1.了解 R 的基础知识
R 是一种编程语言,可用于在数据分析过程的每个阶段执行任务。在这部分课程中,您将了解 R 和 RStudio,这是 R 的集成开发人员环境 (IDE)。您将探索使用 RStudio 与 R 一起工作的好处。RStudio 使您能够轻松利用 R 的特性和功能.
使用编程语言来处理你的数据有三个主要好处。你可以轻松地复制和分享你的工作,节省时间,并明确你的分析步骤。
您将要安装的 lubridate 软件包是tidyverse的一部分。tidyverse 是 R 语言包的集合,具有用于数据操作、探索和可视化的通用设计理念。对于很多数据分析师来说,tidyverse 是必不可少的工具。稍后您将在本课程中了解有关 tidyverse 的更多信息。
要安装核心 tidyverse 包并加载它们,请按照下列步骤操作:
- 在控制台底部,输入install.packages(“tidyverse”)并按Enter (Windows) 或Return (Mac)。
- 使用library()函数加载 tidyverse 库。要加载核心 tidyverse,请键入library(tidyverse)并按Enter (Windows) 或Return (Mac) 。
- 加载润滑包。在控制台窗格中键入 library(lubridate),然后按Enter (Windows) 或Return (Mac)。
2.使用 RStudio 编程
在这部分课程中,您将探索与 R 相关的基本概念。您将了解可在计算和其他编程中使用的函数和变量。您还将了解 R 包,它们是您可以在 RStudio 中使用的 R 函数、代码和示例数据的集合。
Rstudio中变量命名只能以字母开头
2.1了解基本的编程概念
2.1.1R中的向量和列表
广义的向量包括两种:「atomic vector」 和 「List」 (列表)
原子向量
早些时候,你了解到向量是一组具有相同类型的数据元素,在R中以序列形式存储。
有六种主要的原子向量类型:逻辑logical、整数integer、双数double、字符(包含字符串character (which contains strings),)、复数complex和原始raw。最后两种–复数和原始–在数据分析中并不常见,所以我们将重点讨论前四种。整数和双数向量一起被称为数字向量,因为它们都包含数字。这个表格总结了四种主要类型。
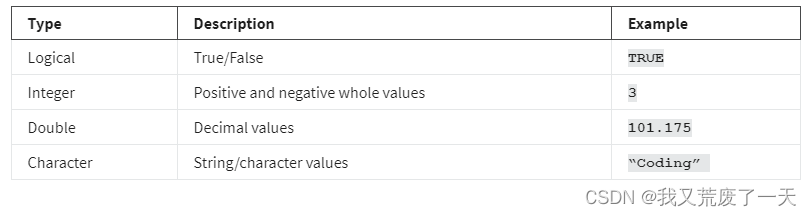
该图说明了这四种主要类型的向量之间的关系层次结构:
创建向量
创建向量的一种方法是使用c()函数(称为“combine”函数)。R 中的 c() 函数将多个值组合成一个向量。在 R 中,此函数只是字母“c”,后跟括号内向量中所需的值,用逗号分隔:c(x, y, z, ...)。
例如,您可以使用 c() 函数将数值数据存储在向量中。
c(2.5, 48.5, 101.5)
要使用 c() 函数创建整数向量,必须将字母“L”直接放在每个数字后面。
c(1L、5L、15L)
您还可以创建包含字符或逻辑的向量。
c(“莎拉”、“丽莎”、“安娜”)
c(TRUE, FALSE, TRUE)
确定向量的属性
您创建的每个向量都有两个关键属性:类型和长度。
您可以使用typeof()函数 确定您正在使用的向量类型。将向量的代码放在函数的括号内。当你运行这个函数时,R 会告诉你类型。例如:
typeof(c(“a” , “b”))#> [1] "character"
您可以使用length()函数确定现有向量的长度(即它包含的元素数量)。在此示例中,我们使用赋值运算符将向量分配给变量x。然后,我们将 length() 函数应用于变量。当我们运行函数时,R 告诉我们长度是3。
x <- c(33.5, 57.75, 120.05)length(x)#> [1] 3
你也可以通过使用is函数来检查一个向量是否是一个特定的类型:is.logical(), is.double(), is.integer(), is.character()。在这个例子中,R返回一个TRUE的值,因为该向量包含整数。
x <- c(2L, 5L, 11L)is.integer(x)#> [1] TRUE
在这个例子中,R的返回值为FALSE,因为该向量不包含字符,而是包含逻辑。
y <- c(TRUE, TRUE, FALSE)is.character(y)#> [1] FALSE
命名向量
可以命名所有类型的向量。名称对于在 R 中编写可读代码和描述对象很有用。您可以使用names()函数命名向量的元素。例如,让我们将变量 x 分配给具有三个元素的新向量。
x <- c(1, 3, 5)
你可以使用names()函数为向量的每个元素指定一个不同的名字。
names(x) <- c("a", "b", "c")
现在,当你运行代码时,R显示向量的第一个元素被命名为a,第二个b,第三个c。
x #> a b c #> 1 3 5
记住,一个原子向量只能包含相同类型的元素。如果你想在同一个数据结构中存储不同类型的元素,你可以使用一个列表。
创建列表
列表与原子向量不同,因为它们的元素可以是任何类型,如日期、数据框、向量、矩阵等。列表甚至可以包含其他列表。
您可以使用list()函数创建一个列表。与 c() 函数类似,list() 函数只是列表,后跟括号内列表中所需的值:list(x, y, z, ...)。在此示例中,我们创建了一个包含四种不同类型元素的列表:字符 ( "a" )、整数 ( 1L )、双精度 ( 1.5 ) 和逻辑 ( TRUE )。
list("a", 1L, 1.5, TRUE)
就像我们已经提到的,列表可以包含其他列表。如果你愿意,你甚至可以在一个列表中存储一个列表,在一个列表中存储一个列表,如此类推。
list(list(list(1 , 3, 5)))
确定列表的结构
如果你想知道一个列表包含哪些类型的元素,你可以使用 str() 函数。要做到这一点,请将列表的代码放在该函数的括号内。当你运行该函数时,R将通过描述列表中的元素和它们的类型来显示列表的数据结构。
让我们将 str() 函数应用于我们的第一个列表例子。
str(list("a", 1L, 1.5, TRUE))
我们运行该函数,然后 R 告诉我们列表包含四个元素,并且这些元素由四种不同的类型组成:字符 ( chr )、整数 ( int )、数字 ( num ) 和逻辑 ( logi )。
#> List of 4#> $ : chr "a"#> $ : int 1#> $ : num 1.5#> $ : logi TRUE
让我们使用 str() 函数来发现第二个示例的结构。首先,让我们将列表分配给变量z以便更容易在 str() 函数中输入。
z <- list(list(list(1 , 3, 5)))
让我们运行这个函数。
str(z)#> List of 1#> $ :List of 1#> ..$ :List of 3#> .. ..$ : num 1#> .. ..$ : num 3#> .. ..$ : num 5
$符号的缩进反映了这个列表的嵌套结构。在这里,共有三个级别(因此列表中的列表中存在列表)。
命名列表
列表和向量一样,可以命名。您可以在首次使用 list() 函数创建列表时命名列表的元素:
list('Chicago' = 1, 'New York' = 2, 'Los Angeles' = 3)$Chicago[1] 1$`New York`[1] 2$`Los Angeles`[1] 3
2.1.2R中的日期和时间
在本阅读中,您将学习如何使用lubridate包在 R 中处理日期和时间。接下来,您将使用 lubridate 包中的工具将 R 中不同类型的数据转换为日期和日期时间格式。
使用日期和时间
本节介绍 R 中日期和时间的数据类型以及如何将字符串转换为日期时间格式。
类型
在 R 中,有三种类型的数据指的是时间瞬间:
-
日期(“2016-08-16”)
-
一天中的某个时间(“20:11:59 UTC”)
-
和一个日期时间。这是一个日期加上一个时间(“2018-03-31 18:15:48 UTC”)
时间以 UTC 表示,它代表世界协调时间,通常称为世界协调时间。这是世界调节时钟和时间的主要标准。
例如,要获取当前日期,您可以运行today()函数。日期显示为年、月和日。
today()#> [1] "2021-01-20"
要获取当前日期时间,您可以运行now()函数。请注意,时间显示为最接近的秒数。
now()#> [1] "2021-01-20 16:25:05 UTC"
使用 R 时,您可以通过三种方式创建日期时间格式:
-
从一个字符串
-
从一个单独的日期
-
从现有的日期/时间对象
R 默认以标准 yyyy-mm-dd 格式创建日期。
让我们回顾一下。
从字符串转换
日期/时间数据通常以字符串形式出现。您可以使用 lubridate 提供的工具将字符串转换为日期和日期时间。这些工具会自动计算出日期/时间格式。首先,确定年、月、日在日期中出现的顺序。然后,以相同的顺序排列字母y、m和d。这为您提供了将解析您的日期的 lubridate 函数的名称。例如,对于日期2021-01-20,您使用命令ymd:
ymd("2021-01-20")
运行该函数时,R 以 yyyy-mm-dd 格式返回日期。
#> [1] "2021-01-20"
它适用于任何订单。例如,月、日和年。R 仍然以 yyyy-mm-dd 格式返回日期。
mdy("January 20th, 2021")#> [1] "2021-01-20"
或者,日、月、年。R 仍然以 yyyy-mm-dd 格式返回日期。
dmy("20-Jan-2021")#> [1] "2021-01-20"
这些函数也采用不带引号的数字并将它们转换为 yyyy-mm-dd 格式。
ymd(20210120)#> [1] "2021-01-20"
创建日期时间组件
ymd() 函数及其变体创建日期。要从 date 创建日期时间,请在函数名称中添加一个下划线和一个或多个字母h、m和 s(小时、分钟、秒):
ymd_hms("2021-01-20 20:11:59")#> [1] "2021-01-20 20:11:59 UTC"mdy_hm("01/20/2021 08:01")#> [1] "2021-01-20 08:01:00 UTC"
在现有日期时间对象之间切换
最后,您可能希望在日期时间和日期之间切换。
您可以使用函数as_date()将日期时间转换为日期。例如,将当前的日期时间——now()——放在函数的括号中。
as_date(now())#> [1] "2021-01-20"
2.1.3其他常见的数据结构
Data frames
Data frames是一个列的集合,类似于电子表格或SQL表。每一列的顶部都有一个名称,代表一个变量,每行包括一个观察值。Data frames有助于总结数据,并将其组织成一种易于阅读和使用的格式。
例如,下面的Data frames显示了 "钻石 "数据集,这是R语言中预装的数据集之一。每一列包含一个与钻石有关的变量:克拉、切割、颜色、净度、深度等等。每一行代表一个单一的观察。
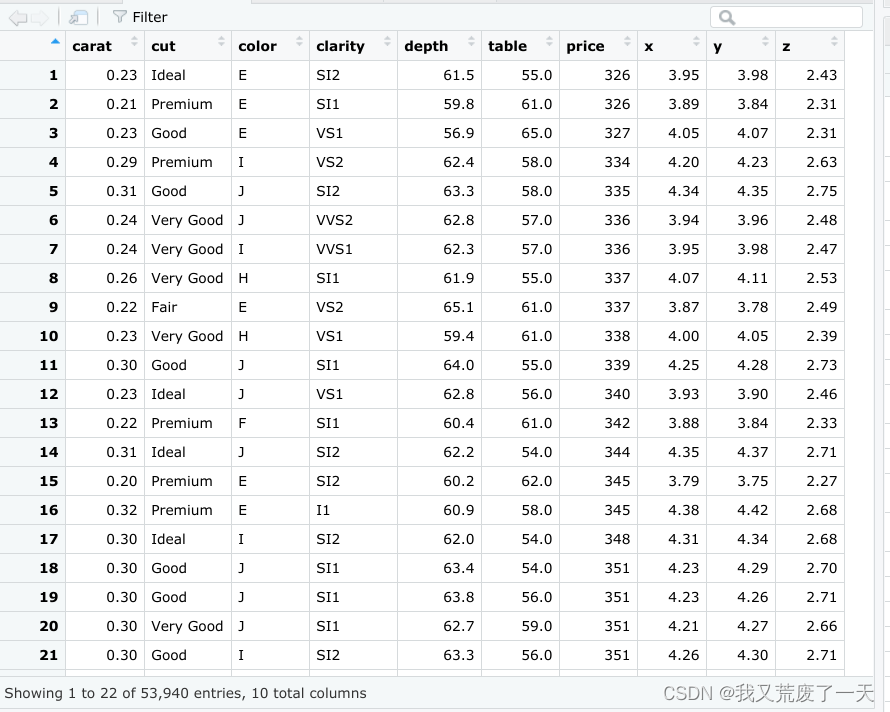
使用data frames时需要牢记以下几个关键事项:
- 首先,列应该被命名。
- 其次,data frames可以包含许多不同类型的数据,例如数字、逻辑或字符。
- 最后,同一列中的元素应该属于同一类型。
如果需要在 R 中手动创建data frames,可以使用data.frame()函数。data.frame() 函数将向量作为输入。在括号中,输入列的名称,后跟等号,然后是要为该列输入的向量。在此示例中,x列是具有元素 1、2、3 的向量,y列是具有元素 1.5、5.5、7.5 的向量。
data.frame(x = c(1, 2, 3) , y = c(1.5, 5.5, 7.5))
如果您运行该函数,R 会以有序的行和列显示数据框。
xy1 1 1.52 2 5.53 3 7.5
文件
让我们来看看如何在 R 中创建、复制和删除文件。有关在 R 中使用文件的更多信息,请查看R 文档:files。R 文档是一种工具,可帮助您轻松查找和浏览 CRAN 上几乎所有 R 包的文档。它是 R 代码中函数的有用参考指南。让我们来看看处理文件的一些最有用的功能。
使用dir.create函数创建一个新文件夹或目录来保存您的文件。将文件夹的名称放在函数的括号中。
dir.create ("destination_folder")
使用file.create()函数创建一个空白文件。将文件的名称和类型放在函数的括号中。您的文件类型通常是 .txt、.docx 或 .csv。
file.create (“new_text_file.txt”) file.create (“new_word_file.docx”) file.create (“new_csv_file.csv”)
如果在您运行函数时成功创建文件,R 将返回TRUE值(否则,R 将返回FALSE)。
file.create (“new_csv_file.csv”)
[1] TRUE
可以使用file.copy()函数复制文件。在括号中,添加要复制的文件的名称。然后,键入逗号,并添加要将文件复制到的目标文件夹的名称。
file.copy(“new_text_file.txt”,“destination_folder”)
如果您检查 RStudio 中的“文件”窗格,文件的副本会出现在相关文件夹中:
您可以使用unlink()函数删除 R 文件。在函数的括号中输入文件名。
unlink (“some_.file.csv”)
矩阵
矩阵是数据元素的二维集合。这意味着它既有行又有列。相比之下,向量是数据元素的一维序列。但与向量一样,矩阵只能包含一种数据类型。例如,矩阵中不能同时包含逻辑和数字。
要在 R 中创建矩阵,可以使用matrix()函数。matrix() 函数有两个您在括号中输入的主要参数。首先,添加一个向量。该向量包含您要放置在矩阵中的值。接下来,添加至少一个矩阵维度。您可以使用代码nrow =或ncol =来选择指定行数或列数。
例如,假设您要创建一个包含值 3-8 的 2x3(两行乘三列)矩阵。首先,输入一个包含该系列数字的向量:c(3:8)。然后,输入逗号。最后,输入nrow = 2指定行数。
matrix(c(3:8), nrow = 2)
如果你运行这个函数,R会显示一个三列两行的矩阵(通常称为 “2x3”),其中包含数字值3、4、5、6、7、8。R将向量的第一个值(3)放在矩阵的最上面一行,最左边一列,然后从左到右继续排列。
[,1] [,2] [,3][1,] 3 5 7[2,] 4 6 8
你也可以选择指定列数(ncol = )而不是行数(nrow = )。
matrix(c(3:8), ncol = 2)
当你运行这个函数时,R会自动推断出行数。
[,1] [,2] [1,] 3 6 [2,] 4 7 [3,] 5 8
2.2探索 R 中的编码
运算符:赋值运算符、算术运算符
2.2.1逻辑运算符和条件语句
逻辑运算符
逻辑运算符返回逻辑数据类型,例如 TRUE 或 FALSE。
逻辑运算符主要分为三种类型:
-
AND(在 R 中有时表示为 & 或 &&)
-
或(在 R 中有时表示为 | 或 ||)
-
否 (!)
查看下面总结的逻辑运算符。
AND 运算符“&”
-
AND 运算符采用两个逻辑值。仅当两个单独的值都为 TRUE 时,它才返回TRUE 。这意味着 TRUE & TRUE 评估为TRUE。但是,FALSE & TRUE、TRUE & FALSE 和 FALSE & FALSE 都评估为FALSE。
-
如果你在 R 中运行相应的代码,你会得到以下结果:
> TRUE & TRUE
[1] TRUE
> TRUE & FALSE
[1] FALSE
> FALSE & TRUE
[1] FALSE
> FALSE & FALSE
[1] FALSE
您可以使用我们的比较结果来说明这一点。假设您创建了一个等于 10 的变量 x。
x <- 10
要检查 x 是否大于 3 但小于 12,可以使用 x > 3 和 x < 12 作为“AND”表达式的值。
x > 3 & x < 12
运行该函数时,R 返回结果 TRUE。
[1] TRUE
第一部分x > 3将评估为TRUE,因为 10 大于 3。第二部分x < 12也将评估为TRUE,因为 10 小于 12。因此,由于两个值都是 TRUE,所以AND 表达式的结果是TRUE。数字 10 位于数字 3 和 12 之间。
但是,如果使 x 等于 20,则表达式x > 3 & x < 12将返回不同的结果。
x <- 20
x > 3 & x < 12
[1] FALSE
虽然x > 3为TRUE (20 > 3),但x < 12为FALSE (20 < 12)。如果 AND 表达式的一部分为 FALSE,则整个表达式为 FALSE (TRUE & FALSE = FALSE)。因此,R 返回结果FALSE。
或运算符“|”
-
OR 运算符 (|) 的工作方式与 AND 运算符 (&) 类似。主要区别在于,OR 运算的至少一个值必须为
TRUE才能使整个 OR 运算评估为TRUE。这意味着 TRUE | TRUE,TRUE | FALSE和FALSE | TRUE 都评估为TRUE。当两个值都为 FALSE 时,结果为FALSE。 -
如果你写出代码,你会得到以下结果:
> TRUE | TRUE
[1] TRUE
> TRUE | FALSE
[1] TRUE
> FALSE | TRUE
[1] TRUE
> FALSE | FALSE
[1] FALSE
例如,假设您创建一个等于 7 的变量 y。要检查 y 是小于 8 还是大于 16,您可以使用以下表达式:
y <- 7
y < 8 | y > 16
比较结果为TRUE(7小于8) | FALSE(7 不大于 16)。由于 OR 表达式中只有一个值需要为 TRUE 才能使整个表达式为 TRUE,因此 R 返回结果为 TRUE。
[1] TRUE
现在,假设 y 是 12。表达式 y < 8 | y > 16 现在计算为 FALSE (12 < 8) | FALSE (12 > 16)。两个比较都是 FALSE,所以结果是FALSE。
y <- 12
y < 8 | y > 16
[1] FALSE
非运算符“!”
-
NOT 运算符 (!) 简单地否定它适用的逻辑值。换句话说, !TRUE 计算结果为FALSE,而 !FALSE 计算结果为TRUE。
-
运行代码时,您会得到以下结果:
> !TRUE[1] FALSE
> !FALSE
[1] TRUE
就像 OR 和 AND 运算符一样,您可以将 NOT 运算符与逻辑运算符结合使用。零被认为是 FALSE,非零数字被认为是 TRUE。NOT 运算符的计算结果为相反的逻辑值。
假设您有一个等于 2 的变量 x:
x <- 2
NOT 运算的计算结果为 FALSE,因为它采用非零数 (TRUE) 的相反逻辑值。
> !x
[1] FALSE
条件语句
条件语句是一个声明,如果某个条件成立,那么某个事件必须发生。例如,“如果温度高于冰点,那我就出去走走。” 如果第一个条件为真(温度高于冰点),那么将出现第二个条件(我要去散步)。R 代码中的条件语句具有类似的逻辑。
-
if() -
else() -
else if()
if 语句
if语句设置一个条件,如果条件评估为TRUE,则执行与 if 语句关联的 R 代码。
在 R 中,您将条件代码放在 if 语句的括号内。如果条件为 TRUE,则必须执行的代码在花括号 ( expr ) 中。请注意,在这种情况下,第二个花括号放在它自己的代码行上,并标识要执行的代码的结尾。
if (condition) {expr}
例如,让我们创建一个等于4的变量x。
x <- 4
接下来,让我们创建一个条件语句:如果x大于0,那么R将打印出字符串 “x is a positive number”。
number". if (x > 0) {print("x is a positive number")}
由于x=4,条件为真(4>0)。因此,当你运行代码时,R打印出 "x is a positive number "的字符串。
[1] "x is a positive number"
但是如果你把x改成一个负数,比如说-4,那么条件就会是FALSE(-4>0)。如果你运行这段代码,R将不执行打印语句。相反,一个空行将作为结果出现。
else语句
else语句是与if语句结合使用的。这就是R语言中代码的结构方式。
if (condition) {expr1} else {expr2}
只要if语句的条件不是TRUE,与else语句相关的代码就会被执行。换句话说,如果条件是TRUE,那么R将执行if语句中的代码(expr1);如果条件不是TRUE,那么R将执行else语句的代码(expr2)。
让我们试试一个例子。首先,创建一个等于7的变量x。
x <- 7
接下来,让我们设置以下条件。
如果x大于0,R将打印 “x is a positive number”。
如果x小于或等于0,R将打印 “x is either a negative number or zero”。
在我们的代码中,第一个条件(x > 0)将是if语句的一部分。第二个条件(x小于或等于0)则隐含在else语句中。如果x>0,那么R将打印 “x is a positive number”。否则,R将打印 “x is either a negative number or zero”。
x <- 7if (x > 0) {print ("x is a positive number")} else {print ("x is either a negative number or zero")}
由于7大于0,if语句的条件为真。因此,当你运行代码时,R会打印出 “x is a positive number”。
[1] "x is a positive number"
但如果你让x等于-7,if语句的条件就不是真的(-7不大于0)。因此,R将执行else语句中的代码。当你运行这段代码时,R打印出 “x is either a negative number or zero”。
x <- -7if (x > 0) {print("x is a positive number")} else {print ("x is either a negative number or zero")}[1] "x is either a negative number or zero"
else if语句
在某些情况下,您可能希望通过添加else if语句来进一步自定义条件语句。else if 语句位于 if 语句和 else 语句之间。这是代码结构:
if (condition1) {expr1} else if (condition2) {expr2} else {expr3}
如果满足 if 条件 ( condition1 ),则 R 执行第一个表达式 ( expr1 ) 中的代码。如果不满足 if 条件,并且满足 else if 条件 ( condition2 ),则 R 执行第二个表达式 ( expr2 ) 中的代码。如果两个条件都不满足,R 将执行第三个表达式 ( expr3 ) 中的代码。
在我们之前的示例中,仅使用 if 和 else 语句,如果 x 等于 0 或 x 小于零,R 只能打印“x is a negative number or zero” 。想象一下,如果 x 等于 0,您希望 R 打印字符串“x is zero”。您需要使用 else if 语句添加另一个条件。
让我们尝试一个例子。首先,创建一个等于负 1(“-1”) 的变量x 。
x <- -1
现在,您要设置以下条件:
-
如果 x 小于 0,则打印
“x is a negative number” -
如果 x 等于 0,则打印
“x is zero” -
否则,打印
“x is a positive number”
在代码中,第一个条件是 if 语句的一部分,第二个条件是 else if 语句的一部分,第三个条件是 else 语句的一部分。如果 x < 0,则 R 将打印“x is a negative number”。如果 x = 0,则 R 将打印“x is zero”。否则,R 将打印“x is a positive number”
x <- -1if (x < 0) {print("x is a negative number")} else if (x == 0) {print("x is zero")} else {print("x is a positive number")}
由于 -1 小于 0,if 语句的条件计算结果为TRUE,并且 R 打印“x is a negative number”。
[1] "x is a negative number"
如果使 x 等于 0,R 将首先检查 if 条件(x < 0),并确定它为 FALSE。然后,R 将评估 else if 条件。此条件x==0为 TRUE。因此,在这种情况下,R 打印“x is zero”。
如果您使 x 等于 1,则 if 条件和 else if 条件都评估为FALSE。因此,R 将执行 else 语句并打印“x is a positive number”。
一旦 R 发现一个计算结果为 TRUE 的条件,R 就会执行相应的代码并忽略其余代码。
常用函数
head()函数,显示各列和前几行的数据。
str()和glimpse()函数都会返回你的数据中每一列水平排列的摘要。
colnames()函数从你的数据集中返回一个列名列表。
rename(diamonds, carat_new = carat)重命名,diamonds是数据集,carat_new是重命名后的列名,carat是原来的列名。
要用ggplot2'建立一个可视化,你需要用+'符号将绘图元素分层。
ggplot(data = diamonds, aes(x = carat, y = price)) +geom_point()
上面的代码获取了 "diamonds "数据,在X轴上绘制了克拉列,在Y轴上绘制了价格列,并使用geom_point()命令将数据表示为散点图。
ggplot2使得修改或改进你的视觉效果变得容易。例如,如果你想改变每个点的颜色,使其代表另一个变量,如钻石的切割,你可以这样修改代码。
ggplot(data = diamonds, aes(x = carat, y = price, color = cut)) +
geom_point()
当你试图在视觉上表现你的数据的许多不同方面时,可以帮助你把一些组成部分分开。例如,你可以为每种类型的切割创建一个不同的图。ggplot2通过facet_wrap()函数可以轻松做到这一点。
ggplot(data = diamonds, aes(x = carat, y = price, color = cut)) +geom_point() +facet_wrap(~cut)
CRAN是一个常用的在线存档,包含R包和其他R资源。CRAN确保其共享的R资源遵循规定的质量标准,并且是真实有效的。CRAN包含许多不同的包,但本身并不是一个集合。
2.3探索 tidyverse
- ggplot2 用于数据可视化,特别是绘图。
- Tidyr 是一个用于数据清洗的包,用于整理数据。
- readr,用于导入数据,readr 中最常用的函数是 read_csv
- Dplyr 提供了一组一致的功能来帮助您完成一些常见的数据操作任务。例如, select 函数根据变量的名称选择变量,过滤器功能会发现某些条件为真的情况。
- Tibble 使用dataframes。
- Purrr 适用于函数和向量有助于使您的代码更容易编写和更具表现力。
- Stringr 包含使处理字符串更容易的函数。
- Forcats 提供了解决因子常见问题的工具。
3.在 R 中处理数据:
R 编程语言设计用于在数据分析过程的所有阶段处理数据。在这部分课程中,您将了解 R 如何通过函数和其他流程帮助您构建、组织和清理数据。您将了解数据框以及如何在 R 中使用它们。您还将重新审视数据偏差的概念以及如何使用 R 来解决它。
3.1探索数据和 R
data frame
data frame是一个列的集合。它很像电子表格或SQL表。这是一个R语言中的数据框的例子。它很像我们在整个程序中使用的其他表格。它有列名和行,以及有数据的单元格。列中包含一个变量,行中有一组与每一列相匹配的值。我们使用数据框架的原因与表格也有很多相同之处。它们有助于总结数据,并把它放到一个易于阅读和使用的格式中。
- 首先,列应该被命名。使用空的列名会给你以后的结果带来问题。
- 存储在你的数据框架中的数据可以是许多不同的类型,如数字、因子或字符。通常数据框包含日期、时间戳和逻辑向量。
- 最后,每一列应该包含相同数量的数据项,即使其中一些数据项缺失。
head()、glimpse()和str()总结函数允许你在R中预览数据框架。 head()函数返回数据的列和前几行。
mutate()函数让你改变数据框架,而不是预览它。
Tibbles
在tidyverse中,tibbles就像简化的数据框架。它们使数据工作更容易,但它们与标准的数据框架有一点不同。首先,tibbles不会改变输入的数据类型。他们不会把你的字符串改成因子或其他东西。你可以对基础数据框架做更多的改变,但是tibbles更容易使用。这可以节省时间,因为您不必在tibbles中做那么多清理或改变数据类型。tibbles也不会改变你的变量的名称,而且它们也不会创建行名。
3.1.1数据导入基础
data()函数
您可以使用data()函数在 R 中加载这些数据集。如果您在没有参数的情况下运行数据函数,R 将显示可用数据集的列表。
data()
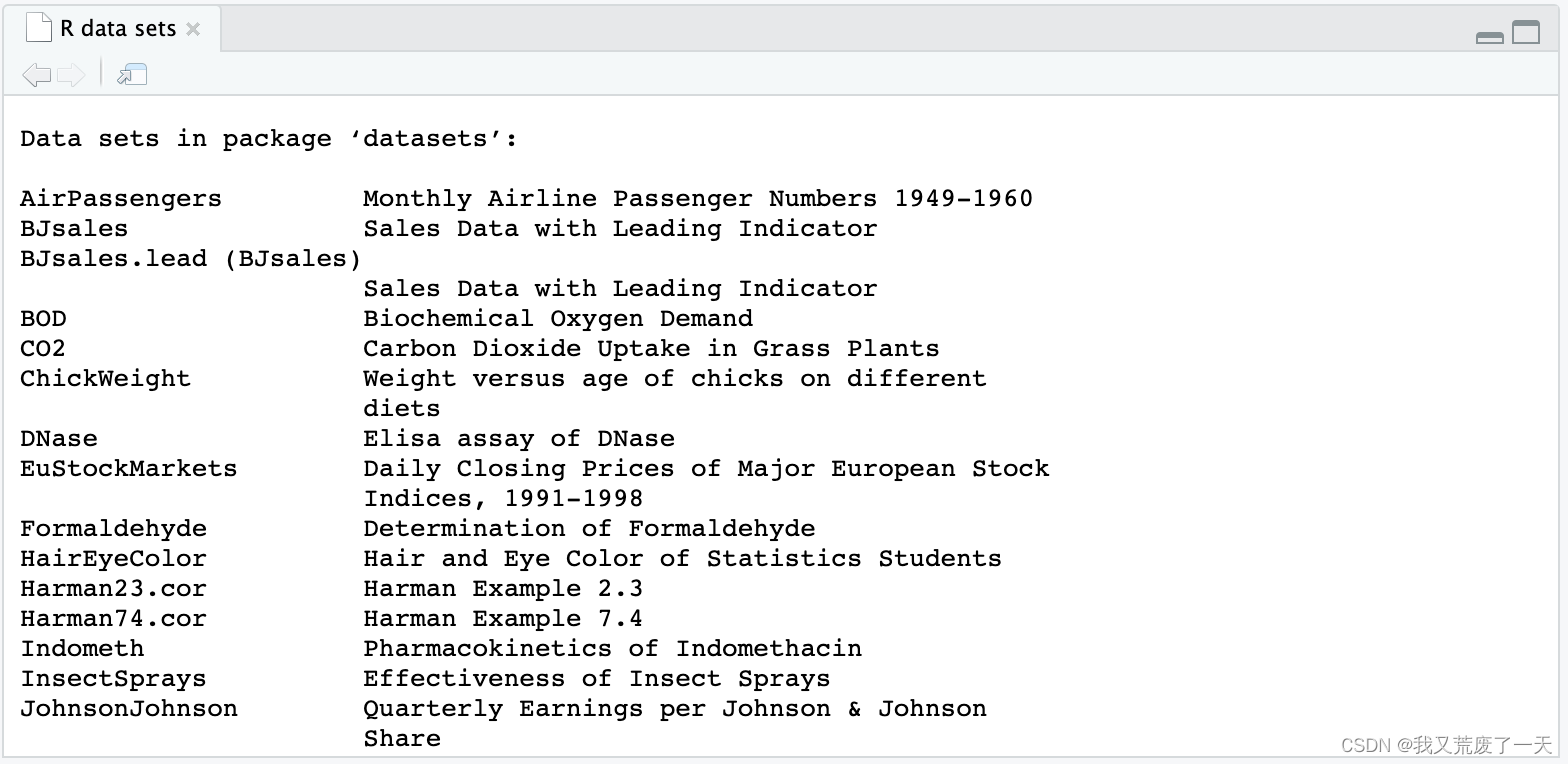
如果要加载特定数据集,只需在 data() 函数的括号中输入其名称。例如,让我们加载mtcars数据集,其中包含有关汽车的信息,这些信息曾在过去几期Motor Trend杂志中出现。
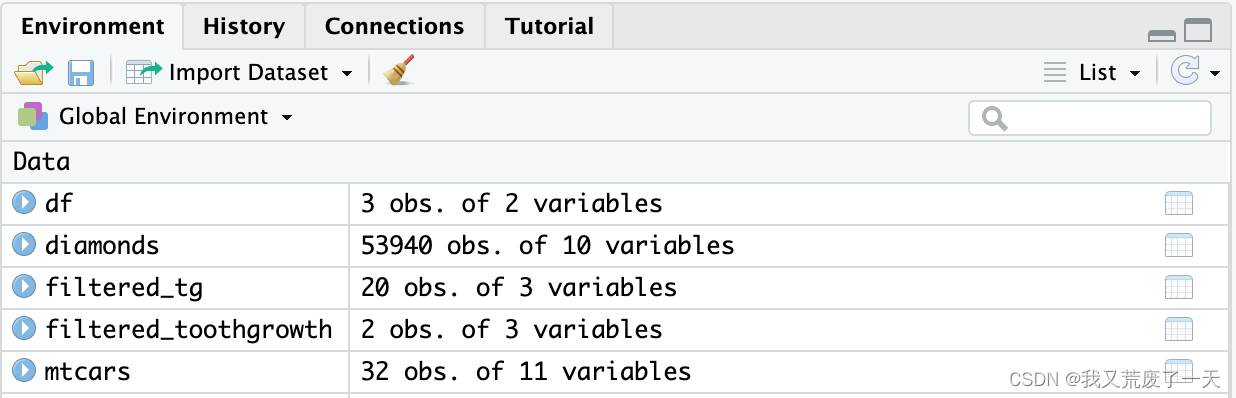
data(mtcars)
当您运行该函数时,R 将加载数据集。数据集也将出现在 RStudio 的环境窗格中。环境窗格显示您在当前工作空间中拥有的数据对象的名称,例如数据框和变量。在此图像中,mtcars出现在窗格的第五行。R 告诉我们它包含 32 个观察值和 11 个变量。
现在数据集已加载,您可以在 R 控制台窗格中对其进行预览。只需输入其名称mtcars然后按 ctrl(或 cmnd)并输入。
您还可以通过直接单击环境窗格中的数据集名称来显示数据集。因此,如果您在 Environment 窗格中单击mtcars,R 会自动运行 View() 函数并在 RStudio 数据查看器中显示数据集。
readr package
R 中的 readr 包是读取矩形数据的好工具。矩形数据是非常适合在行和列的矩形内的数据,每列引用一个变量,每一行引用一个观察值。
以下是一些存储矩形数据的文件类型示例:
- .csv (逗号分隔值):.csv 文件是包含数据列表的纯文本文件。他们大多使用逗号分隔(或分隔)数据,但有时他们使用其他字符,如分号。
- .tsv(制表符分隔值):.tsv 文件存储数据表,其中数据列由制表符分隔。例如,数据库表或电子表格数据。
- .fwf (固定宽度文件):.fwf 文件具有特定格式,允许以有组织的方式保存文本数据。
- .log: .log 文件是计算机生成的文件,用于记录来自操作系统和其他软件程序的事件。
readr 功能
readr 的目标是提供一种快速且友好的方式来读取矩形数据。readr 支持几个 read_ 函数。每个函数都引用一种特定的文件格式。
read_csv():逗号分隔值 (.csv) 文件read_tsv():制表符分隔值文件read_delim(): 通用分隔文件read_fwf(): 固定宽度文件read_table():表格文件,其中列由空格分隔read_log(): 网络日志文件
使用 readr 读取 .csv 文件
readr 包附带了一些来自内置数据集的示例文件,您可以将其用作示例代码。要列出示例文件,您可以运行不带参数的 readr_example() 函数。
readr_example()[1] “challenge.csv” “epa78.txt” “example.log” [4] “fwf-sample.txt” “massey-rating.txt” “mtcars.csv” [7] “mtcars.csv.bz2” “mtcars.csv.zip”
“ mtcars.csv”文件指的是前面提到的mtcars数据集。让我们以read_csv()函数读取“mtcars.csv”文件为例。在括号中,您需要提供文件的路径。在这种情况下,它是“readr_example(“mtcars.csv”)。
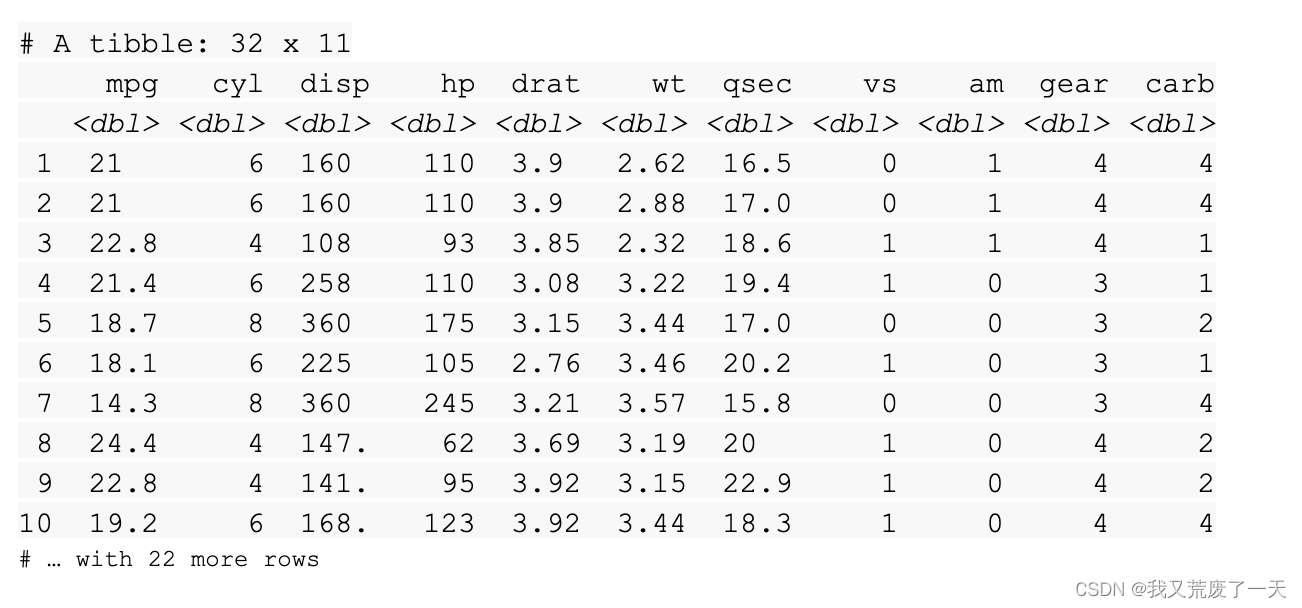
read_csv(readr_example("mtcars.csv"))
当您运行该函数时,R 会打印出一个列规范,其中给出了每列的名称和类型。

