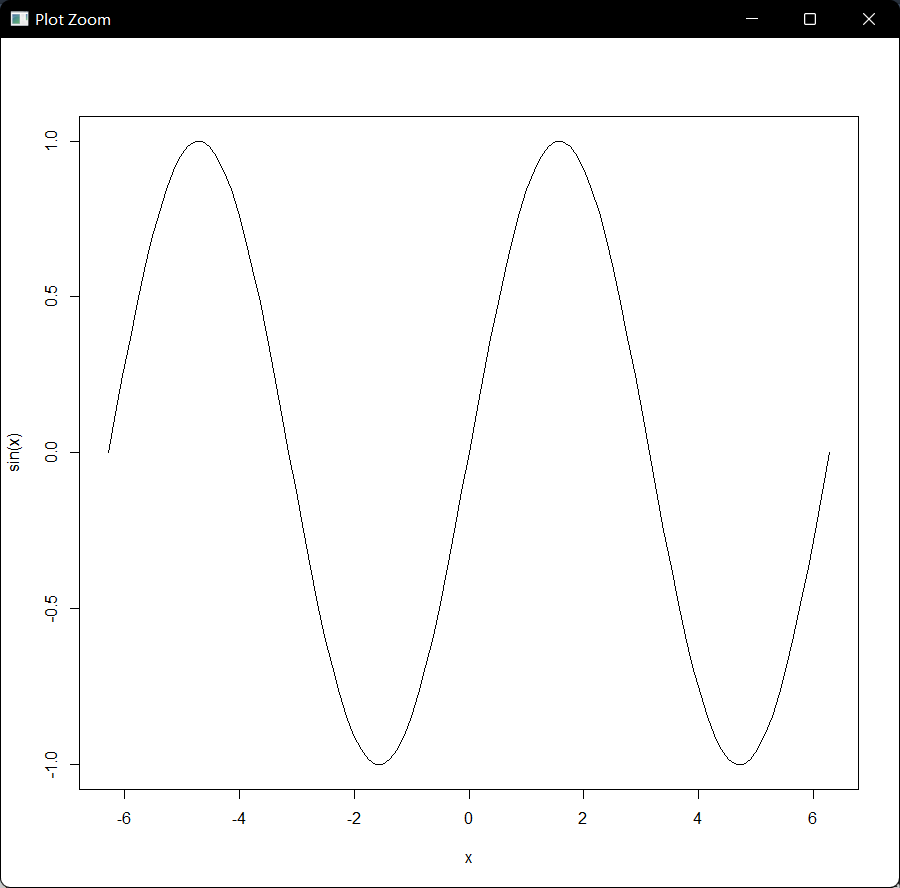
curve(sin, -2*pi, 2*pi)

第一个参数为函数的名称,这里我们选择的是sin 三角函数,后两个参数为对应的起始和终止区间
下面详细解释一下每个参数:
1) expr : 对应的函数名称,这个参数的值可以有3中写法:
第一种: 函数的名称
代码示例:
# y = 2x + 1
coef_line <- function(x){2 * x + 1
}curve(expr = coef_line, from = 1, to = 3)

这里我们先定义了一个函数coef_line , 然后将函数名称传递给curve
第二种:expression
代码示例:
curve(expr = 2 * x + 1, from = 2 , to = 6)

这里的2 * x + 1 就是一个表达式 expression
第三种: call, 函数调用
代码示例:
# y = 2x + 1
coef_line <- function(x){2 * x + 1
}x <- 1:5
curve(expr = coef_line(x), from = 2, to = 6)
效果图和上面的是一样的
这里我们调用函数coef_line 去处理x 这个对象
2)from, to : 自变量x的起始和终止位置,这个用法很简单,就不详细解释了
3)xname : x 轴的标签, 这里参数只有当传递进来的是函数名称时,才能运行
代码示例:
# y = 2x + 1
coef_line <- function(x){2 * x + 1
}curve(expr = coef_line, from = 2, to = 6, xname = "X Var")

curve()函数接收一个函数,或者一个以x为变量的表达式,以及曲线的自变量的左右端点,绘制函数或者表达式的曲线图,如:
curve(1 - 3*x - x^2, -4 ,2)

