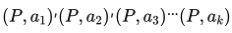目录
一.前言
二.下载数据文件
三.导包并设置使用GPU
四.加载和预处理数据
五.为模型准备数据
一.前言
最近ChatGPT大火,成功破圈,到底是个啥?
简单说,它是一个模型,一个语言模型!它是以对话方式与人进行交互的AI语言模型!
在很早以前,国内的大厂百度,就开发过“文心·NLP模型”等语言处理模型,比如用文心·NLP模型生成段落和文章,能做到开篇和文末点题,首位呼应,对文本相关内容进行引用等……
文心·NLP模型总体效果一般,有点差强人意,特别是在人类文字和人类语言的理解方面,有很多不融洽,输出的内容很多都存在衔接生硬牵强的问题。
也正因为如此,所以它也一直不温不火,只有少数相关公司和研究人工智能与机器学习的用户知道它,以前我了解后,觉得还有很长的路要走。
但这几天的ChatGPT明显不一样,对很多不懂不关注相关技术的人,都展示出了极强的吸引力,ChatGPT短短一周不到的时间,用户达到百万级,成功破圈,说明它是有值得研究的地方的。
在本教程中,我们探索一个好玩有趣的循环的序列到序列(sequence-to-sequence)的模型用例。我们将用Cornell Movie-Dialogs Corpus 处的电影剧本来训练一个简单的聊天机器人。
在人工智能研究领域中,对话模型是一个非常热门的话题。聊天机器人可以在各种设置中找到,包括客户服务应用和在线帮助。这些机器人通常 由基于检索的模型提供支持,这些模型的输出是某些形式问题预先定义的响应。在像公司IT服务台这样高度受限制的领域中,这些模型可能足够了, 但是,对于更一般的用例它们还不够健壮。让一台机器与多领域的人进行有意义的对话是一个远未解决的研究问题。最近,深度学习热潮已经允许 强大的生成模型,如谷歌的神经对话模型Neural Conversational Model,这标志着向多领域生成对话模型迈出了一大步。 在本教程中,我们将在PyTorch中实现这种模型。

教程要点
- 对Cornell Movie-Dialogs Corpus数据集的加载和预处理
- 用Luong attention mechanism(s)实现一个sequence-to-sequence模型
- 使用小批量数据联合训练解码器和编码器模型
- 实现贪婪搜索解码模块
- 与训练好的聊天机器人互动
二.下载数据文件
下载数据文件点击这里并将其放入到当前目录下的data/ 文件夹下。
三.导包并设置使用GPU
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literalsimport torch
from torch.jit import script, trace
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import csv
import random
import re
import os
import unicodedata
import codecs
from io import openimport itertools
import mathUSE_CUDA = torch.cuda.is_available()
device = torch.device("cuda" if USE_CUDA else "cpu")四.加载和预处理数据
#**********************************2.加载和预处理数据**********************************
'''
下一步就是格式化处理我们的数据文件并将数据加载到我们可以使用的结构中。
Cornell Movie-Dialogs Corpus是一个丰富的电影角色对话数据集: * 10,292 对电影角色之间的220,579次对话 * 617部电影中的9,035个电影角色 * 总共304,713发言量
这个数据集庞大而多样,在语言形式、时间段、情感上等都有很大的变化。我们希望这种多样性使我们的模型能够适应多种形式的输入和查询。
首先,我们通过数据文件的某些行来查看原始数据的格式
'''
corpus_name = "cornell movie-dialogs corpus"
corpus = os.path.join("data", corpus_name)def printLines(file, n=10):with open(file, 'rb') as datafile:lines = datafile.readlines()#输出前n行的数据for line in lines[:n]:print(line)#printLines(os.path.join(corpus, "movie_lines.txt"))#**************************************2.1创建格式化数据文件 start **************************************
'''
为了方便起见,我们将创建一个格式良好的数据文件,其中每一行包含一个由tab制表符分隔的查询语句和响应语句对。
以下函数便于解析原始 movie_lines.txt 数据文件。
* loadLines:将文件的每一行拆分为字段(lineID, characterID, movieID, character, text)组合的字典
* loadConversations :根据movie_conversations.txt将loadLines中的每一行数据进行归类
* extractSentencePairs: 从对话中提取句子对
'''
# 将文件的每一行拆分为字段字典
#fields中是各列字段的名字,即["lineID", "characterID", "movieID", "character", "text"]
