文章目录
- 一文详解 ChatGPT
- ChatGPT背后的技术
- 基于 Transformer 的预训练语言模型
- 提示学习与指令精调
- 思维链(Chain of Thought,COT)
- 基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF)
- ChatGPT 相关数据集
- 预训练数据集
- 人工标注数据规范及相关数据集
- 如何看待ChatGPT的未来发展?
- OpenAI 指出 ChatGPT 的现存
- ChatGPT 的优势
- ChatGPT 的劣势
- ChatGPT 应用前景
一文详解 ChatGPT
从2022年11月30日ChatGPT出现至今,热议不断,ChatGPT在全世界点燃了新一轮AI革命,海内外关注度陡增,越来越多“关联”企业跟风而上,科技“狠话”、科技“狠活”真真假假,让人一时分不清到底谁是谁非。
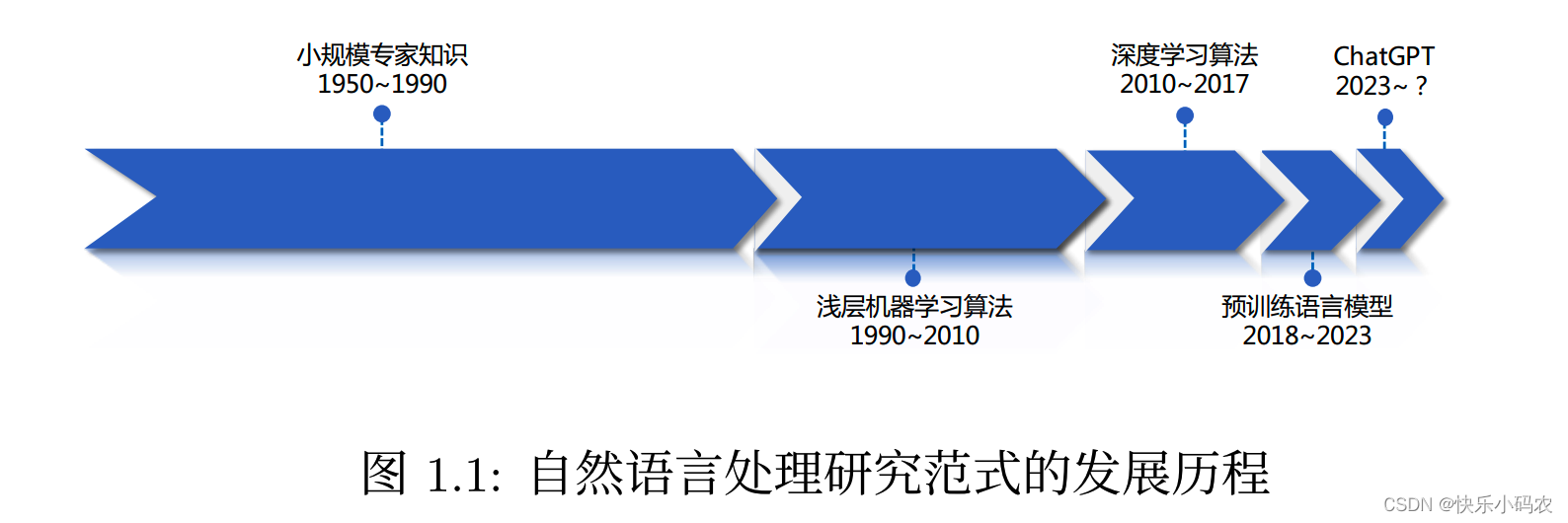
ChatGPT 能表现出惊艳的语言理解、生成、知识推理能力,这得益于自然语言处理(NLP)的发展。而从NLP技术发展看,如下图1.1,可以发现:每一个技术阶段的发展时间,大概是上一个阶段的一半。
小规模专家知识发展了 40 年,浅层机器学习是 20 年,之后深度学习大概 10 年,预训练语言模型发展的时间是 5 年,那么以 ChatGPT 为代表的技术能持续多久呢?如果大胆预测,可能是 2 到 3 年,也就是到 2025 年大概又要更新换代了。
ChatGPT背后的技术
ChatGPT 核心技术主要包括其具有良好的自然语言生成能力的大模型 GPT-3.5 以及训练这一模型的钥匙——基于人工反馈的强化学习(RLHF)。
