安装
su - root
https://repo.anaconda.com/archive/
Anaconda3-2021.05-Linux-x86_64.sh
sh ./Anaconda3-2021.05-Linux-x86_64.sh
yes
enter
exit()
exit()
重新登录
su - root
配置成功
(base) [root@node1 ~]# python
Python 3.8.8 (default, Apr 13 2021, 19:58:26)
[GCC 7.3.0] :: Anaconda, Inc. on linux
.condarc
su - root
vim ~/.condarc
channels:- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
show_channel_urls: true
pyspark
(base) [root@node1 ~]# pyspark
-bash: pyspark: command not found
(base) [root@node1 ~]# # pyspark
(base) [root@node1 ~]# conda create -n pyspark python=3.9
conda activate pyspark
conda deactivate
conda安装
(base) [root@node1 ~]# conda activate pyspark
(pyspark) [root@node1 ~]#
Spark安装
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/
ln -s /export/server/spark-3.2.0-bin-hadoop3.2 /export/server/sparklrwxrwxrwx 1 hadoop hadoop 23 May 24 22:50 spark -> spark-3.4.0-bin-hadoop3环境变量 /etc/profile
配置Spark由如下5个环境变量需要设置
- SPARK_HOME: 表示Spark安装路径在哪里
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
- JAVA_HOME: 告知Spark Java在哪里
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
- HADOOP_HOME: 告知Spark Hadoop安装在哪里
vim /etc/profile## export MAVEN_HOME=/export/server/maven
export HADOOP_HOME=/export/server/hadoop
export SPARK_HOME=/export/server/spark
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.9
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:/usr/local/python3/bin
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin~/.bashrc
(base) [root@node1 ~]# vim ~/.bashrc
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.9
export JAVA_HOME=/export/server/jdkspark