def loadLines(fileName, fields):lines = {}with open(fileName, 'r', encoding='iso-8859-1') as f:for line in f:values = line.split(" +++$+++ ")# Extract fieldslineObj = {}for i, field in enumerate(fields):lineObj[field] = values[i]#每一个键值对对应一行数据,键是这一行的lineID,值是这一行对应的数据对象,即lineObj是字典(lines)里的字典lines[lineObj['lineID']] = lineObj#lines是对整个movie_lines.txt文件操作之后返回的含有格式化原数据的字典return lines# 将 `loadLines` 中的行字段分组为基于 *movie_conversations.txt* 的对话
#utterance话语
#fields中是各列字段的名字,即["character1ID", "character2ID", "movieID", "utteranceIDs"]
def loadConversations(fileName, lines, fields):conversations = []with open(fileName, 'r', encoding='iso-8859-1') as f:for line in f:values = line.split(" +++$+++ ")# Extract fields,和上面的那个函数的lineObj一个道理,即把movie_conversations.txt的每行的数据提取到一个字典中convObj = {}for i, field in enumerate(fields):convObj[field] = values[i]# Convert string to list (convObj["utteranceIDs"] == "['L598485', 'L598486', ...]")#eval函数的作用自行百度,就是会把字符串里的表达式进行计算lineIds = eval(convObj["utteranceIDs"])# Reassemble lines,Reassemble:重新组装convObj["lines"] = [] #给字典新加一个键值对,此键为linesfor lineId in lineIds:#即根据lineId把上面那个函数格式化的每行对应的字典对象添加到字典convObj的lines对应的值中convObj["lines"].append(lines[lineId])conversations.append(convObj)# conversations是对整个movie_conversations.txt文件操作之后返回的含有格式化原数据的字典return conversations# 从对话中提取一对句子
def extractSentencePairs(conversations):qa_pairs = []for conversation in conversations:# Iterate over all the lines of the conversationfor i in range(len(conversation["lines"]) - 1): # We ignore the last line (no answer for it)#strip函数返回删除前导和尾随空格的字符串副本。如果给定了chars而不是None,则删除chars中的字符。inputLine = conversation["lines"][i]["text"].strip()targetLine = conversation["lines"][i+1]["text"].strip()# Filter wrong samples (if one of the lists is empty)if inputLine and targetLine:qa_pairs.append([inputLine, targetLine])#提取了文件中的所有对话return qa_pairs#******************************现在我们将调用这些函数来创建文件,我们命名为formatted_movie_lines.txt。******************************
# 定义新文件的路径(待生成)
datafile = os.path.join(corpus, "formatted_movie_lines.txt")'''
#delimiter:分隔符
delimiter = '\t'
#print('delimiter:',delimiter)
# codecs.decode()方法的使用参考https://zhuanlan.zhihu.com/p/377436438
delimiter = str(codecs.decode(delimiter, "unicode_escape"))
#print('delimiter:',delimiter)# 初始化行dict,对话列表和字段ID
lines = {}
conversations = []
MOVIE_LINES_FIELDS = ["lineID", "characterID", "movieID", "character", "text"]
MOVIE_CONVERSATIONS_FIELDS = ["character1ID", "character2ID", "movieID", "utteranceIDs"]# 加载行和进程对话,即调用函数进行格式化
print("\nProcessing corpus...")
lines = loadLines(os.path.join(corpus, "movie_lines.txt"), MOVIE_LINES_FIELDS)
print("\nLoading conversations...")
conversations = loadConversations(os.path.join(corpus, "movie_conversations.txt"),lines, MOVIE_CONVERSATIONS_FIELDS)# 写入新的csv文件
print("\nWriting newly formatted file...")