ChatGPT 的卓越表现得益于其背后多项核心算法的支持和配合,包括作为其实现基础的 Transformer 模型、激发出其所蕴含知识的 Prompt/Instruction Tuning 算法、其涌现出的思维链(COT)能力、以及确保其与人类意图对齐的基于人类反馈的强化学习(RLHF)算法。
基于 Transformer 的预训练语言模型
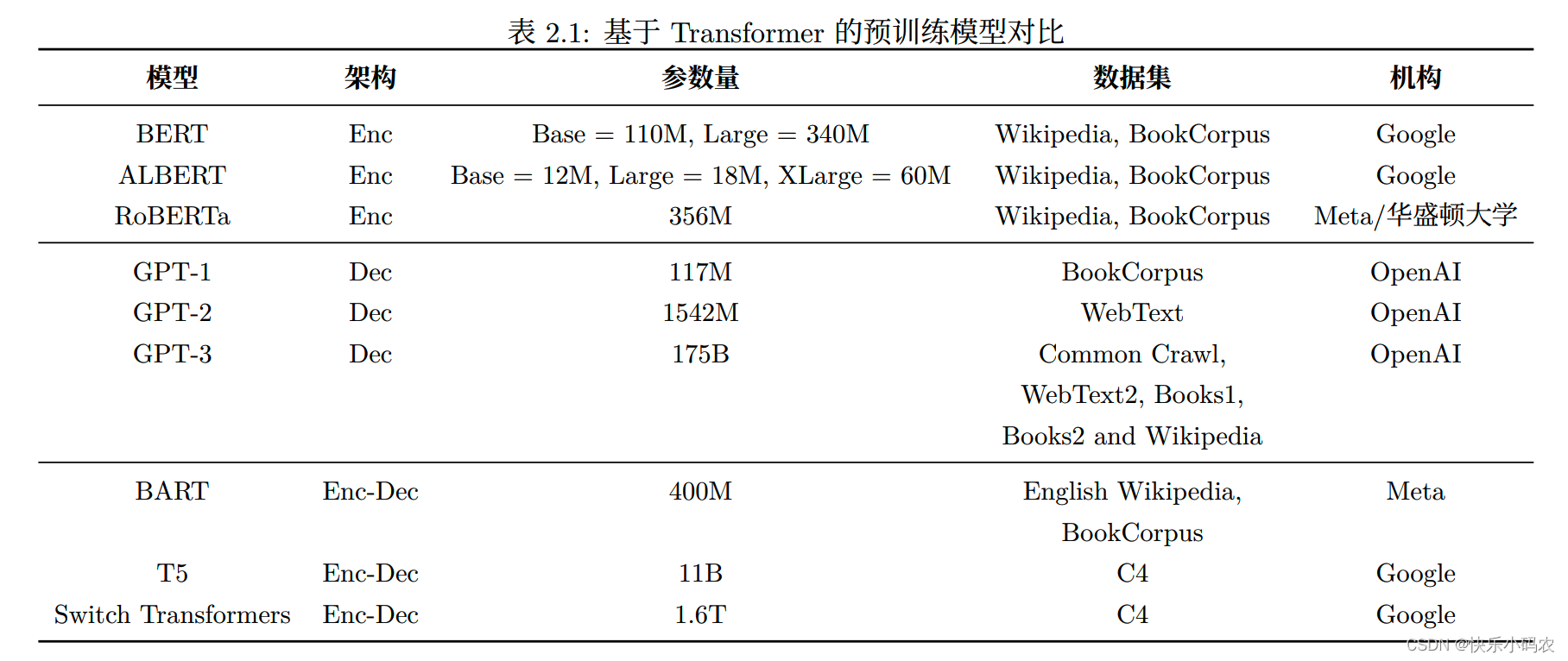
ChatGPT 强大的基础模型采用 Transformer 架构, Transformer 是一种基于自注意力机制的深度神经网络模型,可以高效并行地处理序列数据。原始的Transformer 模型包含两个关键组件:编码器和解码器。在原始 Transformer 模型基础上,相继衍生出了三类预训练语言模型:编码预训练语言模型、解码预训练语言模型和编解码预训练语言模型。
| 编码预训练语言模型(Encoder-only Pre-trained Models) | 解码预训练语言模型(Decoder-only Pre-trained Models) | 基于编解码架构的预训练语言模型(Encoder-decoder Pretrained Models) | |
|---|---|---|---|
| 模型特点 | 这类模型在预训练过程中只利用原始 Transformer 模型中的编码器。相应的预训练任务通常选用掩码语言建模任务(Masked Language Modeling),即掩码住(用特殊字符 [MASK] 替换)输入句子中一定比例的单词后,要求模型根据上下文信息去预测被遮掩的单词。 | GPT (Generative Pre-trained Transformer) 是由 OpenAI 提出的只有解码器的预训练模型。相较于之前的模型,不再需要对于每个任务采取不同的模型架构,而是用一个取得了优异泛化能力的模型,去针对性地对下游任务进行微调。 | 针对单一编码器或解码器出现的问题,一些模型采用序列到序列的架构来融合两种结构,即基于编解码架构的预训练语言模型,使用编码器提取出输入中有用的表示,来辅助并约束解码器的生成。 |