又比如
curve(sin,-2*pi ,2*pi)
这里再为大家详细得介绍一下plot函数的运用
plot()函数
plot是R中的基本画图工具,直接plot(x),x为一个数据集,就能画出图。细节往往制胜的关键,所以就详细来看下plot的所有可设置参数及参数设置方法。
下面讲到的图形参数,是graphic包中的常见参数,graphic不同图形方法中,这些参数都是相同的。
- 符号和线条
pch指定图形(在type=”p”/”o”/”b”时)

可加cex参数,用来控制图中的符号大小,默认为cex=1
当PCH为21-25时,应指定参数“col =”和“bg =”。PCH也可以是字符,例如“#”,“%”,“A”,“a”,并且字符将被绘制

lty指定线形;lwd改变线条粗细👇

- type图形的类型
“p”点图
“l”线图
“b”点线图,线不穿过点
“c”虚线图
“o”点线图,线穿过点
“h”直方图
“s”阶梯图
“S”步骤图
“n”无图
x<-c(1:10)
png("~/plotSamples.png",width=9,height=9,unit="in",res=108)
#在工作目录下创建plotSamples.png图
par(mfcol=c(3,3))#下面会讲到
plot(x,type="p",main="p")
plot(x,type="l",main="l")
plot(x,type="b",main="b")
plot(x,type="c",main="c")
plot(x,type="o",main="o")
plot(x,type="h",main="h")
plot(x,type="s",main="s")
plot(x,type="S",main="S")
plot(x,type="n",main="n")
dev.off()

- 颜色
col:默认绘图颜色。某些函数(如lines、pie)可以接受一个含有颜色值的向量,并自动循环使用.
例如:col=c("red", "blue")需要绘制三条线,那么三条颜色分别为red、blue、red
col.axis:坐标轴刻度文字的颜色,不是坐标轴的颜色
col.lab:坐标轴标签(名称)的颜色
col.main:标题的颜色
col.sub:副标题的颜色
fg:图形的前景色
bg:图形的背景色
col指定图形颜色
colors()方法可以查看R中所有可用的颜色名,一共有657种颜色名,根据颜色名可直接设置图形的显示颜色。下面是部分颜色,完整的图见链接:R语言颜色表
除了名称外,同样可以用下标,十六进制颜色值,RGB值和HSV值来指定颜色。例子:col=1、col="white"、col="#FFFFFF"、col=rgb(1,1,1)和col=hsv(0,0,1)。
另外,R中还有许多生成颜色变量的函数。有rainbow()、heat.colors()、terrain.colors()、topo.colors()、cm.colors()方法,gray()方法生成多阶灰度色。
我们在plot函数中使用type='l'参数也可以作曲线图,比如
x <- seq(0, 2*pi, length=200) y <- sin(x) plot(x,y, type='l')

除了这些,还可以用main, xlab, ylab, col等参数, 用lwd指定线宽度, lty指定虚线,如
plot(x,y, type='l', lwd=5, lty=8)

如果有多条曲线的话,我们可以用matplot()函数,比如
x <- seq(0, 2*pi, length=200)
y1 <- sin(x)
y2 <- cos(x)
matplot(x, cbind(y1, y2), type='l', lty=1, lwd=2, col=c("red", "blue"),xlab="x", ylab="")
abline(h=0, col='gray')

abline()函数
abline 函数的作用是在一张图表上添加直线, 可以是一条斜线,通过x或y轴的交点和斜率来确定位置;也可以是一条水平或者垂直的线,只需要指定与x轴或y轴交点的位置就可以了
常见用法:
1)添加直线
水平线:
通过h 参数设置直线与y轴的交点就可以了,代码示例如下:
plot(1:5, 1:5, xlim = c(0,6), ylim = c (0,6)) abline(h = 0, col = "red")
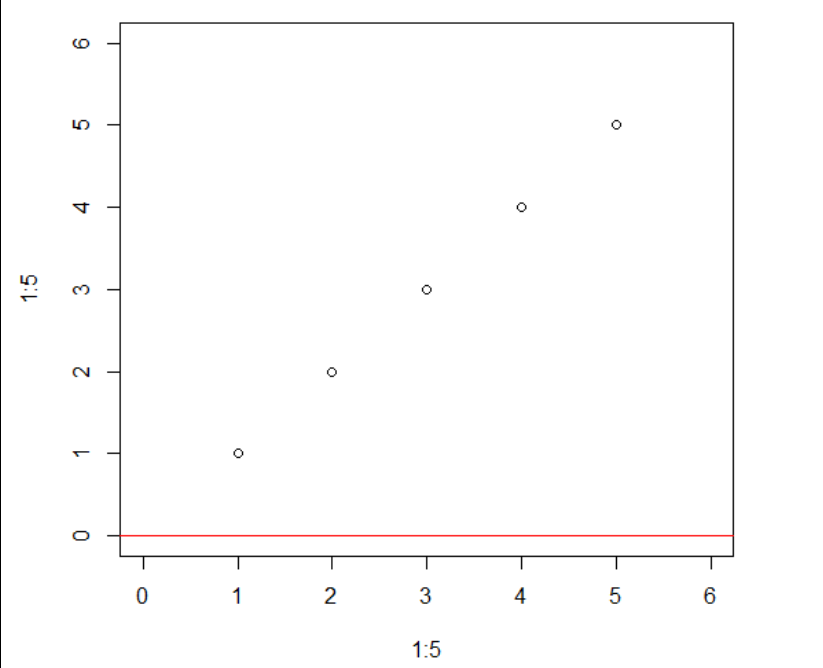
垂直线:
通过v 参数设置直线与x轴的交点就可以了,代码示例如下:
plot(1:5, 1:5, xlim = c(0,6), ylim = c (0,6)) abline(v = 0, col = "blue")