R 也打印一个小标题。
使用 readxl 读取 .csv 文件
与 readr 包一样,readxl 附带了一些来自内置数据集的示例文件,您可以将其用于练习。您可以运行代码readxl_example()来查看列表。
您可以使用read_excel()函数读取电子表格文件,就像使用 read_csv() 函数读取 .csv 文件一样。读取示例文件“type-me.xlsx”的代码在函数的括号中包含文件的路径。
read_excel(readxl_example("type-me.xlsx"))
您可以使用excel_sheets()函数列出各个工作表的名称。
excel_sheets(readxl_example("type-me.xlsx"))[1] “logical_coercion” “numeric_coercion” “date_coercion” “text_coercion”
您还可以按名称或编号指定工作表。只需键入“sheet =”,后跟工作表的名称或编号。例如,您可以使用上面列表中名为“numeric_coercion”的工作表。
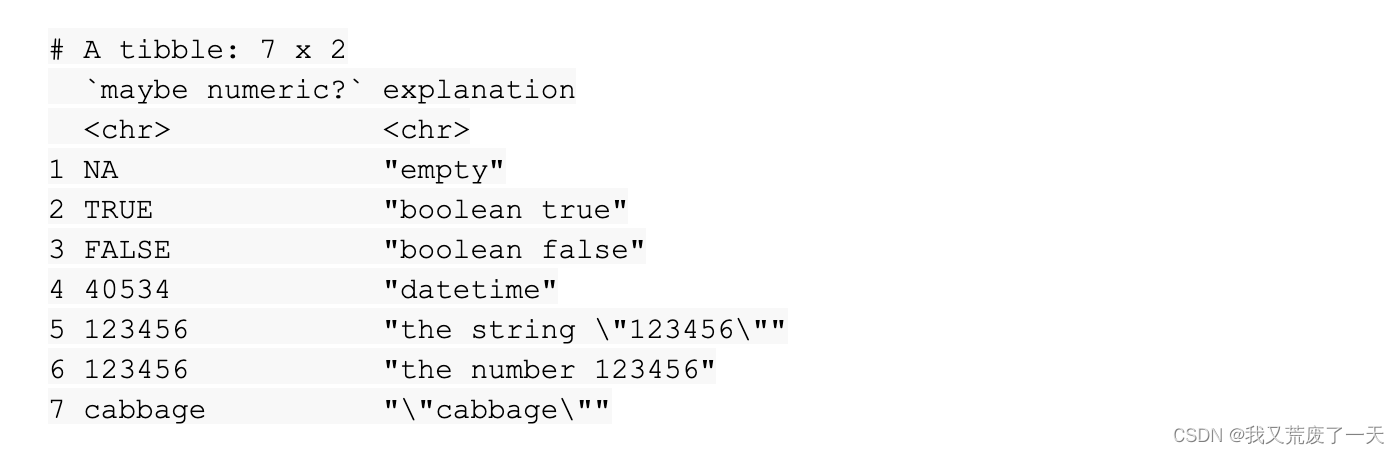
read_excel(readxl_example("type-me.xlsx"), sheet = "numeric_coercion")
当您运行该函数时,R 返回工作表的小标题。
3.2清理数据
3.2.1基本的数据清理操作
Here包使引用文件更容易。
Skimr包使总结数据变得非常容易,让你更快地浏览数据。
Janitor包有清理数据的功能。
获取data frame摘要的函数:

skim_without_charts()给我们提供了一个相当全面的数据集的摘要。
Glimpse()用来快速了解这个数据集里有什么,它将向我们显示数据的摘要。
Head()用来预览这个数据集的列名和前几行的内容,有了这样的列名汇总,将使我们更容易对其进行清理。
使用select()来指定某些列或排除我们现在不需要的列。select(a)是只选中a,select(-a)是选中除了a的所有。
rename()重命名列名
rename(island_new = island)
也许我们想要所有我们的列名要大写。我们可以使用 rename_with() 函数来做到这一点。
#大写
rename_with(penguins,toupper)
#小写
rename_with(penguins,tolower)
Janitor 包中的clean_names()将自动确保列名是唯一且一致的。这确保只有字符,数字和名称中的下划线。
3.2.2文件命名约定
清理数据的一个重要部分是确保准确命名所有文件。尽管个人偏好会有所不同,但大多数分析师普遍认为文件名应该准确、一致且易于阅读。此阅读为您在命名或重命名数据文件时提供了一些通用指南。
要做的事:
- 将文件名保持在合理的长度
- 使用下划线和连字符以提高可读性
- 以字母或数字开头或结尾文件名
- 在适用时使用标准日期格式;示例:YYYY-MM-DD
- 使用适用于默认排序的相关文件的文件名;示例:按时间顺序,或先使用数字的逻辑顺序