| 代表模型 | BERT,ALBERT,RoBERTa | GPT-1,GPT-2 ,GPT-3 | BART,T5,Switch Transformers, |
| 不足 | 基于编码器的架构得益于双向编码的全局可见性,在语言理解的相关任务上性能卓越(在NLU表现更好),但是因为无法进行可变长度的生成,不能应用于生成任务。 | 基于解码器的架构采用单向自回归模式,可以完成生成任务(在NLG表现更好),但是信息只能从左到右单向流动,模型只知“上文”而不知“下文”,缺乏双向交互。 | 与单个编码器/解码器相比,编码器-解码器引入了更多的参数。虽可通过参数共享来缓解,但其参数效率仍然值得怀疑。编码器-解码器架构通常在自然语言理解(NLU)方面表现不佳。 |
提示学习与指令精调
提示学习(Prompt Learning)是一个NLP界最近兴起的学科,能够通过在输入中添加一个提示词(Prompt),使得预训练模型的性能大幅提高。Prompt Tuning和Fine Tuning都是对预训练模型进行微调的方法。
提出Prompt的动机是,语言模型(Language Models)越来越大,Fine-tune的成本也越来越高。Fine-tuning的本质是改变预训练模型的weights。LM有基于大量训练数据的天然的迁移学习能力,但要在新域上获得较好的性能,使用Fine-tuning,就要求重新多次训练预训练模型,导致吃内存。
提示学习(Prompt Learning)是指对输入文本信息按照特定模板进行处理,把任务重构成一个更能充分利用预训练语言模型处理的形式。