除了上述的基本用法之外,h和v参数还支持同时设置多个值,一次性可以画多条直线,代码示例如下:
plot(1:5, 1:5, xlim = c(0,6), ylim = c (0,6))
abline(h = c(0,1,2), v = c(0,1,2), col = c("red", "green", "blue"))

2)添加斜线
abline 函数添加斜线有两种用法:
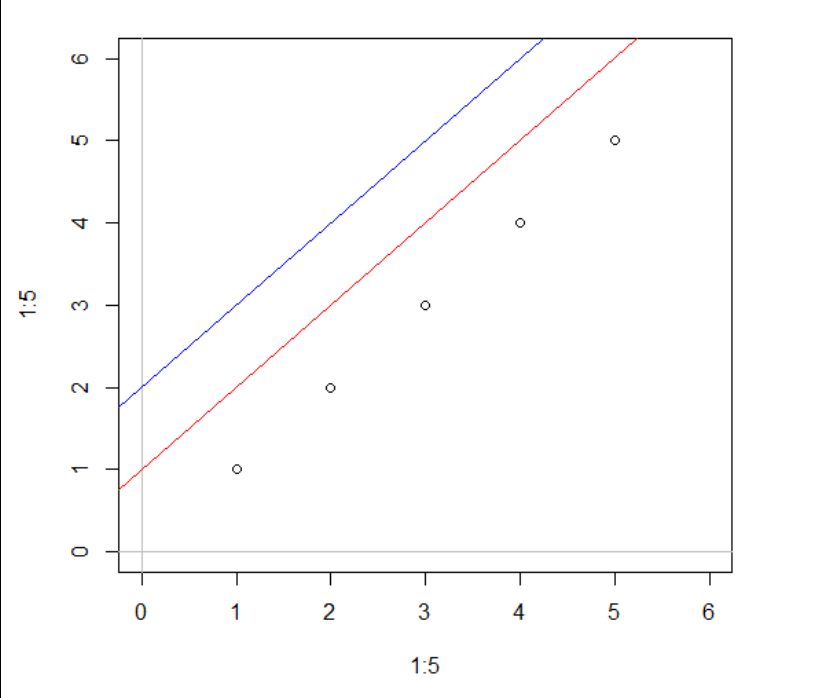
第一种分别指定交点和斜率的值,参数 a 代表直线与y轴的交点距坐标原点的位置,参数 b 代表斜率, 代码示例如下:
plot(1:5, 1:5, xlim = c(0,6), ylim = c (0,6)) abline(h = 0, col = "gray") abline(v = 0, col = "gray") abline(a = 1 , b = 1, col = "red") abline(a = 2 ,b = 1, col = "blue")

第二种通过一个长度为2的向量同时指定交点与原点的距离和斜率,代码示例如下:
plot(1:5, 1:5, xlim = c(0,6), ylim = c (0,6)) abline(h = 0, col = "gray") abline(v = 0, col = "gray") abline(coef = c(1, 1), col = "red") abline(coef = c(2, 1), col = "blue")
对于线条来说,有许多的属性,比如颜色,线条类型,线条粗细等,在abline 函数中也是可以对这些属性进行设置的
- col : 线条的颜色
- lty : 线条的类型
- lwd : 线条的宽度
这些属性的设置都很简单,举一个例子:
plot(1:5, 1:5, xlim = c(0,6), ylim = c (0,6)) abline(v = 0, col = "gray", lwd = 2, lty = 2)