不要做的事
- 在文件名中使用不必要的附加字符
- 使用空格或“非法”字符;示例:&、%、#、< 或 >
- 以符号开始或结束文件名
- 使用不完整或不一致的日期格式;示例:MD-YY
- 使用默认排序不能很好地工作的相关文件的文件名;示例:数字或日期格式的随机系统,或首先使用字母
3.2.3更多关于 R 运算符
您可能还记得,运算符是一个符号,用于标识要在公式中执行的操作或计算的类型。在之前的视频中,您学习了如何使用赋值和算术运算符来分配变量和执行计算。
在 R 中,有四种主要类型的运算符:
-
算术
-
关系型
-
逻辑的
-
任务
算术运算符
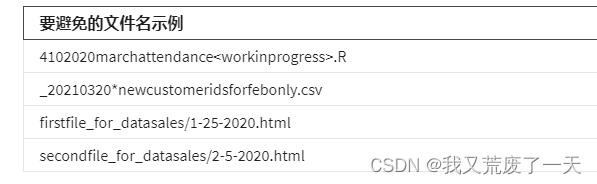
算术运算符让您可以执行基本的数学运算,例如加法、减法、乘法和除法。
下表总结了 R 中的不同算术运算符。表中使用的示例基于创建两个变量:x等于 2 和y等于 5。请注意,您使用赋值运算符来存储这些值:
x <- 2y <- 5
关系运算符
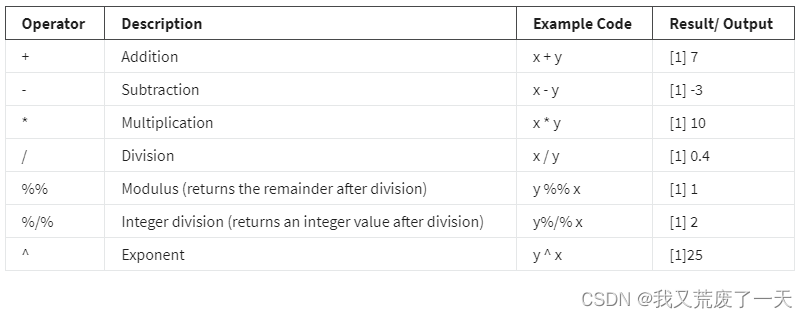
关系运算符,也称为比较器,允许您比较值。关系运算符识别一个 R 对象与另一个对象的关系——比如一个对象是小于、等于还是大于另一个对象。关系运算符的输出是 TRUE 或 FALSE(它是一种逻辑数据类型,或布尔值)。
下表总结了 R 中的六个关系运算符。表中使用的示例基于创建两个变量:x等于 2 和y等于 5。请注意,您使用赋值运算符来存储这些值。
x <- 2y <- 5
如果您对每个运算符执行计算,您会得到以下结果。在这种情况下,输出为布尔值:TRUE 或 FALSE。请注意,出现在每个输出之前的 [1] 用于表示输出在 RStudio 中的显示方式。

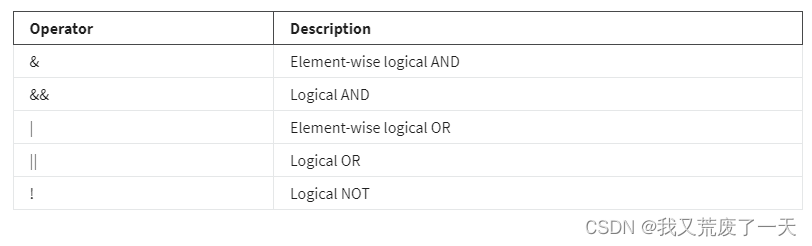
逻辑运算符
逻辑运算符允许您组合逻辑值。逻辑运算符返回逻辑数据类型或布尔值(TRUE 或 FALSE)。您在之前的阅读中遇到过逻辑运算符,逻辑运算符和条件语句,但这里有一个快速复习。
接下来,查看一些关于逻辑运算符如何在 R 代码中工作的示例。
元素间逻辑 与(&) 和 逻辑或(|)
您可以通过比较数值来说明逻辑 AND (&) 和 OR (|)。创建一个等于 10 的变量x 。
x <- 10
仅当两个单独的值都为 TRUE 时,AND 运算符才返回 TRUE。
x > 2 & x < 12[1] TRUE
10 大于 2且10 小于 12。因此,运算结果为TRUE。
OR 运算符 (|) 的工作方式与 AND 运算符 (&) 类似。主要区别在于,只要OR 运算的一个值必须为 TRUE,整个 OR 运算才能评估为 TRUE。只有当两个值都为 FALSE 时,整个 OR 运算才会评估为FALSE。
现在尝试使用相同变量(x <- 10)的示例:
x > 2 | x < 8[1] TRUE
10 大于 2,但 10 不小于 8。但由于至少有一个值 (10>2) 为 TRUE,因此 OR 运算的计算结果为TRUE。
逻辑与 (&&) 和或 (||)
元素间逻辑运算符(&、|)和逻辑运算符(&&、||)之间的主要区别在于它们应用于向量运算的方式。带有双符号的运算 AND (&&) 和逻辑 OR (||) 只检查每个向量的第一个元素。单符号运算 AND (&) 和 OR (|) 检查每个向量的所有元素。
例如,假设您正在使用两个向量,每个向量都包含三个元素:c(3, 5, 7)和c(2, 4, 6)。元素间逻辑与 (&) 将比较第一个向量的第一个元素与第二个向量的第一个元素 (3&2)、第二个元素与第二个元素 (5&4)、第三个元素与第三个元素 ( 7&6)。
现在在 R 代码中查看这个示例。
首先,创建两个变量x和y来存储两个向量:
x <- c(3, 5, 7)y <- c(2, 4, 6)
然后使用单个 & 符号 (&) 运行代码。输出为布尔值(TRUE 或 FALSE)。
x < 5 & y < 5[1] TRUE FALSE FALSE
当您比较两个向量的每个元素时,输出为TRUE、FALSE、FALSE。x (3) 和y (2)的第一个元素都小于 5,所以这是 TRUE。x 的第二个元素不小于 5(它等于 5)但 y 的第二个元素小于 5,所以这是 FALSE(因为您使用了 AND)。x 和 y 的第三个元素都不小于 5,所以这也是 FALSE。
现在,使用双与号 (&&) 运行相同的操作:
x < 5 && y < 5[1] TRUE
在这种情况下,R 只比较每个向量的第一个元素:3 和 2。因此,输出为TRUE,因为 3 和 2 都小于 5。
根据您所做的工作类型,您可能会更频繁地使用单号运算符而不是双号运算符。但无论如何,了解所有操作员的工作方式是有帮助的。
逻辑非 (!)
NOT 运算符简单地否定逻辑值,并计算相反的值。在 R 中,零被认为是 FALSE,所有非零数字都被认为是 TRUE。
例如,将 NOT 运算符应用于您的变量(x <- 10):
!(x < 15)[1] FALSE
NOT 操作的计算结果为FALSE,因为它采用语句x < 15的相反逻辑值,即 TRUE(10 小于 15)。
赋值运算符
赋值运算符让您可以为变量赋值。
在许多脚本编程语言中,您可以只使用等号 (=) 来分配变量。对于 R,最佳实践是使用箭头赋值 (<-)。从技术上讲,单箭头分配可用于向左或向右方向。但是 R 代码中通常不使用向右赋值。
您还可以使用双箭头分配,称为范围分配。但是范围分配是针对高级 R 用户的,因此您不会在本阅读中了解它。
下表总结了 R 中的赋值运算符和示例代码。请注意,每个变量的输出都是其赋值。
| 运算符 | 描述 | 示例代码 | 输出 |
|---|---|---|---|
| <- | 向左赋值 | x<-2 | [1]2 |
| <<- | 向左赋值 | x<<-7 | [1]7 |
| = | 向左赋值 | x=9 | [1]9 |
| -> | 向右赋值 | 11->x | [1]11 |
| ->> | 向右赋值 | 21->>x | [1]21 |
3.2.4整理数据
- arrange()
- group_by()
- filter()
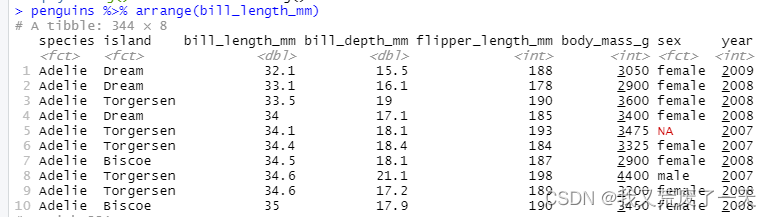
#对penguins数据集的bill_length_mm这列排序
penguins %>% arrange(bill_length_mm)#降序
penguins %>% arrange(-bill_length_mm)
penguins %>% group_by(island) %>% drop_na() %>% summarise(mean_bill_length_mm = mean(bill_length_mm))

penguins %>% group_by(island,species) %>% drop_na() %>% summarise(max_bl = max(bill_length_mm),mean_bl = mean(bill_length_mm))