比如,假如我要判断“我喜欢这个电影" 这句话的情感(“正面" 或者 “负面”),原有的任务形式是把他看成一个分类问题
输入:我喜欢这个电影
输出:“正面" 或者 “负面”
而用Prompt Learning去解决的话,任务可以变成“完形填空",
输入:我喜欢这个电影,整体上来看,这是一个 __ 的电影
输出:“有趣的" 或者 “无聊的”
总结一下,使用Prompt的根本方法是:
自然语言指令(task description) + 任务demo(example) + 带"__"的任务。
Prompt Tuning的本质是改变任务格式,从而迎合大模型的性能。换句话说,Prompt Tuning的前提是预训练模型的性能已经非常好了,我们只需要在推断的时候进行任务格式转换即可获得很好的性能。下面这张图很好地表达了这个本质:
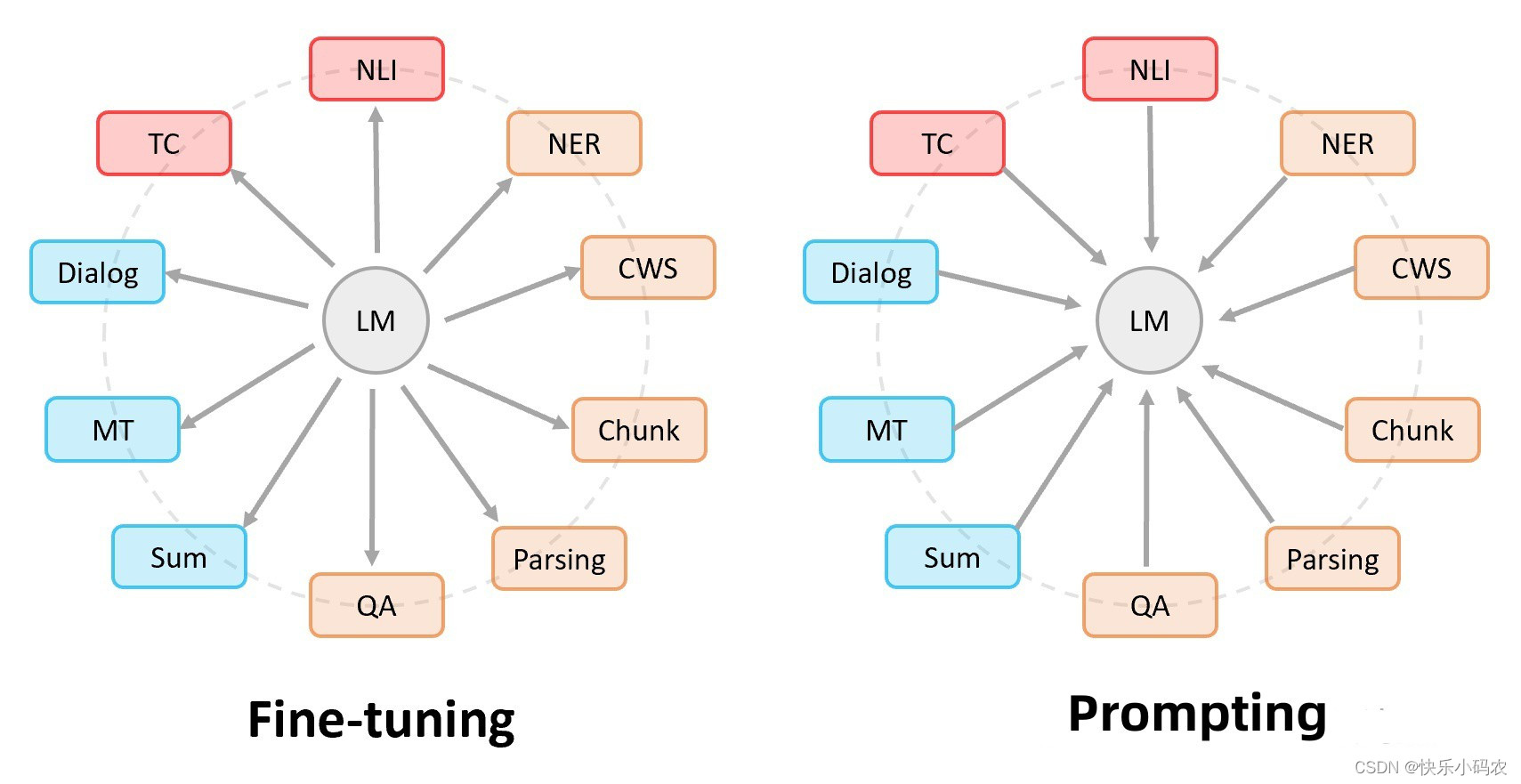
一句话总结,Fine-tuning,是调整语言模型,让任务和语言模型靠的更近;Prompt Tuning,是调整任务格式,让任务和语言模型靠的更近。
相较于提示学习(Prompt Learning), 指令精调(Instruction Tuning) 可以说是提示学习的加强版。
例如,给你2个任务:
1.我带女朋友去了一家餐厅,她吃的很开心,这家餐厅太 __ 了!
2.判断这句话的情感:我带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差
在这两个任务中,Prompt就是第一种模式,Instruction就是第二种。
两种学习方法的本质目标均是希望通过编辑输入来深挖模型自身所蕴含的潜在知识,进而更好的完成下游任务。