上述的都是基本用法,其实还有一种用法,可以添加一条回归线,对于一元线性回归来说,回归表达式就是一条直线的公式,abline 函数可以直接利用回归结果进行作图
代码如下:
z <- lm(dist ~ speed, data = cars) plot(cars) abline(z)

curve的运用
curve(expr, from = NULL, to = NULL, n = 101, add = FALSE, type = "l", xname = "x", xlab = xname, ylab = NULL, log = NULL, xlim = NULL, ...)
主要参数如下:
expr:函数名称或一个关于变量x的函数表达式;
from,to:表示绘图的起止范围;
n:一个整数值,表示x取值的数量;
add:是一个逻辑值,当为TRUE时,表示将绘图添加到已存在的绘图中;
type:与plot函数中type含义相同;
xname:用于x轴变量的名称。
xlab,ylab:x轴和y轴的标签名称。
三维图
用persp函数作三维曲面图, contour作等值线图, image作色块图。 坐标x和y构成一张平面网格, 数据z是包含z坐标的矩阵,每行对应一个横坐标, 每列对应一个纵坐标。
下面的程序生成二元正态分布密度曲面数据:
x <- seq(-3,3, length=100)
y <- x
f <- function(x,y,ssq1=1, ssq2=2, rho=0.5){det1 <- ssq1*ssq2*(1 - rho^2)s1 <- sqrt(ssq1)s2 <- sqrt(ssq2)1/(2*pi*sqrt(det1)) * exp(-0.5 / det1 * (ssq2*x^2 + ssq1*y^2 - 2*rho*s1*s2*x*y))
}
z <- outer(x, y, f)
作二元正态密度函数的三维曲面图、等高线图、色块图:
persp(x, y, z)
三维曲面图:👇

等高线图:
contour(x, y, z)

色块图:👇
image(x,y,z)

动态三维图
rgl包能够制作动态的三维散点图和曲面图
library(rgl)
iris数据框包含了3种鸢尾花的各50个样品的测量值, 测量值包括花萼长、宽, 花瓣长、宽。 用rgl的plot3d()作动态三维散点图如下:
with(iris, plot3d(Sepal.Length, Sepal.Width, Petal.Length, type="s", col=as.numeric(Species)))
这个图可以用鼠标拖动旋转。 其中type="s"表示绘点符号是球体形状。 还可选"p"(点)、"l"(连线)、"h"(向z=0连线)。 可以用size=指定大小倍数(缺省值为3)。
用rgl的persp3d()函数作曲面图。 如 二元正态分布密度曲面:
x <- seq(-3,3, length=100)
y <- x
f <- function(x,y,ssq1=1, ssq2=2, rho=0.5){det1 <- ssq1*ssq2*(1 - rho^2)s1 <- sqrt(ssq1)s2 <- sqrt(ssq2)1/(2*pi*sqrt(det1)) * exp(-0.5 / det1 * (ssq2*x^2 + ssq1*y^2 - 2*rho*s1*s2*x*y))
}
z <- outer(x, y, f)
persp3d(x=x, y=y, z=z, col='red')
rgl也有低级图形函数支持向已有图形添加物体、文字等, 也支持并列多图。 适当设置可以在R Markdown生成的HTML结果中动态显示三维图。
低级图形函数
abline()
上面为了方便理解已经介绍过一次
用points函数增加散点,如:
x <- seq(0, 2*pi, length=200) y <- sin(x) special <- list(x=(0:4)*pi/2, y=sin((0:4)*pi/2)) plot(x, y, type='l') points(special$x, special$y, col="red", pch=16, cex=2) points(special, col="red", pch=16, cex=2)
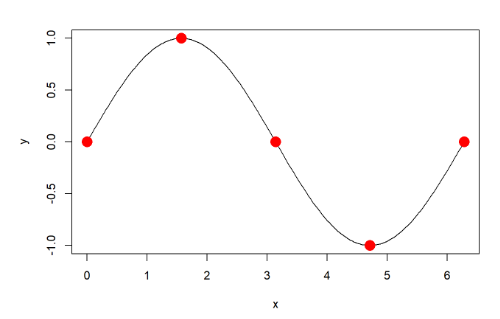
lines()
用lines函数增加曲线,如:
x <- seq(0, 2*pi, length=200) y1 <- sin(x) y2 <- cos(x) plot(x, y1, type='l', lwd=2, col="red") lines(x, y2, lwd=2, col="blue") abline(h=0, col='gray')