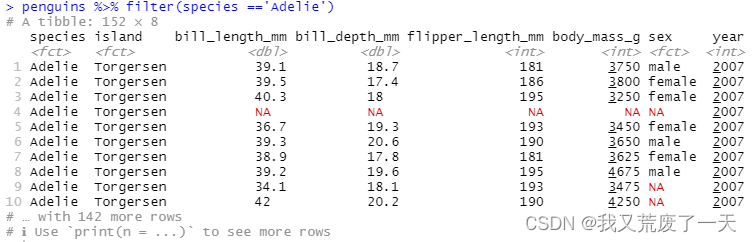
penguins %>% filter(species =='Adelie')
3.2.5转换数据
- separate()
# employee是datafram名,name是列名,将name以分隔符' '分成'first_name','last_name'两列。
separate(employee,name,into = c('first_name','last_name'),sep = ' ')
- unite()
#合并两列
unite(employee,'name',first_name,last_name,sep=' ')
- mutate()
#创建新列
penguins %>%mutate(body_mass_kg = body_mass_g/1000)
3.2.6tidyr 从宽数据到长数据
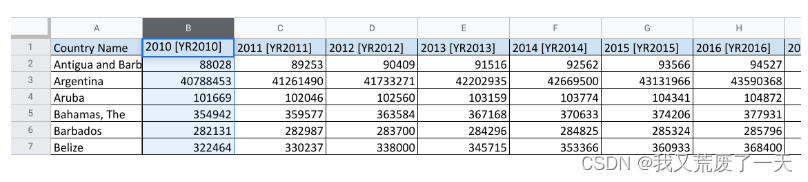
宽数据具有跨多个列的观察结果。每列包含来自变量不同条件的数据。在这个例子中,不同的年份。
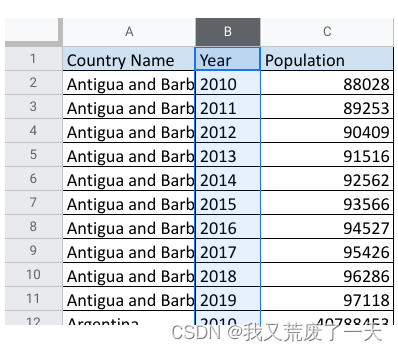
现在以长格式查看相同的数据,长数据将所有观察结果放在一个列中,并将变量放在单独的列中。
pivot_longer 和 pivot_wider 函数
作为 tidyr 包的一部分,您可以使用pivot_longer() 通过增加行数和减少列数来延长数据框中的数据。同样,如果要将数据转换为具有更多列和更少行,则可以使用 pivot_wider() 函数。
3.3仔细看看数据
3.3.1相同的数据,不同的结果
3.3.2偏置函数
install.packages("SimDesign")
library(SimDesign)
在R中,我们实际上可以通过比较我们数据的实际结果和预测结果来量化偏见。这背后有一个相当复杂的统计学解释。但是有了R语言中的偏置函数,我们就不必手工进行这种计算了。基本上,偏置函数找到了实际结果大于预测结果的平均数量。如果模型是无偏的,结果应该相当接近于零。一个高的结果意味着你的数据可能是有偏的。
actual_temp<-c(68.3,70,72.4,71,67,70)
predicted_temp <- c(67.9,69,71.5,70,67,69)
bias(actual_temp,predicted_temp)[1] 0.7166667
4.可视化、美学和注释:
R 是创建详细可视化的绝佳工具。在这部分课程中,您将学习如何使用 R 生成可视化并排除故障。您还将探索 R 和 RStudio 的功能,这些功能可以帮助您提高可视化的美感。您将学习如何注释可视化并保存更改。
4.1在 R 中创建数据可视化
4.1.1R 和 tidyverse 中的可视化基础知识

Ggplot2有很多其他的好处
- 你可以创建所有不同类型的图,包括散点图、柱状图、线状图和其他许多图。
- 你可以改变你的图的颜色、布局和尺寸,并添加文本元素,如标题、说明和标签。
- ggplot2让你可以使用pipe操作符将数据处理和可视化结合起来。
- Ggplot2还有大量的函数可以满足你所有的数据可视化需求。
我们将集中讨论ggplot2中的一些核心概念:aesthetics美学, geoms几何, facets面, labels标签 and annotations注释。
- 审美是你的绘图中一个对象的视觉属性。例如,在散点图中,美学包括诸如数据点的大小、形状或颜色。把美学看作是绘图中的视觉特征与数据中的变量之间的联系或映射。
- geom指的是用来表示你的数据的几何对象。例如,你可以用点来创建散点图,用条来创建柱状图,或者用线来创建线图。你可以选择一个适合你的数据类型的几何体。点显示两个定量变量之间的关系。条形图显示一个定量变量在不同类别中的变化。
- 切面让你显示更小的数据组或子集。通过面,你可以为你的数据集中的所有变量创建单独的图。
- label 和 annotate功能可以让您自定义绘图。您可以添加文本,如标题、副标题和说明您的情节的目的或突出重要数据。
4.1.2使用 ggplot2 可视化数据
#载入数据
library(ggplot2)
library(palmerpenguins)data(penguins)
View(penguins)
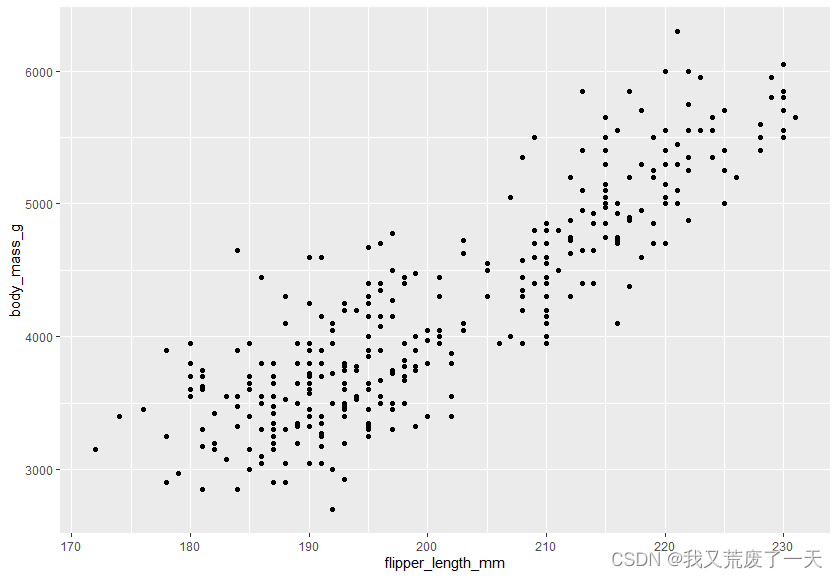
假设您想绘制三种企鹅的体重和鳍状肢长度之间的关系。您可以选择适合您拥有的数据类型的特定几何。点显示两个定量变量之间的关系。点的散点图将是显示两个变量之间关系的有效方法。您可以将脚蹼长度放在 x 轴上,将体重放在 y 轴上。
ggplot(data = penguins) + geom_point(mapping = aes(x = flipper_length_mm, y = body_mass_g))
ggplot(data = penguins):在 ggplot2 中,您使用 ggplot() 函数开始绘图。ggplot() 函数创建一个可以添加图层的坐标系。ggplot() 函数的第一个参数是要在图中使用的数据集。在这种情况下,它是“企鹅”。
+:然后,您添加一个“+”符号来为您的绘图添加一个新图层。加号必须放在每行的末尾,以添加一个图层。您可以通过向 ggplot() 添加一个或多个图层来完成绘图。
geom_point():接下来,您通过添加一个 geom 函数来选择一个 geom。geom_point() 函数使用点创建散点图,geom_bar 函数使用条形图创建条形图,等等。在这种情况下,选择 geom_point 函数来创建点的散点图。ggplot2 包带有许多不同的几何函数。您将在本课程的后面部分了解有关 geoms 的更多信息。
(mapping = aes(x = flipper_length_mm, y = body_mass_g)):ggplot2 中的每个 geom 函数都有一个映射参数。这定义了数据集中的变量如何映射到视觉属性。映射参数始终与 aes() 函数配对。aes() 函数的 x 和 y 参数指定将哪些变量映射到坐标系的 x 轴和 y 轴。在这种情况下,您希望将变量“flipper_length_mm”映射到 x 轴,并将变量“body_mass_g”映射到 y 轴。
4.1.3ggplot() 入门
加号必须放在每行的末尾,以添加一个图层。
要创建一个图,请遵循这三个步骤:从ggplot函数开始,选择一个数据集来处理,添加一个geom_函数来显示你的数据,在aes功能的参数中映射你想要绘制的变量。
要了解有关任何 R 函数的更多信息,只需运行代码问号function_name。例如,如果您想了解更多关于 geom_point 函数,输入问号 geom_point。
4.1.4在 R 中可视化时的常见问题
编码错误是编写代码不可避免的一部分——尤其是当你刚开始学习一门新的编程语言时。在本阅读中,您将学习如何在使用ggplot2创建可视化时识别常见的编码错误。您还将找到一些资源的链接,这些资源可用于帮助解决您可能遇到的任何编码问题。
ggplot2中的常见编码错误
区分大小写
R 代码区分大小写。如果您不小心将某个函数中的第一个字母大写,可能会影响您的代码。这是一个例子:
Glimpse(penguins)
错误消息让您知道 R 找不到名为“Glimpse”的函数:
Error in Glimpse(penguins) : could not find function "Glimpse"
但是您知道函数 glimpse(小写“g”)确实存在。请注意,错误消息并没有准确说明问题所在,但确实为您指明了大致方向。
基于此,您可以确定这是正确的代码:
glimpse(penguins)
平衡括号和引号
另一个常见的 R 编码错误涉及括号和引号。在 R 中,您需要确保函数中的每个左括号都有一个右括号,并且每个左引号都有一个右引号。例如,如果您运行以下代码,则不会发生任何事情。R 不创建绘图。这是因为第二行代码缺少两个右括号:
ggplot(data = penguins) + geom_point(mapping = aes(x = flipper_length_mm, y = body_mass_g
RStudio 确实会提醒您该问题。在 RStudio 源代码编辑器中代码行的左侧,您可能会注意到中间有一个带有白色“X”的红色圆圈。如果您将光标悬停在圆圈上,则会出现以下消息:

RStudio 让您知道您有一个无法匹配的左括号。因此,要更正代码,您知道需要添加一个右括号来匹配每个左括号。
这是正确的代码:
ggplot(data = penguins) + geom_point(mapping = aes(x = flipper_length_mm, y = body_mass_g))
使用加号添加图层
在 ggplot2 中,当您向绘图添加新图层时,您需要在代码中添加一个加号(“+”)。把加号放在错误的地方是一个常见的错误。加号应始终放在代码行的末尾,而不是行首。
这是一个包含不正确放置加号的代码示例:
ggplot(data = penguins) + geom_point(mapping = aes(x = flipper_length_mm, y = body_mass_g))
在这种情况下,R 的错误消息会识别问题,并提示您更正它:
Error: Cannot use `+.gg()` with a single argument. Did you accidentally put + on a new line?
这是正确的代码:
ggplot(data = penguins) + geom_point(mapping = aes(x = flipper_length_mm, y = body_mass_g))
您也可能不小心使用管道而不是加号向绘图添加新图层,如下所示:
ggplot(data = penguins)%>% geom_point(mapping = aes(x = flipper_length_mm, y = body_mass_g))
然后您会收到以下错误消息:
Error: `data` must be a data frame, or other object coercible by `fortify()`, not an S3 object with class gg/ggplot
这是正确的代码:
ggplot(data = penguins) + geom_point(mapping = aes(x = flipper_length_mm, y = body_mass_g))
记住这些问题并在编写代码时注意细节将帮助您减少错误并节省时间,因此您可以专注于您的分析。
4.2在分析中探索美学
4.2.1增强 R 中的可视化
ggplot(data = penguins) +geom_point(mapping = aes(x=flipper_length_mm,y=body_mass_g,color=species))
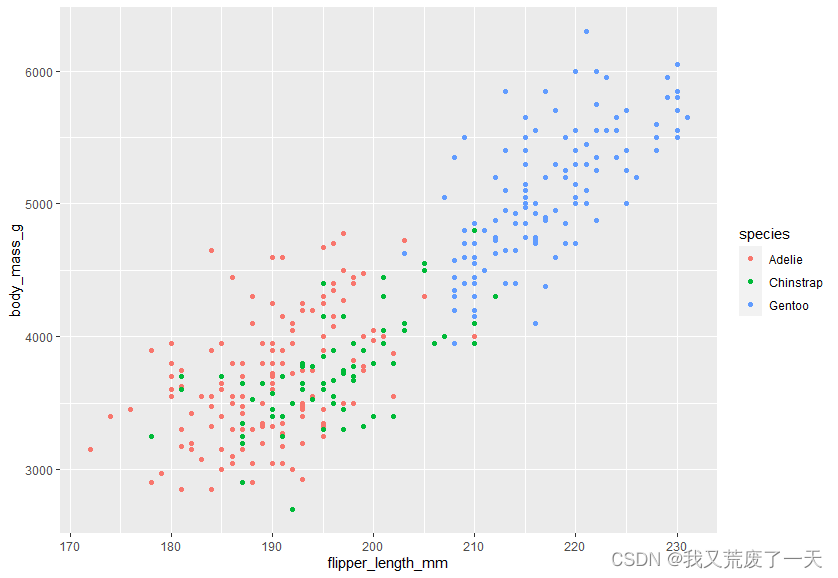
ggplot(data = penguins) +geom_point(mapping = aes(x=flipper_length_mm,y=body_mass_g,shape=species))
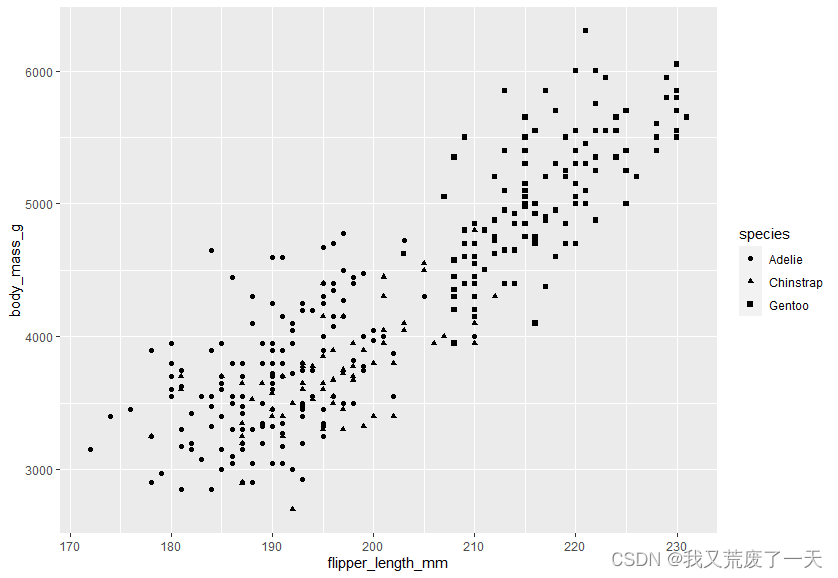
ggplot(data = penguins) +geom_point(mapping = aes(x=flipper_length_mm,y=body_mass_g,shape=species,color=species))
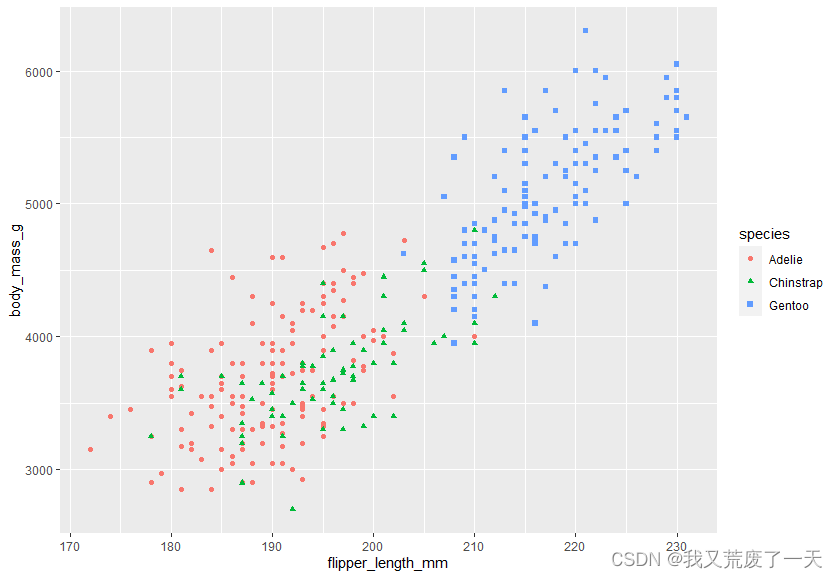
ggplot(data = penguins) +geom_point(mapping = aes(x=flipper_length_mm,y=body_mass_g,shape=species,color=species,size=species))
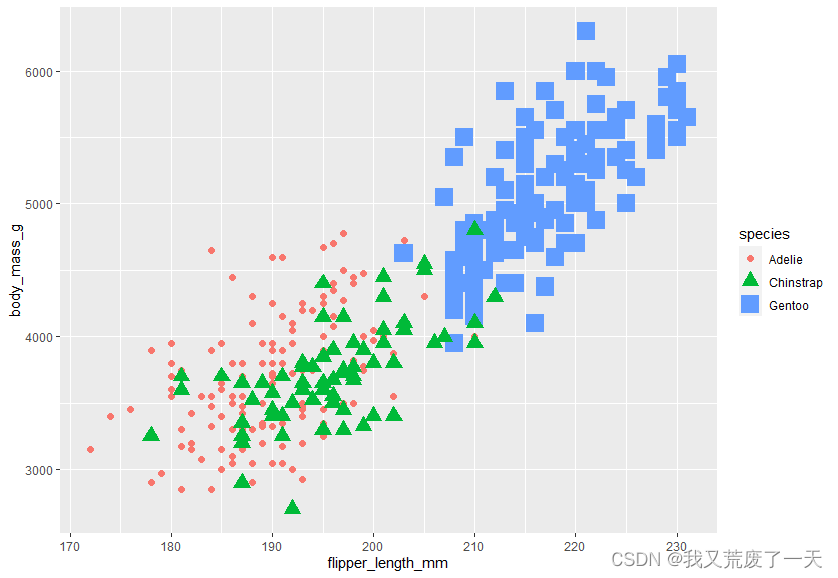
ggplot(data = penguins) +geom_point(mapping = aes(x=flipper_length_mm,y=body_mass_g,alpha=species))
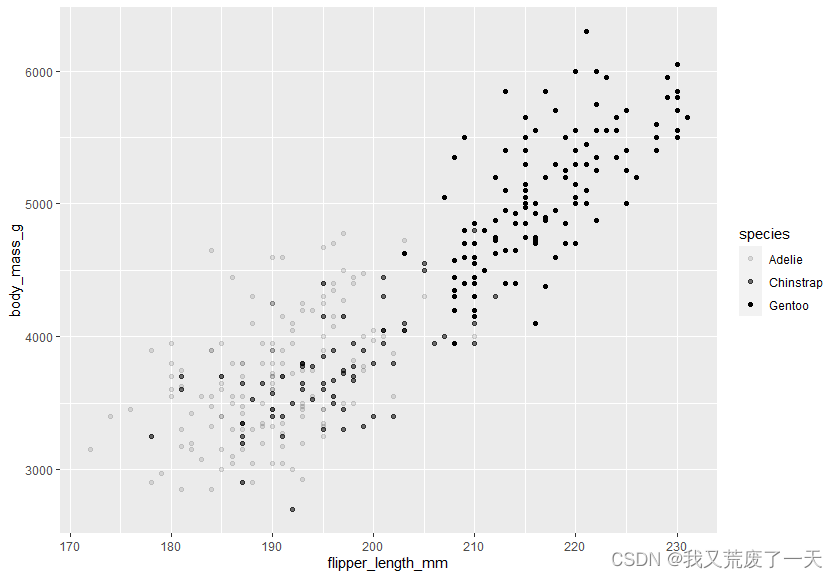
如果我们想改变整体情节的外观而不考虑具体变量,我们在 aes 函数之外编写代码。
ggplot(data = penguins) +geom_point(mapping = aes(x=flipper_length_mm,y=body_mass_g),color='purple')
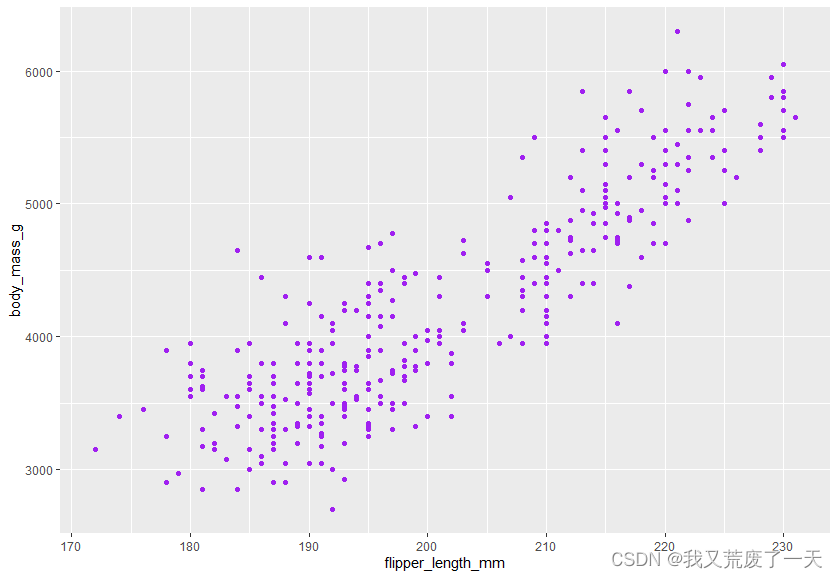
4.2.2审美属性
在本阅读中,您将了解在 R 中创建 ggplot2 可视化时要考虑的三个基本美学属性:颜色、大小和形状。这些属性是使用 ggplot2 创建数据可视化的基本工具,并直接内置在其代码中。
ggplot2 具有三个美学属性:
- 颜色:这允许您更改绘图上所有点的颜色,或每个数据组的颜色
- Size:这允许您按数据组更改绘图上点的大小
- 形状:这允许您按数据组更改绘图上点的形状
ggplot(data, aes(x=distance, y= dep_delay, color=carrier, size=air_time, shape = carrier)) +geom_point()
4.2.3用 ggplot 做更多事情