Instruction Tuning 和Prompt Learning的本质目标是一样的,通过编辑输入来深挖模型自身所蕴含的潜在知识,进而更好的完成下游任务。而他们的不同点就在于,Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做language model任务,它的模版是这样的:

而Instruction Tuning则是激发语言模型的理解能力,通过给出更明显的指令/指示,让模型去理解并做出正确的action。比如NLI/分类任务:
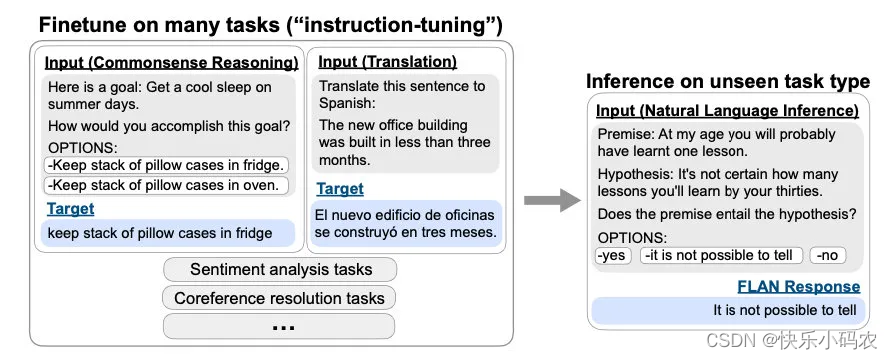
研究表明,当“指令”任务的种类达到一定量级后,大模型甚至可以在没有见过的零样本(Zero-shot)任务上有较好的处理能力。因此,指令学习可以帮助语言模型训练更深层次的语言理解能力,以及处理各种不同任务的零样本学习能力。 OpenAI提出的InstructGPT 模型使用的就是指令学习的思想, ChatGPT 沿袭了InstructGPT 的方法。
思维链(Chain of Thought,COT)
人类在解决数学应用题这类复杂推理任务的过程中,通常会将问题分解为多个中间步骤,并逐步求解,进而给出最终的答案。受此启发,谷歌研究人员 Jason Wei(现 OpenAI 员工)等提出了思维链(Chain of Thought,COT),通过在小样本提示学习的示例中插入一系列中间推理步骤,有效提升了大规模语言模型的推理能力,图 2.2展示模型通过产生思维链来正确求解数学应用题。

相较于一般的小样本提示学习,思维链提示学习有几个吸引人的性质:
- 在思维链的加持下,模型可以将需要进行多步推理的问题分解为一系列的中间步骤,这可以将额外的计算资源分配到需要推理的问题上。
- 思维链为模型的推理行为提供了一个可解释的窗口,使通过调试推理路径来探测黑盒语言模型成为了可能。
- 思维链推理应用广泛,不仅可以用于数学应用题求解、常识推理和符号操作等任务,而且可能适用任何需要通过语言解决的问题。