legand()增加图例
可以用legend函数增加标注,如:
x <- seq(0, 2*pi, length=200)
y1 <- sin(x)
y2 <- cos(x)
plot(x, y1, type='l', lwd=2, col="red")
lines(x, y2, lwd=2, col="blue")
abline(h=0, col='gray')
legend(0, -0.5, col=c("red", "blue"),lty=c(1,1), lwd=c(2,2), legend=c("sin", "cos"))

x <- seq(0, 2*pi, length=200)
y1 <- sin(x)
y2 <- cos(x)
plot(x, y1, type='l', lwd=2, col="red")
lines(x, y2, lwd=2, col="blue")
abline(h=0, col='gray')
legend('top', col=c("red", "blue"),lty=c(1,1), lwd=c(2,2), legend=c("sin", "cos"))
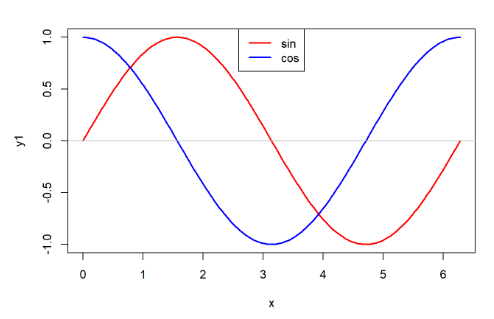
axis()坐标轴
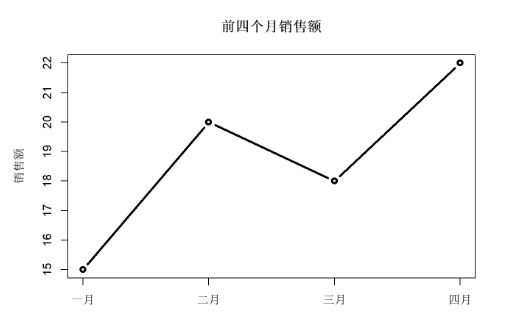
在plot()函数中用 axes=FALSE可以取消自动的坐标轴。 用box()函数画坐标边框。 用axis函数单独绘制坐标轴。 axis的第一个参数取1,2,3,4, 分别表示横轴、纵轴、上方和右方。 axis的参数at为 刻度线位置,labels为标签。 如:
x <- c('一月'=15, '二月'=20, '三月'=18, '四月'=22)
plot(seq(along=x), x, axes=FALSE,type='b', lwd=3,main='前四个月销售额',xlab='', ylab='销售额')
box(); axis(2)
axis(1, at=seq(along=x), labels=names(x))
R基本绘图支持少量的数学公式显示功能,如不用数学符号时:
x <- seq(0, 2*pi, length=200)
y1 <- sin(x)
plot(x, y1, type='l', lwd=2,axes=FALSE,xlab='x', ylab='')
abline(h=0, col='gray')
box()
axis(2)
axis(1, at=(0:4)/2*pi,labels=c('0', 'pi/2', 'pi', '3pi/2', '2pi'))

使用数学符号时:
x <- seq(0, 2*pi, length=200) y1 <- sin(x) plot(x, y1, type='l', lwd=2,axes=FALSE,xlab='x', ylab='') abline(h=0, col='gray') box() axis(2) axis(1, at=(0:4)/2*pi,labels=c(0, expression(pi/2), expression(pi), expression(3*pi/2), expression(2*pi)))
绘图中使用数学符号的演示:
demo(plotmath)

text()给图内区域添加文字
text()在坐标区域内添加文字。 mtext()在边空处添加文字。 如
with(d.class, plot(height, weight)) lm1 <- lm(weight ~ height, data=d.class) abline(lm1, col='red', lwd=2) a <- coef(lm1)[1] b <- coef(lm1)[2] text(52, 145, adj=0, '线性回归:') text(52, 140, adj=0,substitute(hat(y) == a + b*x,list(a=round(coef(lm1)[1], 2), b=round(coef(lm1)[2], 2))))