with open(datafile, 'w', encoding='utf-8') as outputfile:writer = csv.writer(outputfile, delimiter=delimiter, lineterminator='\n')pairs=extractSentencePairs(conversations)print('句子对数为:',pairs.__len__())for pair in pairs:writer.writerow(pair)# 打印一个样本的行
print("\nSample lines from file:")
printLines(datafile)
'''
#**************************************2.1创建格式化数据文件 end **************************************#*******************************2.2 加载和清洗数据 start *******************************
'''
我们下一个任务是创建词汇表并将查询/响应句子对(对话)加载到内存。
注意我们正在处理词序,这些词序没有映射到离散数值空间。因此,我们必须通过数据集中的单词来创建一个索引。
为此我们创建了一个Voc类,它会存储从单词到索引的映射、索引到单词的反向映射、每个单词的计数和总单词量。
这个类提供向词汇表中添加单词的方法(addWord)、添加所有单词到句子中的方法 (addSentence) 和清洗不常见的单词方法(trim)。更多的数据清洗在后面进行。
'''
# 默认词向量
PAD_token = 0 # Used for padding short sentences
SOS_token = 1 # Start-of-sentence token
EOS_token = 2 # End-of-sentence tokenclass Voc:def __init__(self, name):self.name = nameself.trimmed = False#单词的索引号(键是单词,值是索引)self.word2index = {}#各个单词的数量(键是单词,值是数量)self.word2count = {}#通过索引可以找到单词self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}#单词序号,012已经被使用,所以就从3开始了self.num_words = 3 # Count SOS, EOS, PAD#把句子中的每一个单词查出来执行添加单词的操作def addSentence(self, sentence):for word in sentence.split(' '):self.addWord(word)def addWord(self, word):##如果之前没遇到过这个单词if word not in self.word2index:#这个单词的序号self.word2index[word] = self.num_words#这个单词的总数self.word2count[word] = 1#通过单词序号找到单词self.index2word[self.num_words] = wordself.num_words += 1else:#如果之前已经遇到了这个单词那么只对单词总数+1self.word2count[word] += 1# 删除低于特定计数阈值的单词,即单词出现频率太低def trim(self, min_count):if self.trimmed:returnself.trimmed = Truekeep_words = []for k, v in self.word2count.items():if v >= min_count:keep_words.append(k)print('keep_words {} / {} = {:.4f}'.format(#len(self.word2index)即代表总的单词数len(keep_words), len(self.word2index), len(keep_words) / len(self.word2index)))# 重初始化字典self.word2index = {}self.word2count = {}self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}self.num_words = 3 # Count default tokensfor word in keep_words:self.addWord(word)'''
现在我们可以组装词汇表和查询/响应语句对。在使用数据之前,我们必须做一些预处理。
首先,我们必须使用unicodeToAscii将 unicode 字符串转换为 ASCII。
然后,我们应该将所有字母转换为小写字母并清洗掉除基本标点之 外的所有非字母字符 (normalizeString)。
最后,为了帮助训练收敛,我们将过滤掉长度大于MAX_LENGTH 的句子 (filterPairs)。
'''
MAX_LENGTH = 10 # Maximum sentence length to consider# 将Unicode字符串转换为纯ASCII,多亏了https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn')# Lowercase, trim, and remove non-letter characters
def normalizeString(s):s = unicodeToAscii(s.lower().strip())#re.sub函数作用:https://blog.csdn.net/weixin_44799217/article/details/115100715s = re.sub(r"([.!?])", r" \1", s)s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)s = re.sub(r"\s+", r" ", s).strip()return s# 初始化Voc对象 和 格式化pairs对话存放到list中
# datafile就是我们上面生成的formatted_movie_lines.txt
#corpus_name就是"cornell movie-dialogs corpus"
def readVocs(datafile, corpus_name):print("Reading lines...")# Read the file and split into lineslines = open(datafile, encoding='utf-8').read().strip().split('\n')# Split every line into pairs and normalizepairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]voc = Voc(corpus_name)return voc, pairs# 如果对 'p' 中的两个句子都低于 MAX_LENGTH 阈值,则返回True,即合法
#p是句子对