- 思维链使用方式非常简单,可以非常容易地融入语境学习(in-context learning),从而诱导大语言模型展现出推理能力。
基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF)
RLHF 这一概念最早是在 2008 年 TAMER:Training an Agent Manually via Evaluative Reinforcement 一文中被提及的。
RLHF 是 ChatGPT/InstrcutGPT 实现与人类意图对齐,即按照人类指令尽可能生成无负面影响结果的重要技术。该算法在强化学习框架下实现,大体可分为以下两个阶段:奖励模型训练,生成策略优化。
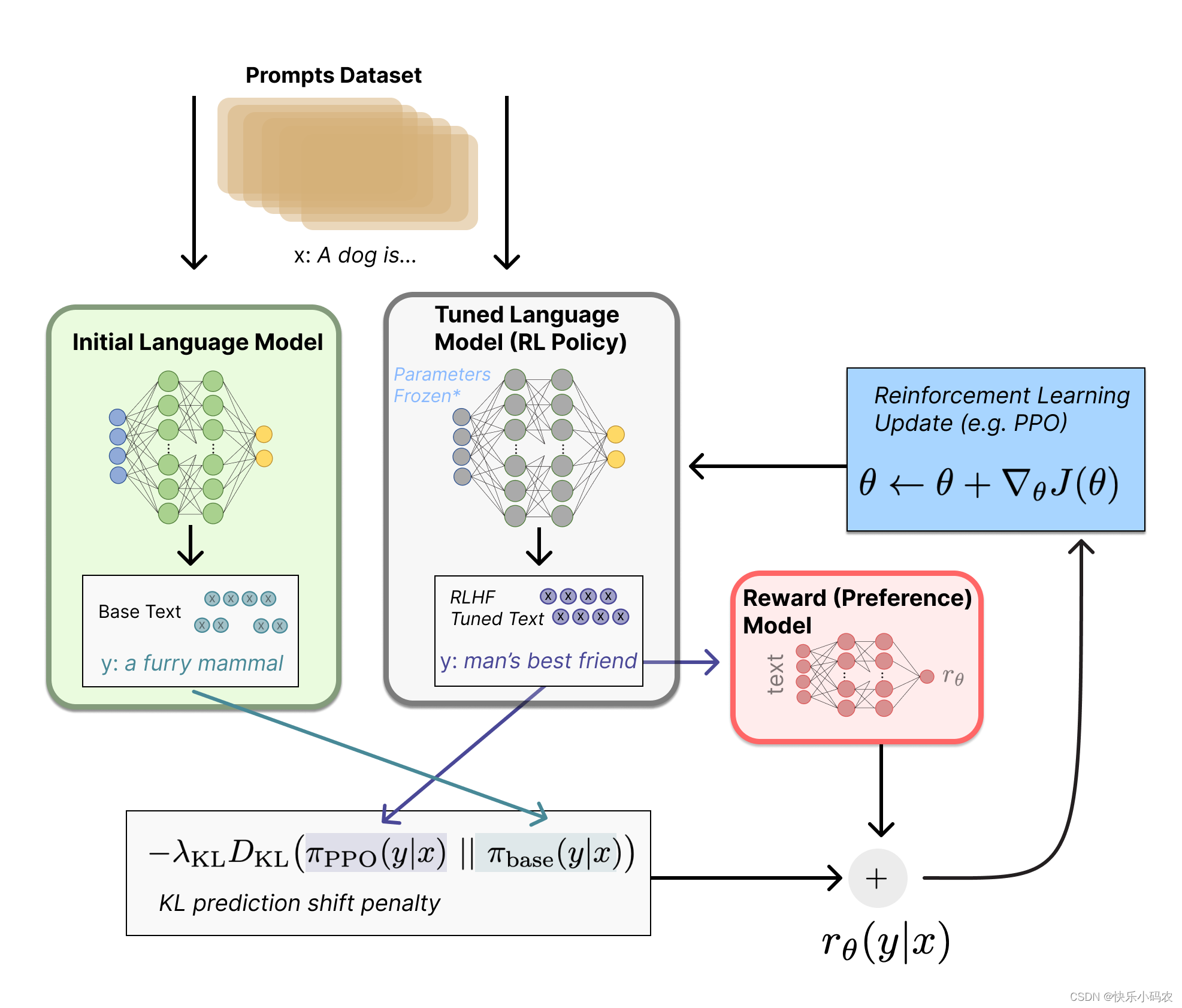
根据OpenAI的思路,RLHF分为三步:1.预训练一个语言模型LM;2.收集数据并训练一个奖励模型;3.利用强化学习微调语言模型LM。

简单来说,这三步:
- 花钱招人给问题(prompt)写回答(demonstration),然后finetune一个GPT3。这一步可以多训几个版本,第二步会用到。
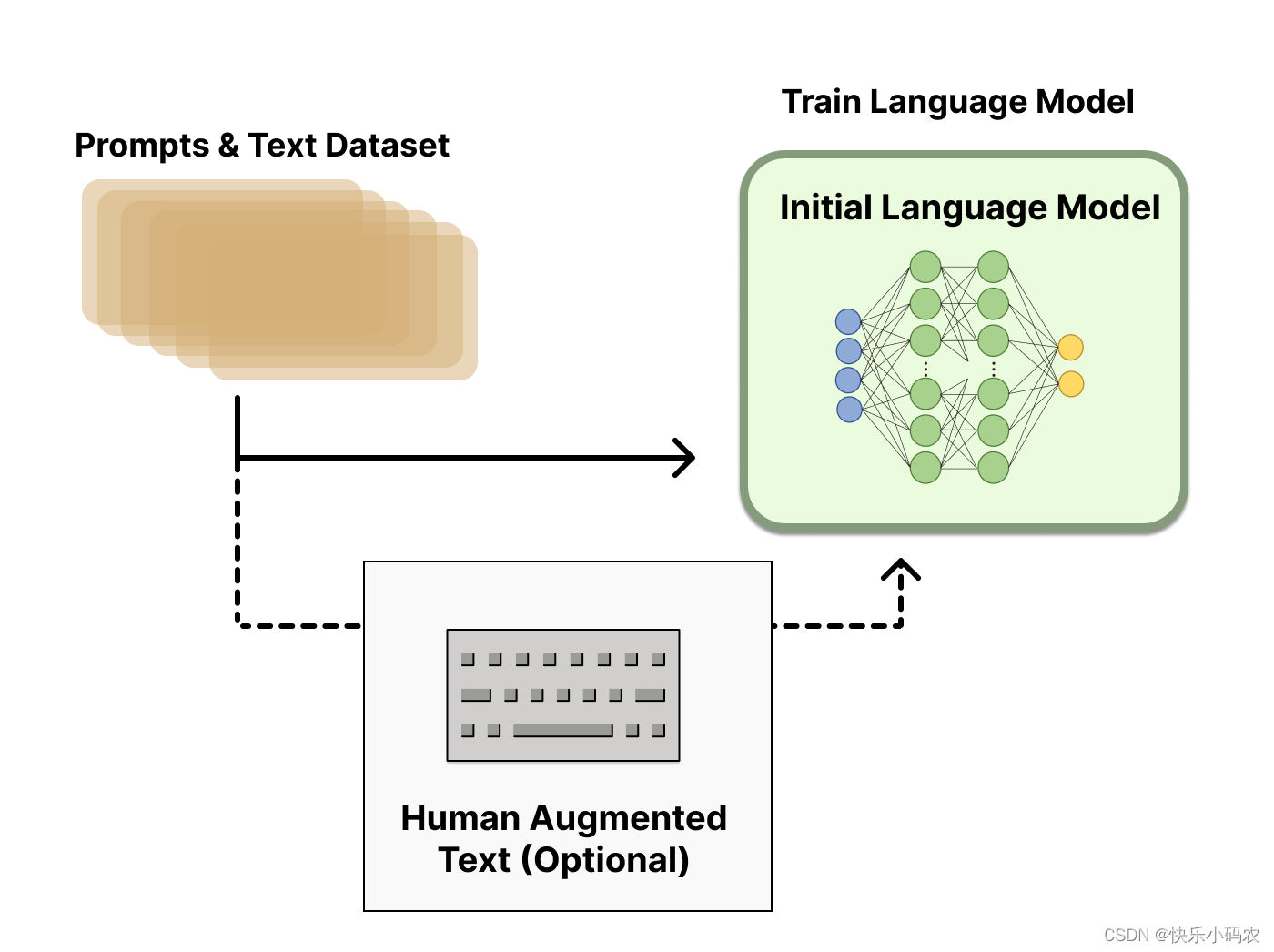
图注:第一步,预训练一个语言模型LM
-
用多个模型(可以是初始模型、finetune模型和人工等等)给出问题的多个回答,然后人工给这些问答对按一些标准(可读性、无害、正确性blabla)进行排序,训练一个奖励模型/偏好模型来打分(reward model)。
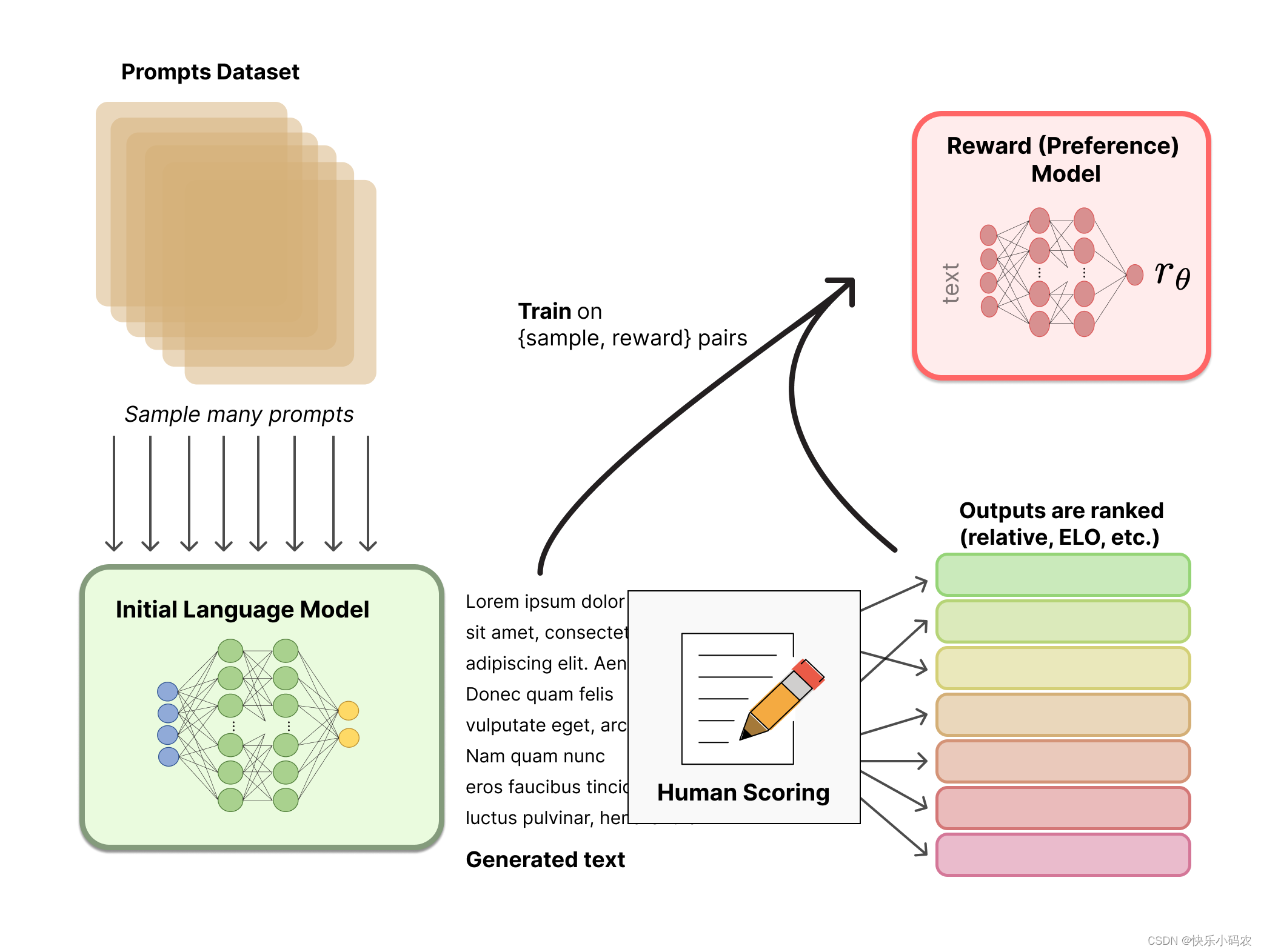
-