locator()和identify()
locator()函数在执行时等待用户在图形的坐标区域内点击并返回点击处的坐标。 可以用参数n指定要点击的点的个数。 不指定个数则需要用右键菜单退出。 这个函数也可以用来要求用户点击以进行到下一图形。
x <- seq(0, 2*pi, length=200)
y1 <- sin(x); y2 <- cos(x)
plot(x, y1, type='l',col="red")
lines(x, y2, col="blue")
legend(locator(1), col=c("red", "blue"),lty=c(1,1), legend=c("sin", "cos"))
identify()可以识别点击处的点并标注标签, 格式为identify(x, y, labels), 其中(x,y)给出可点击的点的坐标, labels是每个点对应的标签, 点击那个点就在那个点旁边标对应的标签。
图形的参数
用图形参数可以选择点的形状、颜色、线型、粗细、坐标轴做法、边空、一页多图等。 有些参数直接用在绘图函数内,如plot函数可以用 pch、col、cex、lty、 lwd等参数。 有些图形参数必须使用par()函数指定。 par函数指定图形参数并返回原来的参数值, 所以在修改参数值作图后通常应该恢复原始参数值, 做法如
opar <- par(mfrow=c(2,2))
with(d.class, {hist(height);boxplot(height);qqnorm(height); qqline(height);plot(height); rug(height,side=2)})
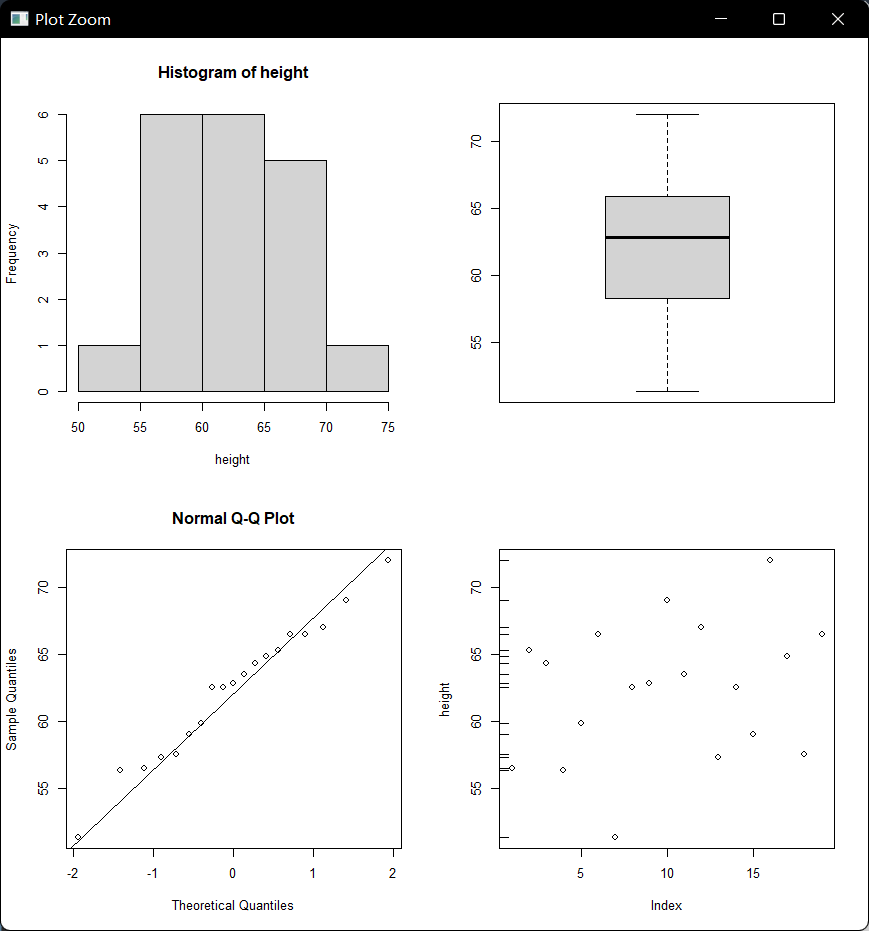
par(opar)
在函数内,可以在函数开头修改了图形参数后, 用on.exit()函数将恢复原始图形参数作为函数退出前必须完成的任务,如
f <- function(){opar <- par(mfrow=c(2,2)); on.exit(par(opar))with(d.class,{hist(height);boxplot(height);qqnorm(height); qqline(height);plot(height); rug(height,side=2)})
}
f()
例子:用图形参数解决barplot图形横坐标值过宽
barplot的横坐标标注太宽时,自动将某些标注省略。 用las=2指定坐标轴刻度标签垂直于坐标轴, 这样x轴的刻度值就变成了纵向的。 注意使用mar参数增加横坐标边空大小。 例如
f <- function(){opar <- par(mar=c(8, 4, 2, 0.5)); on.exit(par(opar))x <- 1:10names(x) <- paste(10000000000 + (1:10))barplot(x, las=2)
}
f()

