目录
- 一、什么是ChatGPT?
- 二、ChatGPT的技术背景
- 三、ChatGPT的主要特点
- 四、ChatGPT的工作原理
- 五、ChatGPT为何成功?
一、什么是ChatGPT?
ChatGPT本质是一个对话模型,它可以回答日常问题、进行多轮闲聊,也可以承认错误回复、挑战不正确的问题,甚至会拒绝不适当的请求。
二、ChatGPT的技术背景
ChatGPT目前未释出论文文献,仅释出了介绍博文和试用API。从博文中提供的技术点和示意图来看,它与今年初公布的InstructGPT 核心思想一致。其关键能力来自三个方面:强大的基座大模型能力(InstructGPT),高质量的真实数据(干净且丰富),强化学习(PPO算法)。
三、ChatGPT的主要特点
让用户印象最深刻的是它有强大的语言理解和生成系统。其对话能力、文本生成能力、对不同语言表述的理解均很出色。它以对话为载体,可以回答多种多样的日常问题,对于多轮对话历史的记忆能力和篇幅增强。其次,与GPT3等大模型相比,ChatGPT回答更全面,可以多角度全方位进行回答和阐述,相较以往的大模型,知识被“挖掘”得更充分。它能降低了人类学习成本和节省时间成本,可以满足人类大部分日常需求,比如快速为人类改写确定目标的文字、大篇幅续写和生成小说、快速定位代码的bug等。
值得一提的事,它具有安全机制和去除偏见能力。下图这类问题在以前的大模型中时常出现,然而ChatGPT在这两点上增加了过滤处理机制。针对不适当的提问和请求,它可以做出拒绝和“圆滑”的回复。例如对于违法行为的提问:

对于未知事物的“拒绝”:
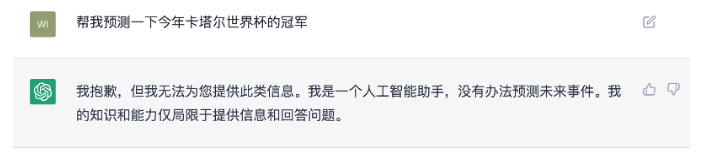
当然ChatGPT并非十全十美,其缺点也比较明显。首先,其简单的逻辑问题错误依旧明显存在,发挥不够稳定(但总体比GPT3好很多)。特别在有对话历史时,它容易因被用户误导而动摇。

其次,ChatGPT有时会给出看似合理、但并不正确或甚至荒谬的答案。部分答案需要自行甄别才能判断正误,特别当本身用户处于未知状态来咨询模型时,更加无法判断真伪。ChatGPT使得生产者可以用较低成本增加错误信息,而这一固有缺点已经造成了一些实际影响。编程问答网站 StackOverflow 宣布暂时禁止用户发布来自 ChatGPT 生成的内容,网站 mods 表示:看似合理但实际上错误的回复数量太多,已经超过了网站的承受能力。
此外,它抵抗不安全的prompt能力较差,还存在过分猜测用户意图的问题。这主要体现在当用户提问意图不明确时,ChatGPT会猜测用户意图,理想情况应为要求用户澄清;当用户意图不明确时,很大概率给出不合适的回复。大批量的用户反馈,ChatGPT部分回复废话较多、句式固定。它通常过度使用一些常见的短语和句式。这与构造训练数据时,用户倾向于选择更长的回复有关。
四、ChatGPT的工作原理
ChatGPT训练过程很清晰,主要分为三个步骤,示意如图所示:
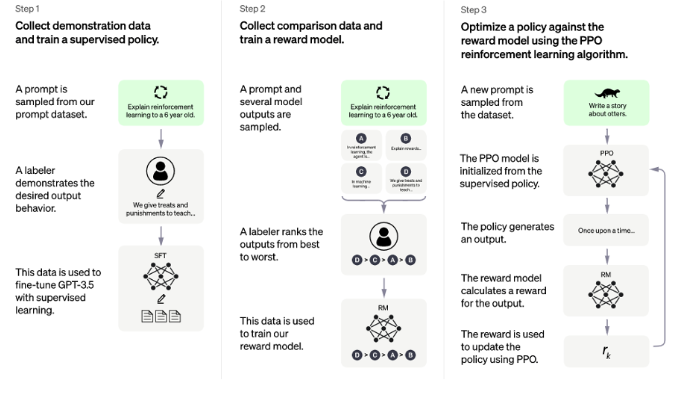
第一步,使用有监督学习方式,基于GPT3.5微调训练一个初始模型,训练数据约为2w~3w量级(此处为推测量级,我们根据兄弟模型InstructGPT的训练数据量级估算)。由标注师分别扮演用户和聊天机器人,产生人工精标的多轮对话数据。值得注意的是,在人类扮演聊天机器人时,会得到机器生成的一些建议来帮助人类撰写自己的回复,以此提高撰写标注效率。
以上精标的训练数据虽然数据量不大,但质量和多样性非常高,且来自真实世界数据,这是很关键的一点。
第二步,收集相同上文下,根据回复质量进行排序的数据:即随机抽取一大批Prompt,使用第一阶段微调模型,产生多个不同回答: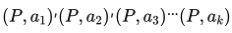 之后标注人员对k个结果排序,形成训练组数据对。之后使用pairwise loss来训练奖励模型,可以预测出标注者更喜欢哪个输出。"从比较中"学习可以给出相对精确的奖励值。之后使用pairwise loss来训练奖励模型,可以预测出标注者更喜欢哪个输出。"从比较中"学习可以给出相对精确的奖励值。
之后标注人员对k个结果排序,形成训练组数据对。之后使用pairwise loss来训练奖励模型,可以预测出标注者更喜欢哪个输出。"从比较中"学习可以给出相对精确的奖励值。之后使用pairwise loss来训练奖励模型,可以预测出标注者更喜欢哪个输出。"从比较中"学习可以给出相对精确的奖励值。
这一步使得ChatGPT从命令驱动转向了意图驱动。关于这一点,李宏毅老师的原话称,“它会不断引导GPT说人类要他说的”。另外,训练数据不需过多,维持在万量级即可。因为它不需要穷尽所有的问题,只要告诉模型人类的喜好,强化模型意图驱动的能力就行。
第三步,使用PPO强化学习策略来微调第一阶段的模型。这里的核心思想是随机抽取新的Prompt,用第二阶段的Reward Model给产生的回答打分。这个分数即回答的整体reward,进而将此reward回传,由此产生的策略梯度可以更新PPO模型参数。整个过程迭代数次直到模型收敛。
强化学习算法可以简单理解为通过调整模型参数,使模型得到最大的奖励(reward),最大奖励意味着此时的回复最符合人工的选择取向。而对于PPO,我们知道它是2017年OpenAI提出的一种新型的强化学习策略优化的算法即可。它提出了新的目标函数,可以在多个训练步骤实现小批量的更新,其实现简单、易于理解、性能稳定、能同时处理离散/连续动作空间问题、利于大规模训练。
五、ChatGPT为何成功?
为何三段式的训练方法就可以让ChatGPT如此强大?其实,以上的训练过程蕴含了上文我们提到的关键点,而这些关键点正是ChatGPT成功的原因:
- 强大的基座模型能力(InstructGPT)
- 大参数语言模型(GPT3.5)
- 高质量的真实数据(精标的多轮对话数据和比较排序数据)
- 性能稳定的强化学习算法(PPO算法)