用强化学习训练上面那个finetune后的GPT3模型。用强化学习做LM训练的一种思路是用Policy Gradient做,这一块OpenAI用的是他们在17年提出的PPO算法,即Proximal Policy Optimization。
ChatGPT 相关数据集
算法、数据、算力是大模型时代的三方面重要因素。根据 OpenAI 前期论文和博客介绍, ChatGPT 中数据集的规模和构建质量均高于以往的人工标注数据集。
预训练数据集
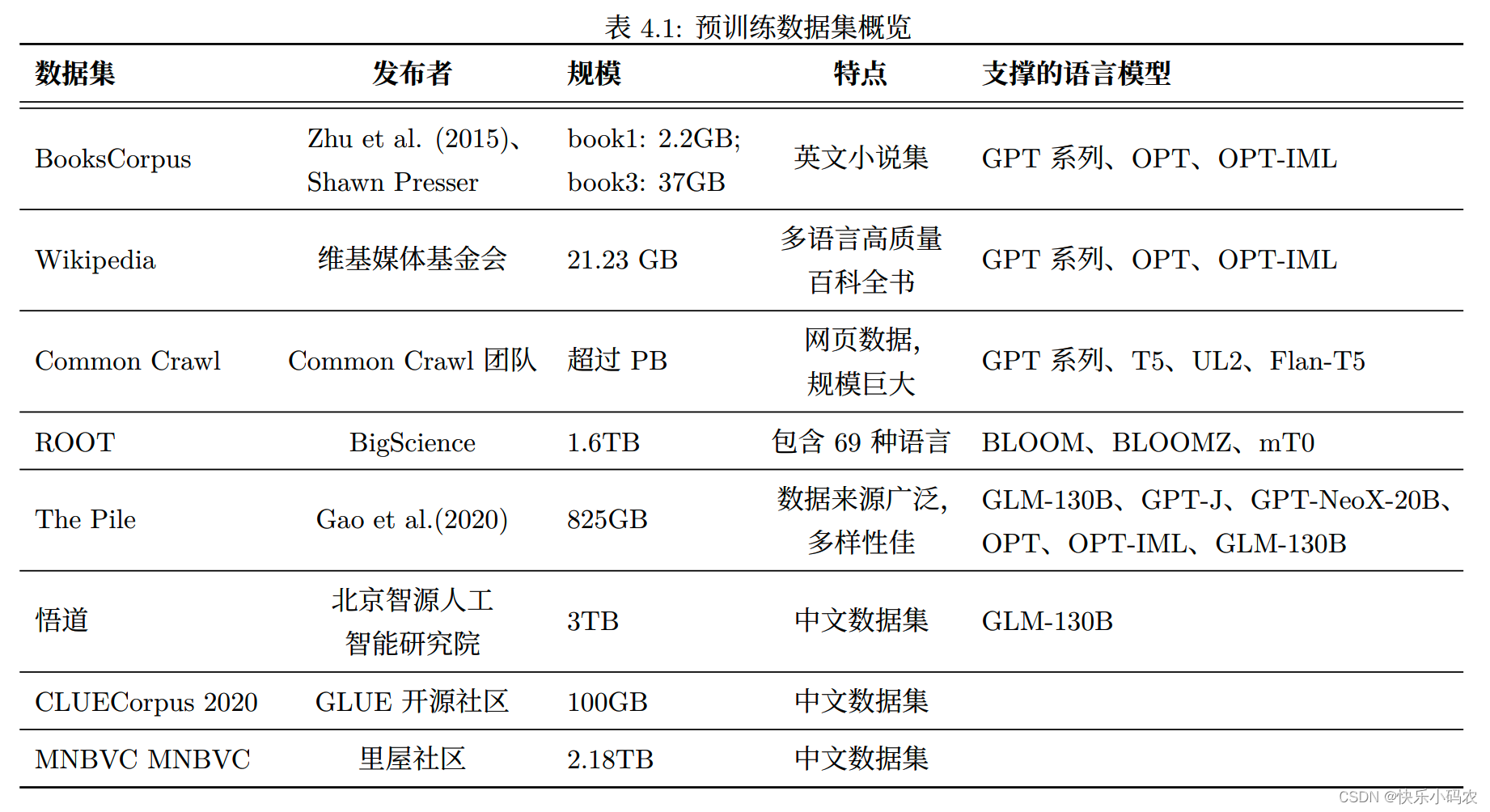
ChatGPT 之所以展现出非常优秀的文本理解能力,其中重要的因素是其拥有一个强大的基座模型。为了获得这样基座模型,需要在大规模无标注文本数据上进行预训练,目前被广泛使用的预训练数据集主要包括 BooksCorpus、 Wikipedia、 Common Crawl、 ROOT 等,表 4.1概览了目前常用的预训练数据集,具体情况如下所示:
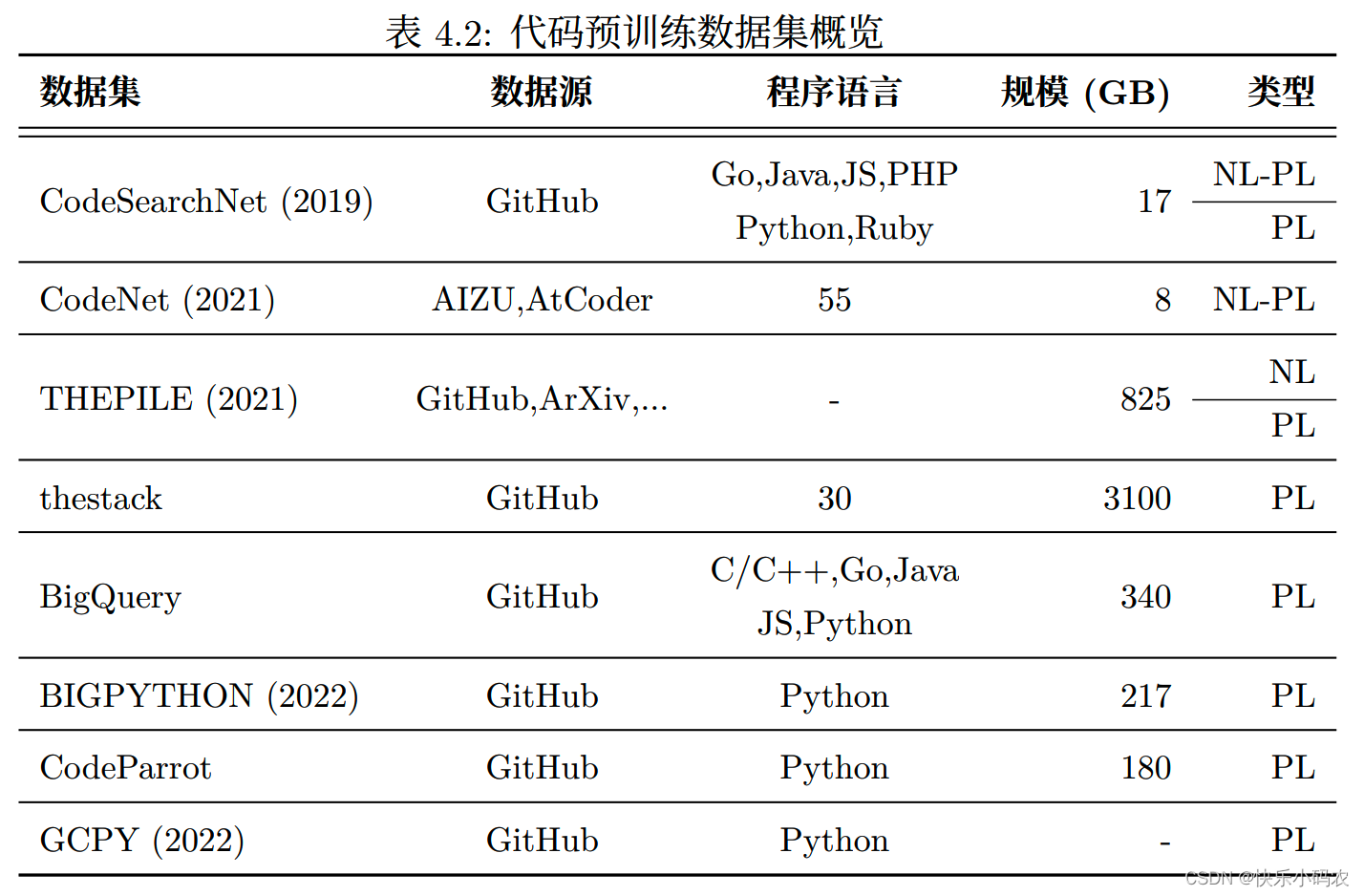
在对大模型做大规模评价之后,发现训练数据中含有代码的模型具有很强的语言推理能力。在对 OpenAI 的各个模型测试中,也发现代码预训练与 COT 表现息息相关。因此,在预训练时使用代码数据成为越来越多研究者的共识。代码预训练数据可以根据程序语言和自然语言是否同时出现分成单语数据和对齐数据。表格 4.2展示了一些常见数据集的基本信息。
人工标注数据规范及相关数据集
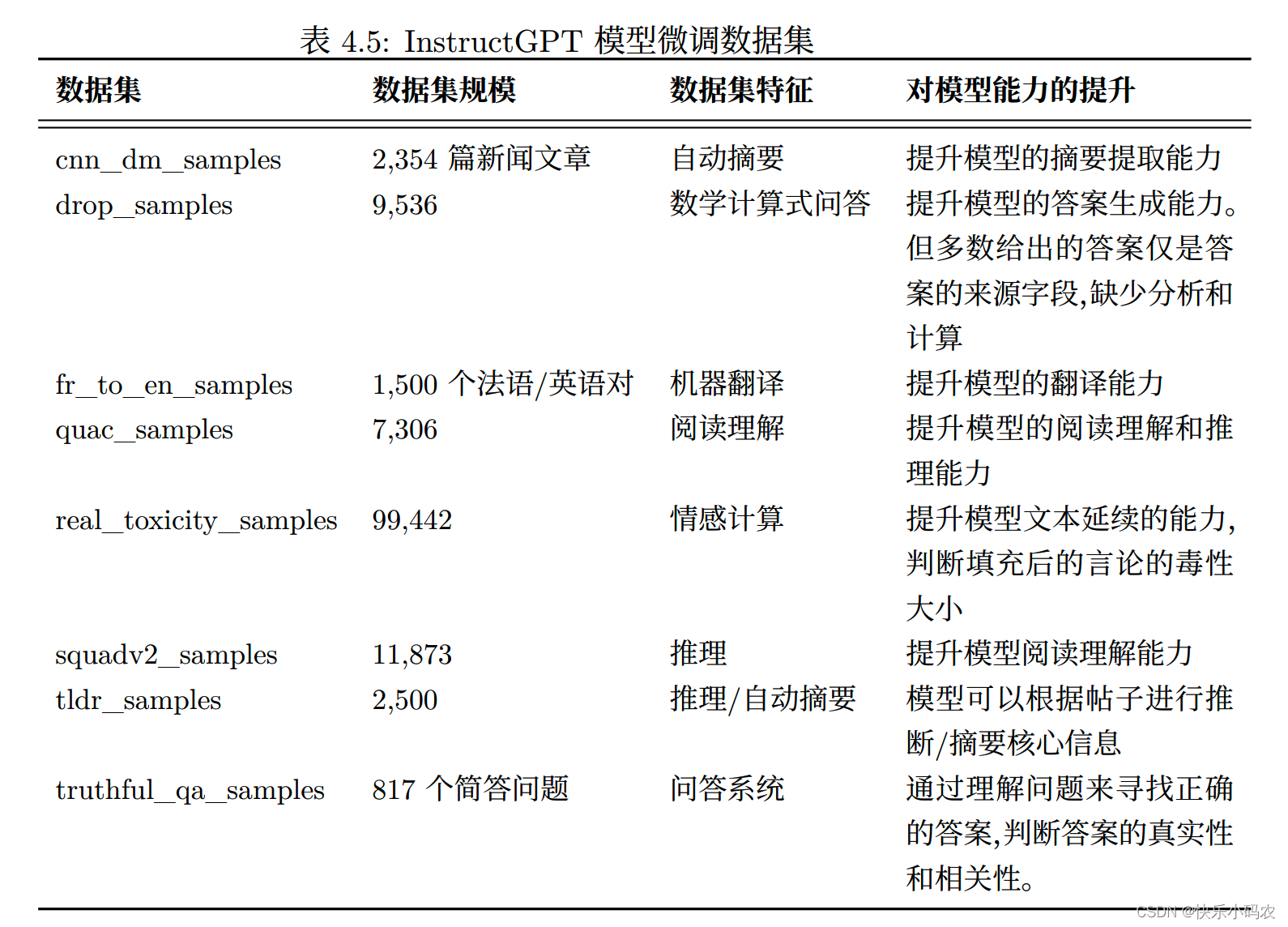
指令微调数据集通常建立在自然语言处理经典数据集基础上。 Google 研究院及 Hugging Face 等机构提出的指令微调训练任务采用的自然语言处理数据集如表4.4所示。表4.5为 InstructGPT 模型训练的部分测试集以及对模型能力提升的分析。
如何看待ChatGPT的未来发展?