图形元素控制
- pch=16参数。散点符号,取的数。
- lty=2参数。线型,1为实线,从2开始为各种虚线。
- lwd=2参数,线的粗细,标准粗细为1。
- col="red"参数,颜色,可以是数字, 或颜色名字符串如"red","blue"等。 用colors()函数查询有名字的颜色。 用rainbow(n)函数产生连续变化的颜色。
- font=2参数,字体,一般font=1是正体,2是粗体, 3是斜体,4是粗斜体。
- adj=-0.1指定文本相对于给定坐标的对齐方式。 取0表示左对齐,取1表示右对齐,取0.5表示居中。 此参数的值实际代表的是出现在给定坐标左边的文本的比例。
- cex=1.5 绘点符号大小倍数,基本值为1。
坐标轴与坐标刻度
- mgp=c(3,1,0) 坐标轴的标签、刻度值、坐标轴线 到实际的坐标轴位置的距离,以行高为单位。 经常用来缩小坐标轴所占的空间, 如mgp=c(1.5, 0.5, 0)。
- lab=c(5,7,12) 提供刻度线多少的建议, 第一个数为x轴刻度线个数, 第二个数为y轴刻度线个数, 第三个数是坐标刻度标签的字符宽度。
- las=1 坐标刻度标签的方向。 0表示总是平行于坐标轴, 1表示总是水平, 2表示总是垂直于坐标轴。
- tck=0.01 坐标轴刻度线长度,以绘图区域大小为单位1。
- xaxs="s", yaxs="e": 控制x轴和y轴标刻度的方法。取"s"(即standard)或"e"(即extended) 的时候数据范围控制在最小刻度和最大刻度之间。 取"e"时如果有数据点十分靠近边缘轴的范围会略微扩大。取值为"i"(即internal)或"r"(此为缺省) 使得刻度线都落在数据范围内部,而"r"方式所留的边空较小。取值设为"d"时会锁定此坐标轴, 后续的图形都使用与它完全相同的坐标轴, 这在要生成一系列可比较的图形的时候是有用的。 要解除锁定需要把这个图形参数设为其它值。
图形边空
一个单独的图由绘图区域(绘图的点、线等画在这个区域中)和包围绘图区域的边空组成, 边空中可以包含坐标轴标签、坐标轴刻度标签、标题、小标题等, 绘图区域一般被坐标轴包围。

边空的大小由mai参数或mar参数控制, 它们都是四个元素的向量, 分别规定下方、左方、上方、右方的边空大小, 其中mai取值的单位是英寸, 而mar的取值单位是文本行高度。 例如:
边空的大小由mai参数或mar参数控制, 它们都是四个元素的向量, 分别规定下方、左方、上方、右方的边空大小, 其中mai取值的单位是英寸, 而mar的取值单位是文本行高度。 例如:
opar <- par(mar=c(2,2,0.5,0.5), mgp=c(0.5, 0.5, 0), tck=0.005) with(d.class, plot(height, weight, xlab='', ylab=''))

par(opar)
一页多图
R可以在同一页面开若干个按行、列排列的窗格, 在每个窗格中可以作一幅图。 每个图有自己的内边空, 而所有图的外面可以包一个“外边空”。

一页多图用mfrow参数或mfcol参数规定。 用oma指定四个外边空的行数。 用mtext加outer=T指定在外边空添加文本。 如果没有outer=T则在内边空添加文本。 如
opar <- par(mfrow=c(2,2),oma=c(0,0,2,0))
with(d.class, {hist(height);boxplot(height);qqnorm(height); qqline(height);plot(height); rug(height,side=2)})
mtext(side=3, text='身高分布', cex=2, outer=T)