ggplot(data = penguins) +geom_smooth(mapping = aes(x=flipper_length_mm,y=body_mass_g))
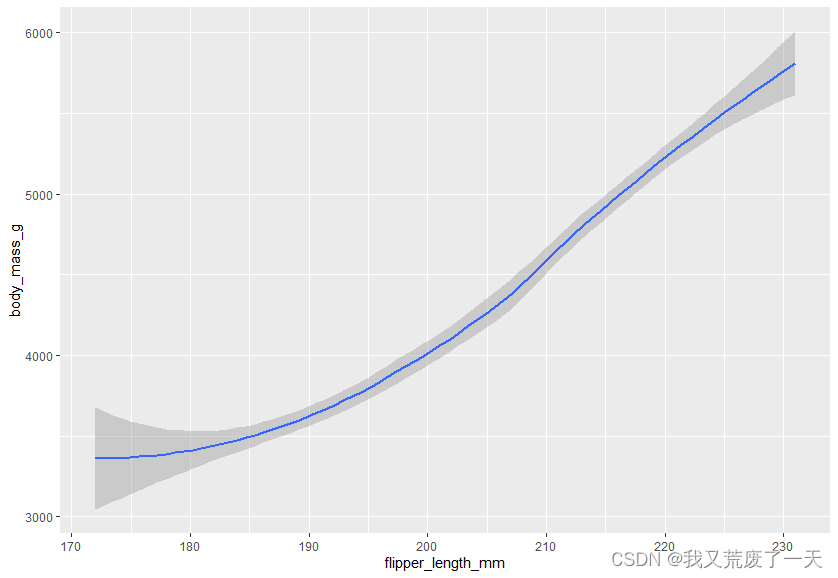
ggplot(data = penguins) +geom_smooth(mapping = aes(x=flipper_length_mm,y=body_mass_g))+geom_point(mapping = aes(x=flipper_length_mm,y=body_mass_g))
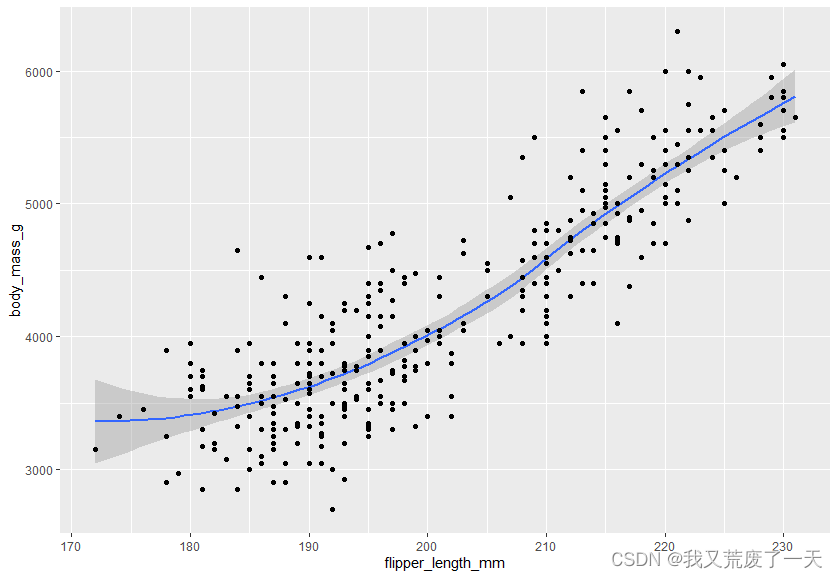
geom_jitter函数创建了一个散点图,然后给图中的每个点添加少量的随机噪声。抖动有助于我们处理过度绘图的问题,这种情况发生在绘图中的数据点相互重叠的时候。抖动使这些点更容易找到。
ggplot(data = penguins) +geom_smooth(mapping = aes(x=flipper_length_mm,y=body_mass_g))+geom_jitter(mapping = aes(x=flipper_length_mm,y=body_mass_g))
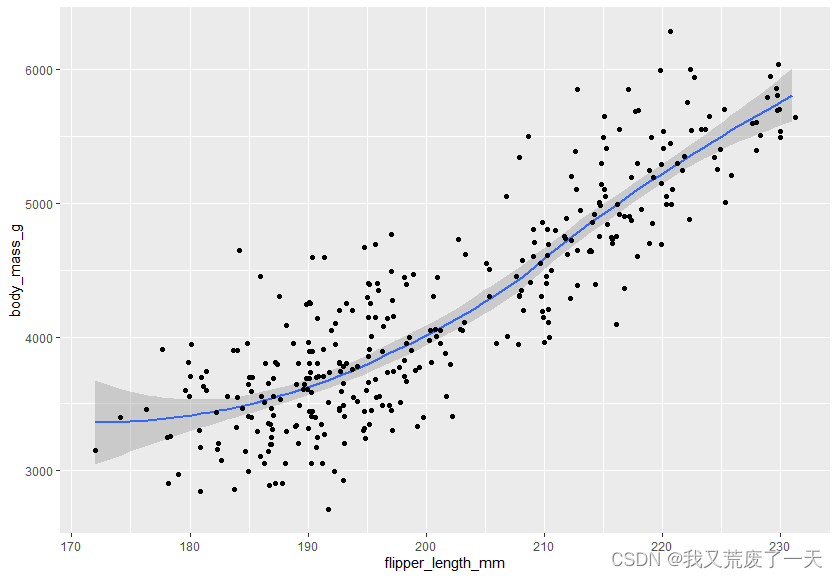
ggplot(data = penguins) +geom_smooth(mapping = aes(x=flipper_length_mm,y=body_mass_g,linetype=species))
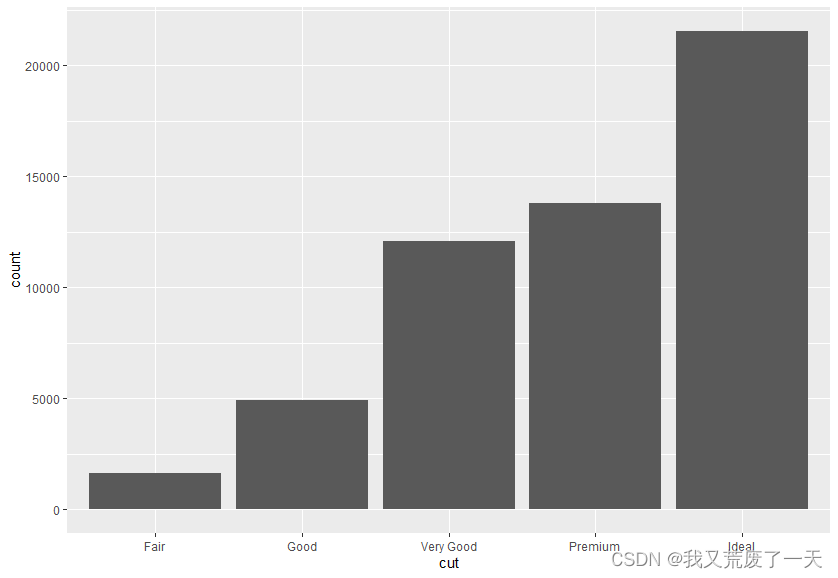
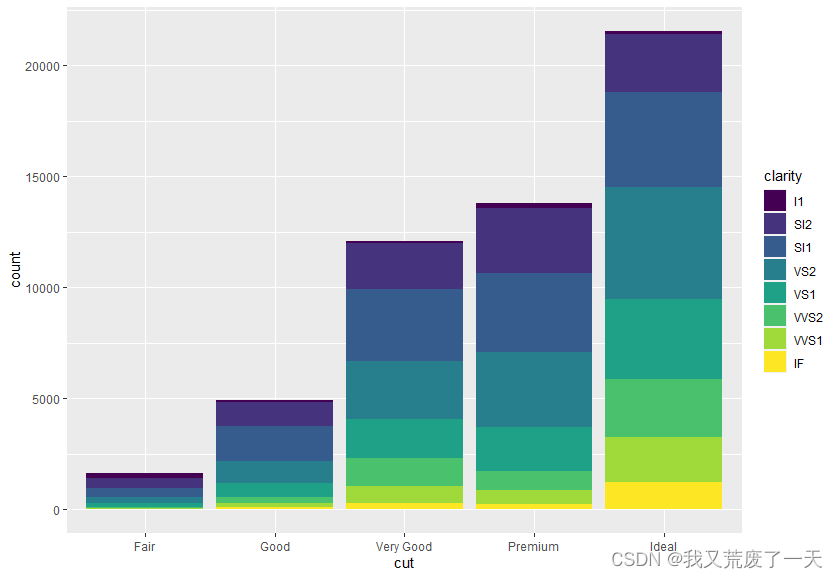
ggplot(data = diamonds) +geom_bar(mapping = aes(x=cut))
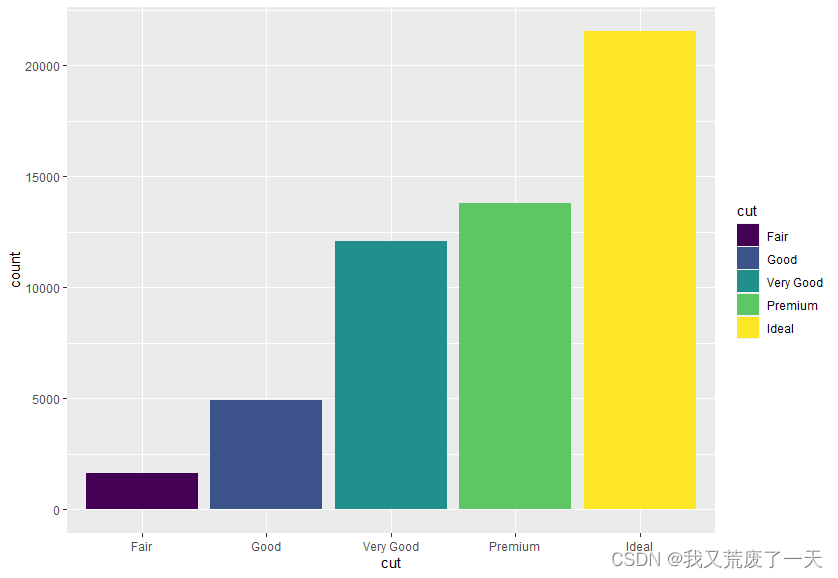
ggplot(data = diamonds) +geom_bar(mapping = aes(x=cut,fill=cut))
ggplot(data = diamonds) +geom_bar(mapping = aes(x=cut,fill=clarity))
4.2.4平滑
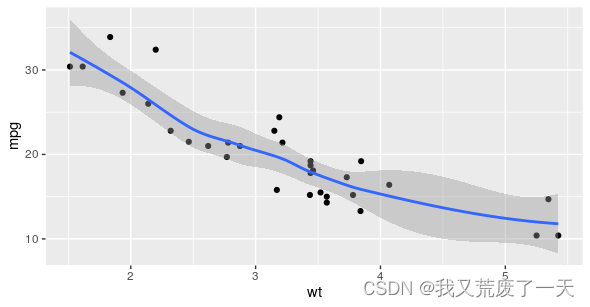
在这篇文章中,您将了解 ggplot2 中的平滑以及如何使用它来使您在 R 中的数据可视化更清晰、更易于理解。有时,仅从散点图很难理解数据的趋势。即使您无法从绘制的数据点轻松注意到趋势,平滑也可以检测数据趋势。Ggplot2 的平滑功能很有帮助,因为它在绘图中添加了一条平滑线作为另一层;平滑线有助于数据对不经意的观察者有意义。
ggplot(data, aes(x=distance,
y= dep_delay)) +geom_point() +geom_smooth()
示例代码创建了一个带有类似于下面蓝线的趋势线的图。

两种类型的平滑
| 平滑类型 | 描述 | 示例代码 |
|---|---|---|
| Loess smoothing | 最适合用于平滑小于1000点的图 | ggplot(data, aes(x=, y=))+ geom_point() + geom_smooth(method="loess") |
| Gam smoothing | 对于平滑有大量点的图是很有用的 | ggplot(data, aes(x=, y=)) + geom_point() + geom_smooth(method="gam", formula = y ~s(x)) |
ggplot2 中的平滑功能有助于使数据图更具可读性,因此您能够更好地识别数据趋势并获得关键见解。下面的第一张图是平滑前的数据,下面的第二张图是平滑后的相同数据。
4.2.4facet function

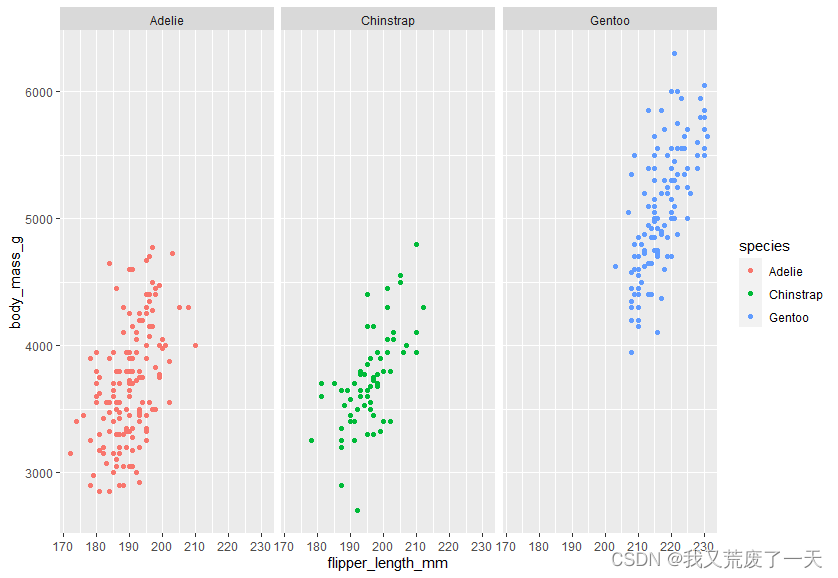
用一个变量来刻面你的情节,使用facet_wrap()
ggplot(data = penguins,aes(x=flipper_length_mm,y=body_mass_g))+geom_point(aes(color=species))+facet_wrap(~species)
用两个变量来刻面你的情节,使用 facet_grid()
ggplot(data = penguins)+geom_point(mapping = aes(x=flipper_length_mm,y=body_mass_g,color=species))+facet_grid(sex~species)
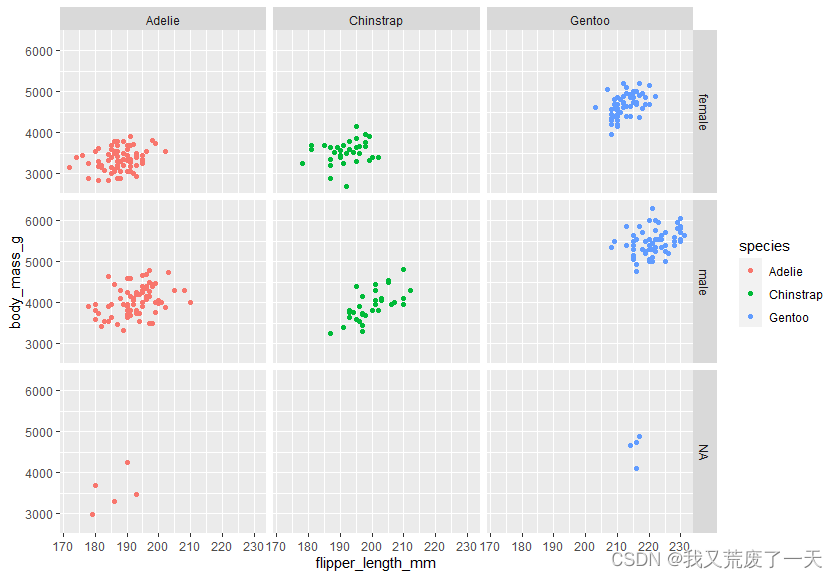
4.2.5过滤和绘图
用于绘图的过滤数据示例
在绘制数据之前过滤数据可以让您专注于数据的特定子集并获得更有针对性的见解。为此,只需在 ggplot 语法中包含 dplyr filter() 函数。
data %>%filter(variable1 == "DS") %>% ggplot(aes(x = weight, y = variable2, colour = variable1)) + geom_point(alpha = 0.3, position = position_jitter()) + stat_smooth(method = "lm")
4.3注释和保存可视化
4.3.1注释层