def filterPair(p):# Input sequences need to preserve the last word for EOS token#一对句子中只要有一个句子里的单词数超过≥MAX_LENGTH就不合法!所以很多句子都被筛去了return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH# 过滤满足条件的 pairs 对话
def filterPairs(pairs):# 返回合法句子对的集合return [pair for pair in pairs if filterPair(pair)]# 使用上面定义的函数,返回一个填充的voc对象和对列表
def loadPrepareData(corpus, corpus_name, datafile, save_dir):print("Start preparing training data ...")voc, pairs = readVocs(datafile, corpus_name)print("Read {!s} sentence pairs".format(len(pairs)))pairs = filterPairs(pairs)print("Trimmed to {!s} sentence pairs".format(len(pairs)))print("Counting words...")for pair in pairs:voc.addSentence(pair[0])voc.addSentence(pair[1])print("Counted words:", voc.num_words)return voc, pairs# 加载/组装voc和对
save_dir = os.path.join("data", "save")
voc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)
# 打印一些对进行验证
# print("\npairs:")
# for pair in pairs[:10]:
# print(pair)'''
另一种有利于让训练更快收敛的策略是去除词汇表中很少使用的单词。减少特征空间也会降低模型学习目标函数的难度。
我们通过以下两个步 骤完成这个操作:
* 使用voc.trim函数去除 MIN_COUNT 阈值以下单词 。
* 如果句子中包含词频过小的单词,那么整个句子也被过滤掉。
'''
MIN_COUNT = 3 # 修剪的最小字数阈值def trimRareWords(voc, pairs, MIN_COUNT):# 修剪来自voc的MIN_COUNT下使用的单词,即单词出现频率低于MIN_COUNT的话那么就会筛掉voc.trim(MIN_COUNT)# Filter out pairs with trimmed wordskeep_pairs = []for pair in pairs:input_sentence = pair[0]output_sentence = pair[1]keep_input = Truekeep_output = True# 检查输入句子for word in input_sentence.split(' '):if word not in voc.word2index:keep_input = Falsebreak# 检查输出句子for word in output_sentence.split(' '):if word not in voc.word2index:keep_output = Falsebreak# 只保留输入或输出句子中不包含修剪单词的对if keep_input and keep_output:keep_pairs.append(pair)print("Trimmed from {} pairs to {}, {:.4f} of total".format(len(pairs), len(keep_pairs), len(keep_pairs) / len(pairs)))return keep_pairs# 修剪voc和对
pairs = trimRareWords(voc, pairs, MIN_COUNT)
# for pair in pairs[:10]:
# print(pair)
#*******************************2.2 加载和清洗数据 end *******************************
#**********************************2.加载和预处理数据**********************************五.为模型准备数据
尽管我们已经投入了大量精力来准备和清洗我们的数据,将它变成一个很好的词汇对象和一系列的句子对,但我们的模型最终希望数据以 numerical torch张量作为输入。可以在seq2seq translation tutorial 中找到为模型准备处理数据的一种方法。 在该教程中,我们使用batch size大小为1,这意味着我们所要做的就是将句子对中的单词转换为词汇表中的相应索引,并将其提供给模型。
但是,如果你想要加速训练或者想要利用GPU并行计算能力,则需要使用小批量mini-batches来训练。
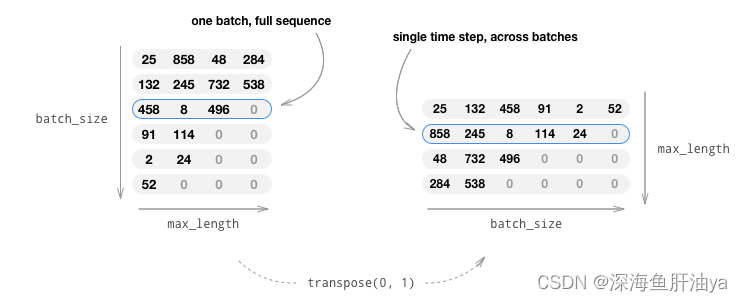
使用小批量mini-batches也意味着我们必须注意批量处理中句子长度的变化。为了容纳同一batch中不同大小的句子,我们将使我们的批量输 入张量大小(max_length,batch_size),其中短于max_length的句子在EOS_token之后进行零填充(zero padded)。
如果我们简单地将我们的英文句子转换为张量,通过将单词转换为索引indicesFromSentence和零填充zero-pad,我们的张量的大小将是 (batch_size,max_length),并且索引第一维将在所有时间步骤中返回完整序列。但是,我们需要沿着时间对我们批量数据进行索引并且包 括批量数据中所有序列。因此,我们将输入批处理大小转换为(max_length,batch_size),以便跨第一维的索引返回批处理中所有句子的时 间步长。 我们在zeroPadding函数中隐式处理这个转置。
#*******************************3.为模型准备数据 start *******************************
def indexesFromSentence(voc, sentence):#print([3,3,3]+[2])输出[3, 3, 3, 2],即输出句子中每个单词的序号,最后一个序号是结束符号符的数字2return [voc.word2index[word] for word in sentence.split(' ')] + [EOS_token]# zip 对数据进行合并了,相当于行列转置了
def zeroPadding(l, fillvalue=PAD_token):#参数前加一个星号,将传递进来的参数放在同一个元组中,该参数的返回值是一个元组# (在本案例中即把indexesFromSentence返回的列表转化成元组)# itertools.zip_longest作用参考https://blog.csdn.net/yiweiwei516/article/details/118182889return list(itertools.zip_longest(*l, fillvalue=fillvalue))# 记录 PAD_token的位置为0, 其他的为1
