R语言常用代码
基本命令
q():退出R程序
tab:自动补全
ctrl+L:清空工作环境
ESC:中断当前计算
head(X):查看数据集前6行数据
tail(X):查看数据集尾6行数据安装所需要的包
# 安装包
install.packages("packagename")# 加载包
library(packagesname)设置工作路径
// 使用getwd()函数来显示当前工作目录;
getwd()//使用setwd()函数更改当前目录;
setwd("D:/R")
数据的读取与保存
# 读取csv
data <- read.csv('data.csv')
# 读取 R格式数据
data <- load('.RData')# 保存 R格式数据
save(data,file = 'name.Rdata')
# 保存 csv格式数据
write.csv(data,file = 'name.csv')
循环语句
//while loop
a <- 2
while(a<5){print('hello')a = a + 1
}//for loop
v <- c(1,2,5,7,9,6)
for(i in v){print(i)
}
数据操作
//删除数据
#删除第3列
data <- data[,-3]
#剔除掉第1,2,18列
arpu <- arpu[,-c(1,2,18)]
#剔除掉第1,2,3,,4,5,18行
arpu <- arpu[-c(1:5,18),]//筛选数据
iris[which((iris$Species== 'setosa') | (iris$Species == 'virginica')), ]给数据的行命名
names(data1)=c("YEAR", "MNTH", "DAY","PRCP", "RHUM", "WIND")
合并两个数据
Data=rbind(rundata,rundata1)
将结果存入文件
result=c(Sum_SRAD,Ave_RHUM,Sum_PRCP,Ave_T)#resultname=Filename#给结果文件命名Result=paste(Filename,"Result.csv")print(Result)sink(Result,append=TRUE,split=TRUE)print(result)sink()
绘图部分
链接: 绘图参数介绍.
链接: 坐标轴,图例设置.
####多种颜色展示,需要RColorBrewer包
png("~/plotSamples.png",width=9,height=9,unit="in",res=108) #在工作目录下创建plotSamples.png图
par(mfcol=c(2,2))
color<-colorRampPalette(c("red","yellow","blue"))(30)
plot(1:30,col=color,pch=20,cex=2,main="1:30")
plot(1:10,col=color,pch=20,cex=2,main="1:10")
plot(1:90,col=color,pch=20,cex=2,main="1:90")
plot(1:900,col=color,pch=20,cex=2,main="1:900")
dev.off()###直方图添加正太曲线
hist(h,prob=T,col="light blue")
lines(density(x), col="red", lwd=3)
###QQ图添加拟合线
qqnorm(h, main="QQ图与直方图")
qqline(h, col="red",lwd=2)
#添加标注,X,Y是对应坐标的向量,labels是标记值,adj调整标注位置
text(X,Y,labels=c(1,2,3),adj=1.2)
#添加一条水平线h或者是回归模型直线,垂线v;lty为2表示绘制虚线
abline(h = <int>,lty=2)
#画一条y=a+bx的直线
abline(a,b)
#画个点,坐标为向量x,y
points(x,y)
#画一条线,坐标为向量x,y
lines(x,y)
#绘制坐标轴,低级绘图,side为2是纵坐标
axis(side=1,at=seq(from=0.5,by=1.7,length.out=4),labels=c())x=c(45,21,5,42,51,254,12,54,125,45,4)
h=hist(x, breaks=10, col=1, xlab="##", main="##") ##xlab参数用来设置X轴标签,main参数用来设置图片的主标题
xfit=seq(min(x),max(x),length=40)##生成从X的最小值到最大值的等间距的40个数
yfit<-dnorm(xfit,mean=mean(x),sd=sd(x))##使用dnorm()函数生成服从正态分布的概率密度函数值
yfit <- yfit*diff(h$mids[1:2])*length(x)##在这里diff()函数是计算两数之差,也即直方图的组距;这一行是计算出模拟的Y值,为后续绘图做准备。
lines(xfit, yfit, col="blue", lwd=2) ##绘制密度图形,lwd指的是线宽。
# Kernel 密度图
d = density(x) # density()函数获取概率密度数据
plot(d) # 绘制结果
输入与输出函数
#readline()一次只能输入一行
> a <- readline()
Hello World
> a
[1] "Hello World"# scan()函数
> x <- scan()
1: 34
2: 67
3: 9
4: 7
5:
Read 4 items
> x
[1] 34 67 9 7#print(函数)
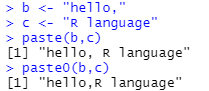
print(paste("字符串: ",n))