par(opar)
图形输出
只要启用了高级绘图函数会自动选用当前绘图设备, 缺省为屏幕窗口。
PDF输出
用pdf函数可以指定输出到PDF文件。如
pdf(file='fig-hw.pdf', height=10/2.54,width=10/2.54, family='GB1') with(d.class, plot(height, weight,main='体重与身高关系')) dev.off()
用dev.off()关闭当前设备并生成输出文件 (如果是屏幕窗口则没有保存结果)。
PNG输出
png(file='fig-hw.png', height=1000, width=1000) with(d.class, plot(height, weight,main='体重与身高关系')) dev.off()
类似地, 用jpeg()函数启用JPEG图形设备, 用bmp()函数启用BMP图形设备, 用postscript()函数启用PostScript图形设备。
包含多种中文字体的图形
为了使用MS Windows系统字体, 一种办法是安装showtext包。 该包替换画图时的添加文本函数命令, 把文本内容替换成多边形(PDF或PS图)或点阵(点阵图)。
需要的工作:
- 查看Windows的font目录内容,看文件名与字体名的对应关系。 下面的程序中的列表是我的中文Windows 10的部分中文字体。
- 找到自己希望使用的中文字体的文件名。
- 用font.add()命令,增加一套自定义字体family, 一套中可以指定四种:常规(regular), 粗体(bold), 斜体(italic), 粗斜体(bolditalic)
- 程序中调入showtext包并运行showtext.auto()命令,这个命令使得文本命令采用showtext包
- 用par(family=)指定自定义的字体family。
- 作图(主要是PDF)。关闭图形设备。
test.chinese <- function(){require(showtext); showtext.auto()## 建立文件名到字体名对照表fmap <- c('msyh'='微软雅黑常规','msyhbd'='微软雅黑粗体','msyhl'='微软雅黑细体','simsun'='宋体','simfang'='仿宋','simkai'='楷体','simhei'='黑体','SIMLI'='隶书','SIMYOU'='幼圆','STSONG'='华文宋体','STZHONGS'='华文中宋','STFANGSO'='华文仿宋','STKAITI'='华文楷体','STXIHEI'='华文细黑','STLITI'='华文隶书','STXINGKA'='华文行楷','STXINWEI'='华文新魏','STCAIYUN'='华文彩云','STHUPO'='华文琥珀')fmapr <- names(fmap); names(fmapr) <- unname(fmap)cat('==== 字体文件名与字体名称对应:\n')print(fmap)cat('==== 字体名与字体文件名对应:\n')print(fmapr)## 找到某个字体的字体文件## font.name是字体名称find.font <- function(font.name){fname <- fmapr[font.name]flist0 <- font.files()flist1 <- sapply(strsplit(flist0, '[.]'), function(it) it[1])flist0[flist1==fname]}ff1 <- find.font('宋体')ff2 <- find.font('黑体')ff3 <- find.font('仿宋')ff4 <- find.font('隶书');font.add('cjk4',regular=ff1,bold=ff2,italic=ff3,bolditalic=ff4)##browser()pdf('test-chinese.pdf'); on.exit(dev.off())par(family='cjk4')plot(c(0,1), c(0,1), type='n',axes=FALSE, xlab='', ylab='')text(0.1, 0.9, '正体', font=1)text(0.1, 0.8, '粗体', font=2)text(0.1, 0.7, '斜体', font=3)text(0.1, 0.6, '粗斜体', font=4)
}
test.chinese()
注意:图形参数font=1表示正体, font=2表示粗体, font=3表示斜体, font=4表示粗斜体。
其他图形
相关系数图
用cor(x)可以计算数据框x的各列的相关系数阵。 corrgram包的corrgram()函数可以将相关系数阵用图形表示, 系数绝对值大小用色块颜色深浅表示, 正负用两种颜色区分。
例如, 计算iris数据框中四个测量值的相关系数并用矩阵表示:
library(corrgram) R.iris <- cor(iris[,1:4]) print(round(R.iris, 2))
## Sepal.Length Sepal.Width Petal.Length Petal.Width ## Sepal.Length 1.00 -0.12 0.87 0.82 ## Sepal.Width -0.12 1.00 -0.43 -0.37 ## Petal.Length 0.87 -0.43 1.00 0.96 ## Petal.Width 0.82 -0.37 0.96 1.00
corrgram(R.iris, order=TRUE, lower.panel=panel.shade,upper.panel = panel.pie,text.panel = panel.txt )

左下方用颜色代表正负相关, 蓝色为正相关,红色为负相关, 可以看出花萼长(Sepal.Length)、花瓣宽(Petal.Width)和花瓣长(Petal.Length)相互为较强的正相关, 但是花萼宽与其它三个变量为负相关。 这个相关结果实际是虚假的, 因为样本不是单一总体而是来自三个总体。 图形右上方用阴影部分大小和颜色深度代表相关系数绝对值, 用颜色区分正负。
下一篇文章带大家着重分析ggplot的运用
希望能够帮助到你