def binaryMatrix(l, value=PAD_token):m = []for i, seq in enumerate(l):#即m是一个二维矩阵,一行就对应一个句子,然后用0/1来表示句子中单词是否为填充符m.append([])for token in seq:if token == PAD_token:m[i].append(0)else:m[i].append(1)return m# 返回填充前(加入结束index EOS_token做标记)的长度 和 填充后的输入序列张量
def inputVar(l, voc):#返回值是列表里套列表,每个列表里是每个句子里的各单词对应的索引序号indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]#indexes就是里层的单个列表,lengths也是个列表,然后转换成了张量,里面每个值对应了每个句子的长度lengths = torch.tensor([len(indexes) for indexes in indexes_batch])# 填充加转置,返回值是列表里面套一个个元组padList = zeroPadding(indexes_batch)#torch.LongTensor是64位整型padVar = torch.LongTensor(padList)return padVar, lengths# 返回填充前(加入结束index EOS_token做标记)最长的一个长度 和 填充后的输出序列张量, 和 填充后的标记 mask
def outputVar(l, voc):indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]max_target_len = max([len(indexes) for indexes in indexes_batch])padList = zeroPadding(indexes_batch)padVar = torch.LongTensor(padList)mask = binaryMatrix(padList)#torch.ByteTensor构建一个Byte类型的张量mask = torch.ByteTensor(mask)return padVar, mask, max_target_len# 返回给定batch对的所有项目
def batch2TrainData(voc, pair_batch):pair_batch.sort(key=lambda x: len(x[0].split(" ")), reverse=True)input_batch, output_batch = [], []#将语句对分开for pair in pair_batch:print(pair)input_batch.append(pair[0])output_batch.append(pair[1])# 返回填充前(加入结束index EOS_token做标记)的长度 和 填充后的输入序列张量inp, lengths = inputVar(input_batch, voc)# 返回填充前(加入结束index EOS_token做标记)最长的一个长度 和 填充后的输出序列张量, 和 填充后的标记 maskoutput, mask, max_target_len = outputVar(output_batch, voc)return inp, lengths, output, mask, max_target_len# 验证例子
print('***********************************************************************************')
small_batch_size = 5
#random模块中choice()可以从序列中获取一个随机元素,并返回一个(列表,元组或字符串中的)随机项
#batches是随机从所有语句对中国选取的5个语句对
batches = batch2TrainData(voc, [random.choice(pairs) for _ in range(small_batch_size)])
input_variable, lengths, target_variable, mask, max_target_len = batchesprint("input_variable:", input_variable)
print("lengths:", lengths)
print("target_variable:", target_variable)
print("mask:", mask)
print("max_target_len:", max_target_len)
#*******************************3.为模型准备数据 end *******************************以下代码期间的一些测试,有的时候如果自己不太清楚到底输入了什么输出了什么,就直接打印出来看看,是一个不错的方式:
import itertools#delimiter:分隔符
# import codecs
#
# delimiter = '\t'
# print('delimiter:',delimiter)
# # codecs.decode()方法的使用参考https://zhuanlan.zhihu.com/p/377436438
# delimiter = str(codecs.decode(delimiter, "unicode_escape"))
# print('delimiter:',delimiter)#测试没见过的语法:
'''
lines=['abc','de','f']
def back_for_test():result=[line for line in lines]return result;print(back_for_test())
'''#indexesFromSentence测试
# print([3,3,3]+[2])
#输出[3,3,3,2]#zeroPadding测试PAD_token=0
def zeroPadding(l, fillvalue=PAD_token):#参数前加一个星号,将传递进来的参数放在同一个元组中,该参数的返回值是一个元组# (在本案例中即把indexesFromSentence返回的列表转化成元组)# itertools.zip_longest作用参考https://blog.csdn.net/yiweiwei516/article/details/118182889#print(itertools.zip_longest(*l, fillvalue=fillvalue))return list(itertools.zip_longest(*l, fillvalue=fillvalue))print(zeroPadding((['abc','kevin','kobe'])))#也相当于做了转置
'''
本来传入的矩阵是['abc','kevin','kobe'],可以看作如下
[a b ck e v i nk o b e
]
输出是[('a', 'k', 'k'), ('b', 'e', 'o'), ('c', 'v', 'b'), (0, 'i', 'e'), (0, 'n', 0)],可以看作如下
[a k kb e oc v b0 i e0 n 0
]
相当于做了转置还填充了PAD_token
'''