Labs()
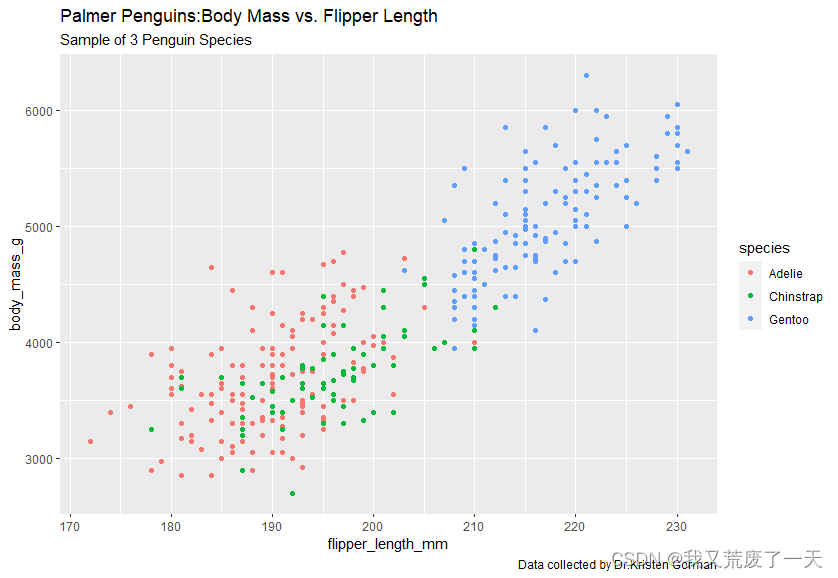
title=标题、subtitle=副标题和caption=字幕是我们放在绘图的网格之外的标签,用于指示重要的信息
ggplot(data=penguins)+geom_point(mapping =aes(x=flipper_length_mm,y=body_mass_g,color=species))+labs(title='Palmer Penguins:Body Mass vs. Flipper Length',subtitle = 'Sample of 3 Penguin Species',caption = 'Data collected by Dr.Kristen Gorman')
Annotate()
ggplot(data=penguins)+geom_point(mapping =aes(x=flipper_length_mm,y=body_mass_g,color=species))+labs(title='Palmer Penguins:Body Mass vs. Flipper Length',subtitle = 'Sample of 3 Penguin Species',caption = 'Data collected by Dr.Kristen Gorman')+annotate("text",x=220,y=3500,label = 'The Gentoos are Largest',color='purple',fontface = 'bold',size=4.5,angle=25)
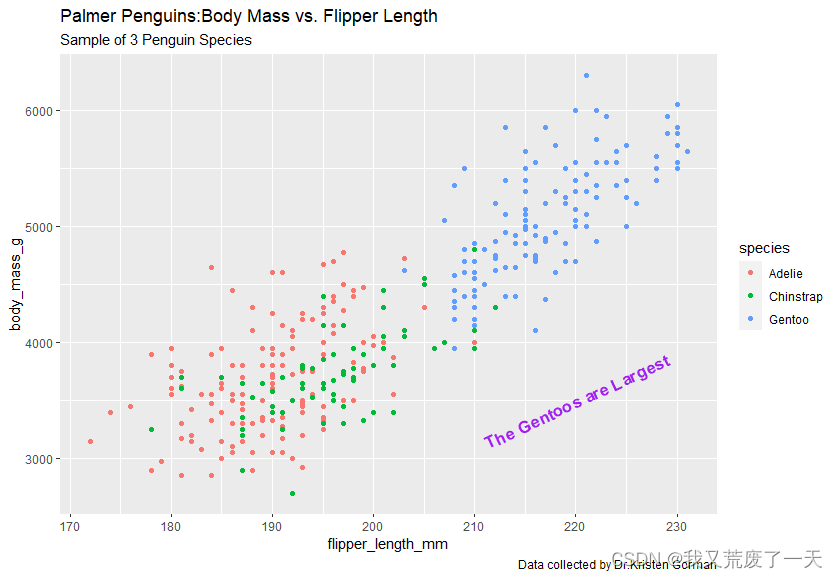
也可以断开利用变量命名
p <-ggplot(data=penguins)+geom_point(mapping =aes(x=flipper_length_mm,y=body_mass_g,color=species))+labs(title='Palmer Penguins:Body Mass vs. Flipper Length',subtitle = 'Sample of 3 Penguin Species',caption = 'Data collected by Dr.Kristen Gorman')p+annotate("text",x=220,y=3500,label = 'The Gentoos are Largest',color='purple')
4.3.2保存您的可视化

Export option
ggsave()
Ggsave 是一个保存绘图的有用函数。它默认为保存你最后显示的绘图,并使用当前图形设备的尺寸。
ggsave("Three Penguin Species.png")
这个ggsave()图像的默认尺寸是7x7.
如果你想让你的图表变得更大,更长方形以适应幻灯片演示,你可以在ggsave()命令中指定.png的高度和宽度。编辑下面的代码块,创建一个16x8的.png图片。
ggsave('hotel_booking_chart.png',width=16,height=8)
4.3.3不使用 ggsave() 保存图像
在大多数情况下,ggsave()是保存绘图的最简单方法。但是在某些情况下,最好通过将绘图直接写入图形设备来保存绘图。本篇文章将介绍一些不使用 ggsave() 即可保存图像和绘图的不同方法,并包含其他资源,如果您想了解更多信息,请查看这些资源。
图形设备允许绘图出现在您的计算机上。示例包括:
-
计算机上的窗口(屏幕设备)
-
PDF、PNG 或 JPEG 文件(文件设备)
-
SVG 或可缩放矢量图形文件(文件设备)
在 R 中绘制绘图时,必须将其“发送”到特定的图形设备。要在不使用 ggsave() 的情况下保存图像,可以打开 R 图形设备,如png()或pdf();这些将允许您将绘图保存为 .png 或 .pdf 文件。您还可以选择打印绘图,然后使用dev.off()关闭设备。
使用 png() 的示例
png(file = "exampleplot.png", bg = "transparent")
plot(1:10)
rect(1, 5, 3, 7, col = "white")
dev.off()
使用 pdf() 的示例
pdf(file = "/Users/username/Desktop/example.pdf", width = 4, height = 4)
plot(x = 1:10, y = 1:10)
abline(v = 0)
text(x = 0, y = 1, labels = "Random text")
dev.off()
5.文档和报告
当您准备好保存和展示您的分析时,R 有许多不同的选项可供探索。在这部分课程中,您将探索 R Markdown,这是一种使用 R 制作动态文档的文件格式。您将学习如何格式化和导出 R Markdown,以及如何将 R 代码块合并到您的文档中。
Markdown is a syntax for formatting plain text files.
Markdown是一种用于格式化纯文本文件的语法。
一个R notebook是一个交互式的R Markdown选项。它可以让用户从R Markdown文档中运行代码,并显示图表和图形来可视化该代码。
5.1在 RStudio 中开发文档和报告
5.1.1在 RStudio 中使用 R Markdown
File - new file -r markdwon
但如果我们想产生一个包含所有文本、代码和结果的报告,我们需要点击Knit按钮。
R Markdown文件可以转换为HTML、PDF和Word、幻灯片演示或仪表板。它们通常不能被转换为图像文件。
添加代码有两种快捷方式。在键盘上,您可以按Ctrl + Alt + I (PC) 或Cmd + Option + I (Mac)。或者您可以单击编辑器工具栏中的添加块命令:
要将代码块添加到 Rmd 文件,请按照下列步骤操作:
-
单击 Rmd 文件最后一行的末尾。使用前面提到的任一快捷方式来创建代码块。
-
在默认代码块后按Enter (Windows) 或Return (Mac) 两到三下,在现有代码块和您将添加的下一个代码块之间创建空间。
-
从您之前打开的分析文件中复制代码并将其粘贴到开始和结束分隔符之间的灰色区域。
-
选择文件中剩余的模板内容并删除。这为您提供了一个空白空间来帮助避免将您自己的注释和代码与模板中预先存在的注释和代码混合起来的潜在错误。
要格式化笔记本中的注释,请执行以下步骤:
-
单击您添加的代码块上方但在 YAML 部分下方的一行。
-
使用单个主题标签为您的报告键入主标题。您可能希望以不同的方式重述 YAML 中的标题或添加简短描述。
-
在其下方添加一个较小的标题来标记您的编程的第一部分。紧随其后的是您添加的代码块的描述。
5.2创建 R Markdown 文档
5.2.1Markdown文档的结构
这是YAML的标题部分,YAML 是一种用于翻译数据的语言,因此它是可读的。在RMD文件中,这部分基本上是元数据或关于文件其余部分的数据。当你创建一个新的文件时,输出的标题、作者、日期和文件类型会自动包括在内。
5.3了解代码块和导出
5.3.1将代码块添加到您的 RMarkdown 笔记本
- 打开一个新的 R Markdown 笔记本并创建一个代码块部分。可以使用键盘快捷键Ctrl + Alt + I (Windows) 或Cmd + Option + I (Mac)快速插入笔记本块。也可以使用编辑器工具栏中的插入菜单添加代码块。
代码块使用三个刻度标记,后跟一个大括号、描述性文本和一个闭合的大括号。然后,您有一个空白空间来添加适当的代码。这是一般语法:

创建代码块时,请记住代码块的输出将在执行时立即出现在块之后。因此,将产生多个输出的块拆分为两个或多个块是一种很好的做法。这样,每个代码块只产生一个输出,用户可以更轻松地执行和探索。
-
使用 ggplot() 可视化中的代码,创建两个新块。在第一个代码块中键入以下内容以调用所需的库、加载企鹅数据并返回企鹅数据的视图:

请注意,代码块的唯一输出是作为 View 函数结果的数据的表格视图。 -
然后,在第二个代码块中键入以下内容以创建可视化:

5.3.2导出文档
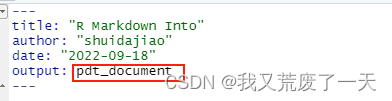
也可以更改yaml中的output格式,再按knit就自动导出成pdf了
5.3.3R Markdown 中的输出格式
可用的文件输出
除了默认的 HTML 输出(html_document)之外,您还可以使用以下输出设置在 R Markdown 中创建其他类型的文档:
- pdf_document – 这将使用 LaTeX(一个开源文档布局系统)创建一个 PDF 文件。如果你还没有 LaTeX,RStudio 会自动提示你安装它。
- word_document – 这将创建一个 Microsoft Word 文档 (.docx)。
- odt_document – 这将创建一个 OpenDocument 文本文档 (.odt)。
- rtf_document – 这将创建一个富文本格式文档 (.rtf)。
- md_document - 这将创建一个 Markdown 文档(严格符合原始 Markdown 规范)
- github_document - 这将创建一个 GitHub 文档,该文档是 Markdown 文档的自定义版本,旨在在 GitHub 上共享。
演示文稿
当您使用以下输出设置时,R Markdown 会将文件呈现为特定的演示格式:
- beamer_presentation – 用于带有 beamer 的 PDF 演示文稿
- ioslides_presentation – 用于带有 ioslides 的 HTML 演示文稿
- slidy_presentation – 使用 Slidy 进行 HTML 演示
- powerpoint_presentation – 用于 PowerPoint 演示文稿
- revealjs : :revealjs_presentation - 用于带有reveal.js的HTML演示文稿(用于创建需要reveal.js包的HTML演示文稿的框架)
仪表板
仪表板是快速传达大量信息的有用方式。flexdashboard包允许您将一组相关的数据可视化发布为仪表板。Flexdashboard 还提供用于创建侧边栏、选项卡集、值框和仪表的工具。
Shiny
Shiny是一个 R 包,可让您使用 R 代码构建交互式 Web 应用程序。您可以将应用程序嵌入 R Markdown 文档或将它们托管在网页上。
要从 R Markdown 文档调用 Shiny 代码,请将 runtime: shiny 添加到 YAML 标头:
---title: "Shiny Web App"output: html_documentruntime: shiny---