虽然 ChatGPT 目前已经取得了非常喜人的成果,但是未来仍然有诸多可以研究的方向。
OpenAI 指出 ChatGPT 的现存
| 序号 | ChatGPT现存问题 | 产生原因 |
|---|---|---|
| 1 | ChatGPT 有时候会生成一些似是而非、毫无意义的答案。 | (1)强化学习训练过程中没有明确的正确答案;(2)训练过程中一些谨慎的训练策略导致模型无法产生本应产生的正确回复;(3)监督学习训练过程中错误的引导导致模型更倾向于生成标注人员所知道的内容而不是模型真实知道的。 |
| 2 | ChatGPT 对于输入措辞比较敏感,例如:给定一个特定的问题,模型声称不知道答案,但只要稍微改变措辞就可以生成正确答案。 | |
| 3 | ChatGPT 生成的回复通常过于冗长,并且存在过度使用某些短语的问题,例如:重申是由 OpenAI 训练的语言模型。 | 这样的问题主要来自于训练数据的偏差和过拟合问题。 |
| 4 | 虽然 OpenAI 已经努力让模型拒绝不恰当和有害的请求,但是仍然无法避免对有害请求作出回复或对问题表现出偏见。 | |
| 5 | ChatGPT 虽然很强大,但是其模型过于庞大使用成本过高,如何对模型进行瘦身。 | 目前主流的模型压缩方法有量化、剪枝、蒸馏和稀疏化等。 |
ChatGPT 的优势
相较于不同产品和范式,ChatGPT的优势有哪些?
| 优势比较 | ChatGPT VS普通聊天机器人 | ChatGPT VS 其它大规模语言模型 | ChatGPT VS微调小模型 |
|---|---|---|---|
| ChatGPT特点 | ChatGPT 的回答更准确,答案更流畅,能进行更细致的推理,能完成更多的任务。 | ChatGPT使用了更多的多轮对话数据进行指令微调,这使其拥有了建模对话历史的能力,能持续和用户交互。 | ChatGPT通过大量指令激发的泛化能力在零样本和少样本场景下具有显著优势,在未见过的任务上也可以有所表现。 |
| ChatGPT优势 | (1)强大的底座能力;(2)惊艳的思维链推理能力;(3)实用的零样本能力。 | (1)在Instruction Tuning阶段通过基于人类反馈的强化学习调整模型的输出偏好,使其能输出更符合人类预期的结果。(2)RLHF利用真实的用户反馈不断进行 AI 正循环,持续增强自身和人类的这种对齐能力,输出更安全的回复。 | (1)大规模语言模型的天然优势使 ChatGPT 在创作型任务上的表现尤为突出。 |
ChatGPT 的劣势
| 比较方面 | ChatGPT的劣势 |
|---|---|
| 大规模语言模型 | (1)可信性无法保证;(2)时效性差;(3)成本高昂;(4)在特定的专业领域上表现欠佳;(5)语言模型每次的生成结果是 beam search 或者采样的产物,每次都会有细微的不同。ChatGPT 对输入敏感,回答不够稳定。 |
| 数据 | (1)ChatGPT 的基础大规模语言模型是基于现实世界的语言数据预训练而成,因为数据的偏见性,很可能生成有害内容。(2)ChatGPT 为 OpenAI 部署,用户数据都为 OpenAI 所掌握,长期大规模使用可能存在数据泄漏风险。 |
| 标注策略 | ChatGPT 通过基于人类反馈的强化学习使模型的生成结果更符合人类预期,然而这也导致了模型的行为和偏好一定程度上反映的是标注人员的偏好,在标注人员分布不均的情况下,可能会引入新的偏见问题。 |
| 使用场景 | 在目前微调小模型已经达到较好效果的前提下,ChatGPT的训练和部署更困难,有些任务场景下不太适用,性价比稍低。 |
ChatGPT 应用前景
ChatGPT 作为掀起新一轮 AIGC 热潮的新引擎,无论在人工智能行业还是其他行业都带来了广泛的讨论和影响。
| 领域/行业 | ChatGPT应用 | 影响公司 |
|---|---|---|
| 人工智能行业 | 1.代码开发;2.ChatGPT 和具体任务相结合;3.ChatGPT 当作冷启动收集相关语料的工具。 | |
| 搜索引擎 | 搜索引擎 | 谷歌:Bard,微软:文心一言,微软:新Bing |
| 泛娱乐行业 | 游戏虚拟人,虚拟主播,虚拟数字人 | |
| 自媒体行业 | 内容创作 | Buzzfeed |
| 教育行业 | 作业,论文,考试 | |
| 日常办公 | 邮件,演讲稿,文案,报告 | 微软 |
| 其他专业领域 | 具体影响不大,无法对专业知识进行细致分析,生成的回答专业度不足且可信性难以保证 |
公众号回复「ChatGPT报告」获得90+页哈工大NLP内部《ChatGPT调研报告》。
参考:
https://new.qq.com/rain/a/20230311A06DWI00
https://huggingface.co/blog/rlhf
欢迎各位关注我的个人公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。