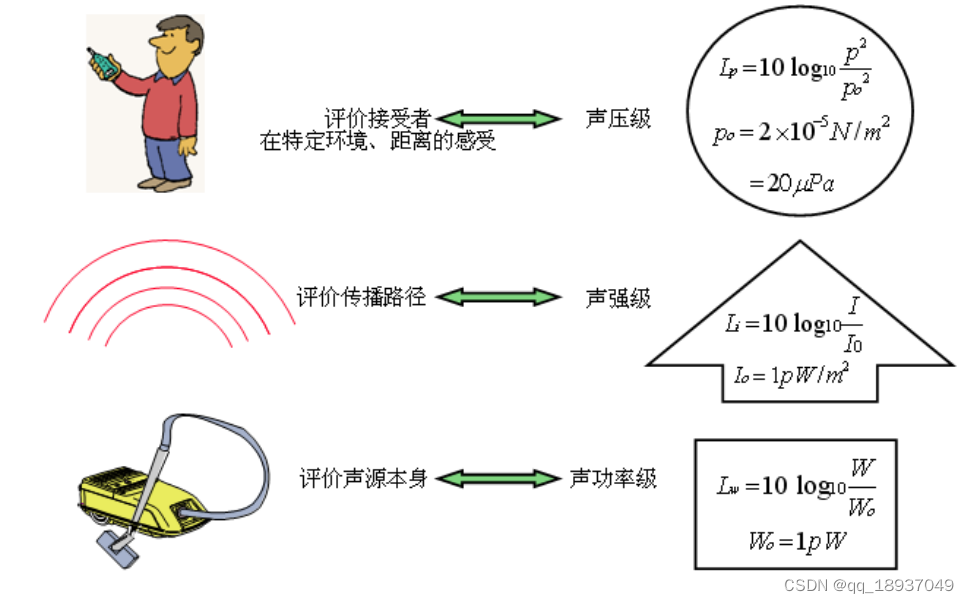
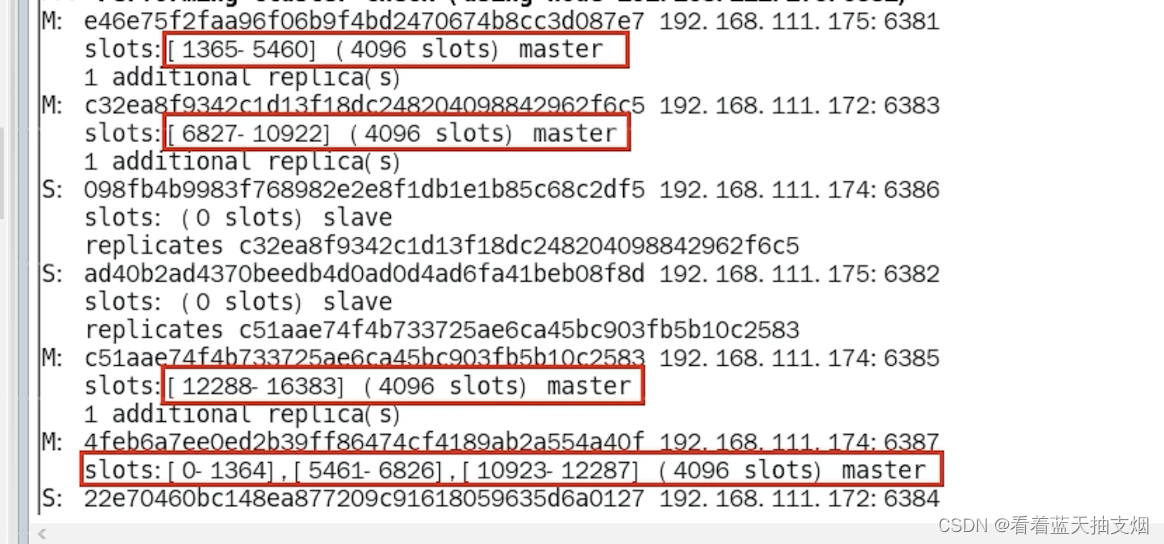
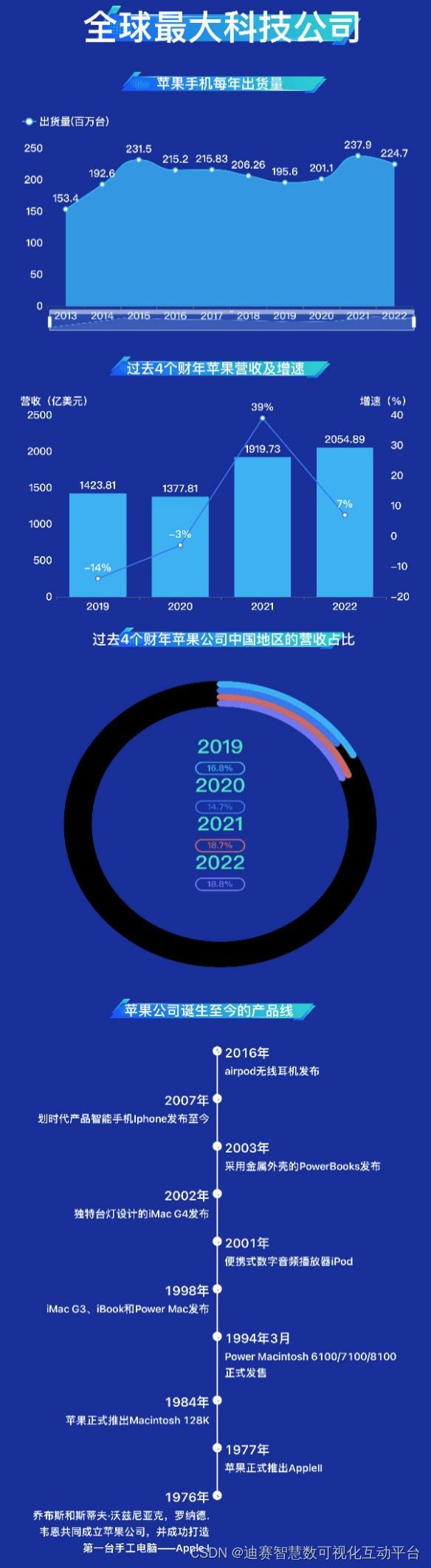
在PySpark中,没有您预期的shift函数,并且您在使用lag时的方向是正确的。但是这里有一个小技巧,当你必须在lag_1的基础上进行lag_2等等。
from pyspark.sql import functions as F
from pyspark.sql import Window as Wdf = df.withColumn('lag_0', F.col('num_orders'))
for lag in range(1, 8):df = (df.withColumn(f'lag_{lag}', F.lag(f'lag_{lag - 1}').over(W.partitionBy(F.lit(1)).orderBy('date'))))±—±---------±----±----±----±----±----±----±----±----+
|date|num_orders|lag_0|lag_1|lag_2|lag_3|lag_4|lag_5|lag_6|lag_7|
±—±---------±----±----±----±----±----±----±----±----+
| 1| 124| 124| null| null| null| null| null| null| null|
| 2| 85| 85| 124| null| null| null| null| null| null|
| 3| 71| 71| 85| 124| null| null| null| null| null|
| 4| 66| 66| 71| 85| 124| null| null| null| null|
| 5| 43| 43| 66| 71| 85| 124| null| null| null|
| 6| 6| 6| 43| 66| 71| 85| 124| null| null|
| 7| 12| 12| 6| 43| 66| 71| 85| 124| null|
±—±---------±----±----±----±----±----±----±----±----+