drwxr-xr-x 2 hadoop hadoop 4096 Apr 7 10:43 bin 可执行文件
drwxr-xr-x 2 hadoop hadoop 4096 Apr 7 10:43 conf 配置文件
drwxr-xr-x 5 hadoop hadoop 4096 Apr 7 10:43 data 数据
drwxr-xr-x 4 hadoop hadoop 4096 Apr 7 10:43 examples 实例
drwxr-xr-x 2 hadoop hadoop 16384 Apr 7 10:43 jars spark依赖jar
drwxr-xr-x 4 hadoop hadoop 4096 Apr 7 10:43 kubernetes
-rw-r--r-- 1 hadoop hadoop 22982 Apr 7 10:43 LICENSE
drwxr-xr-x 2 hadoop hadoop 4096 Apr 7 10:43 licenses
-rw-r--r-- 1 hadoop hadoop 57842 Apr 7 10:43 NOTICE
drwxr-xr-x 9 hadoop hadoop 4096 Apr 7 10:43 python spark的python支持库
drwxr-xr-x 3 hadoop hadoop 4096 Apr 7 10:43 R spark的R语言支持库
-rw-r--r-- 1 hadoop hadoop 4605 Apr 7 10:43 README.md
-rw-r--r-- 1 hadoop hadoop 165 Apr 7 10:43 RELEASE
drwxr-xr-x 2 hadoop hadoop 4096 Apr 7 10:43 sbin 启动关闭
drwxr-xr-x 2 hadoop hadoop 4096 Apr 7 10:43 yarn yarn的相关依赖项
进入pyspark解析器环境
cd park/bin
./pyspark
>>> sc.parallelize([1,2,3,4]).map(lambda x:x*10).collect()
[10, 20, 30, 40]master = local[*]
- 多少个cpu模拟多少个进程
可以查看一个任务的jvm的监控页面:4040
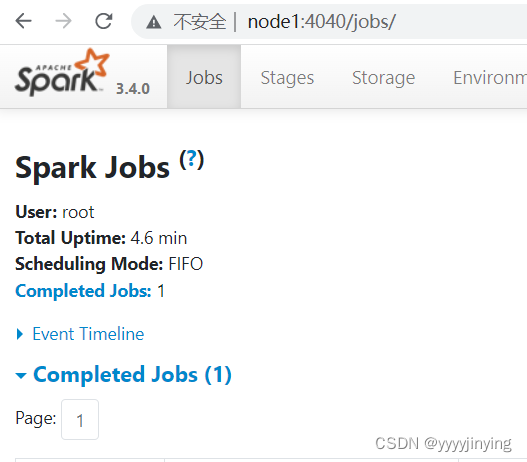
local进程分配了一系列线程在执行pyspark任务
./spark-shell
scala>
例证spark-submit 举例计算10的圆周率
(pyspark) [root@node1 bin]# ./spark-submit --master local[*] /export/server/spark/examples/src/main/python/pi.py 10Pi is roughly 3.135200提交之后,4040端口就关闭了# local模式运行的原理
以一个独立的进程配合内部的线程来完成spark运行时环境;local模式可以通过:spark-shell/pyspark/spark-submit等来开启# bin/pyspark是什么程序
交互式的解释器环境可以运行python代码,进行spark计算
# spark的端口
spark的任务运行之后,会在Driver所在机器的绑定4040端口,提供当前任务的监控页面# standalone架构
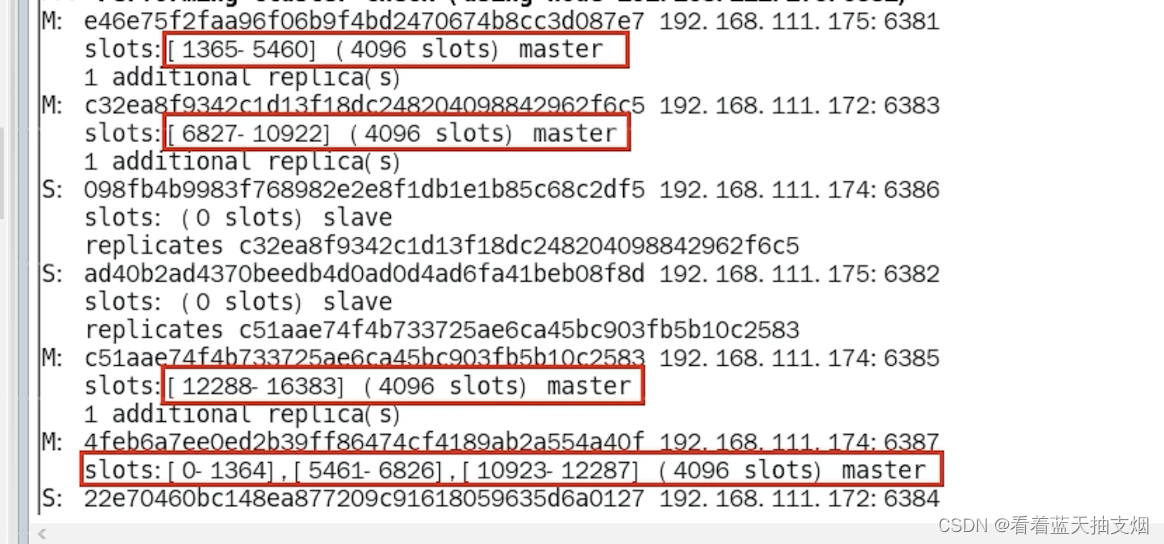
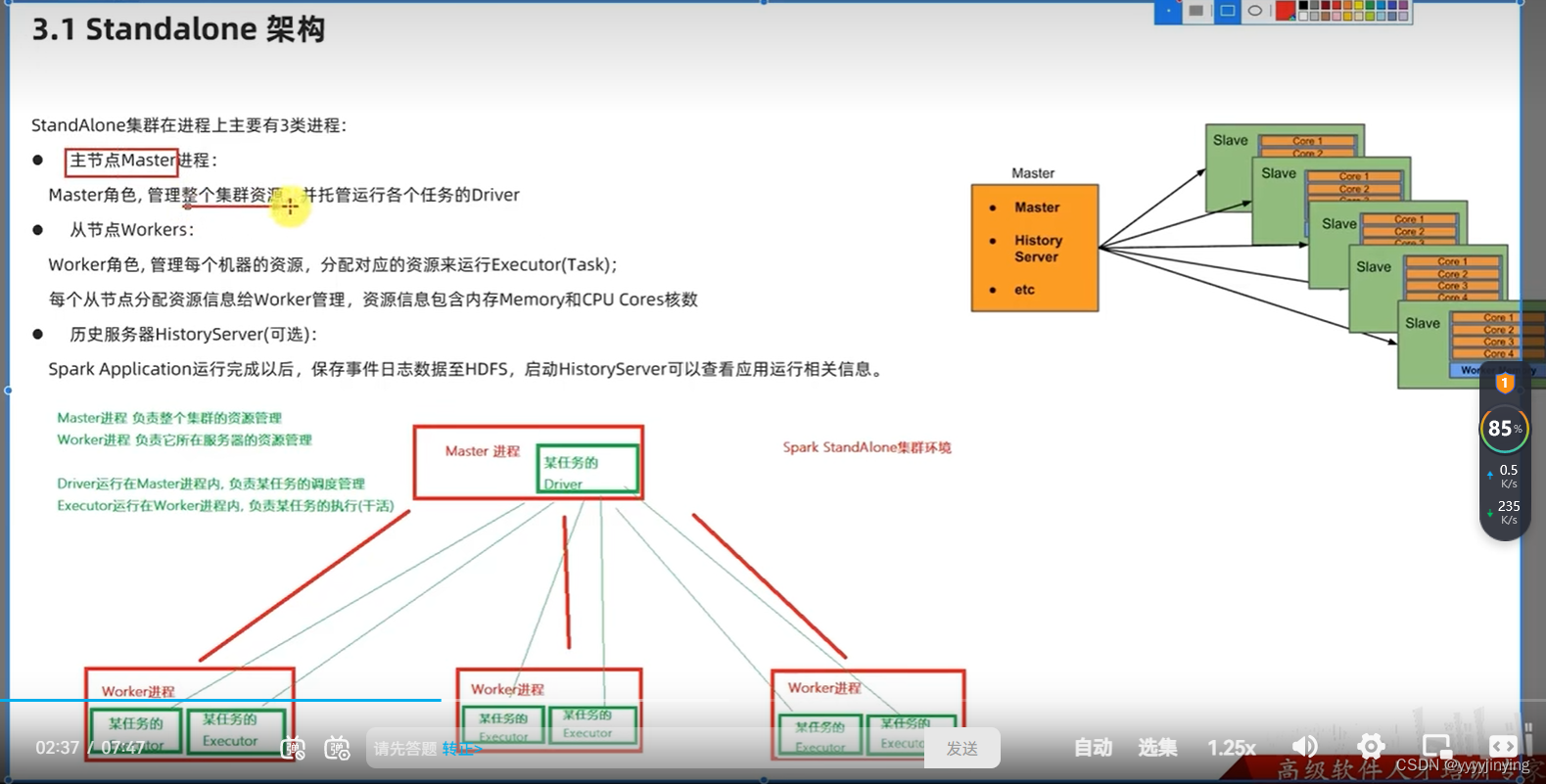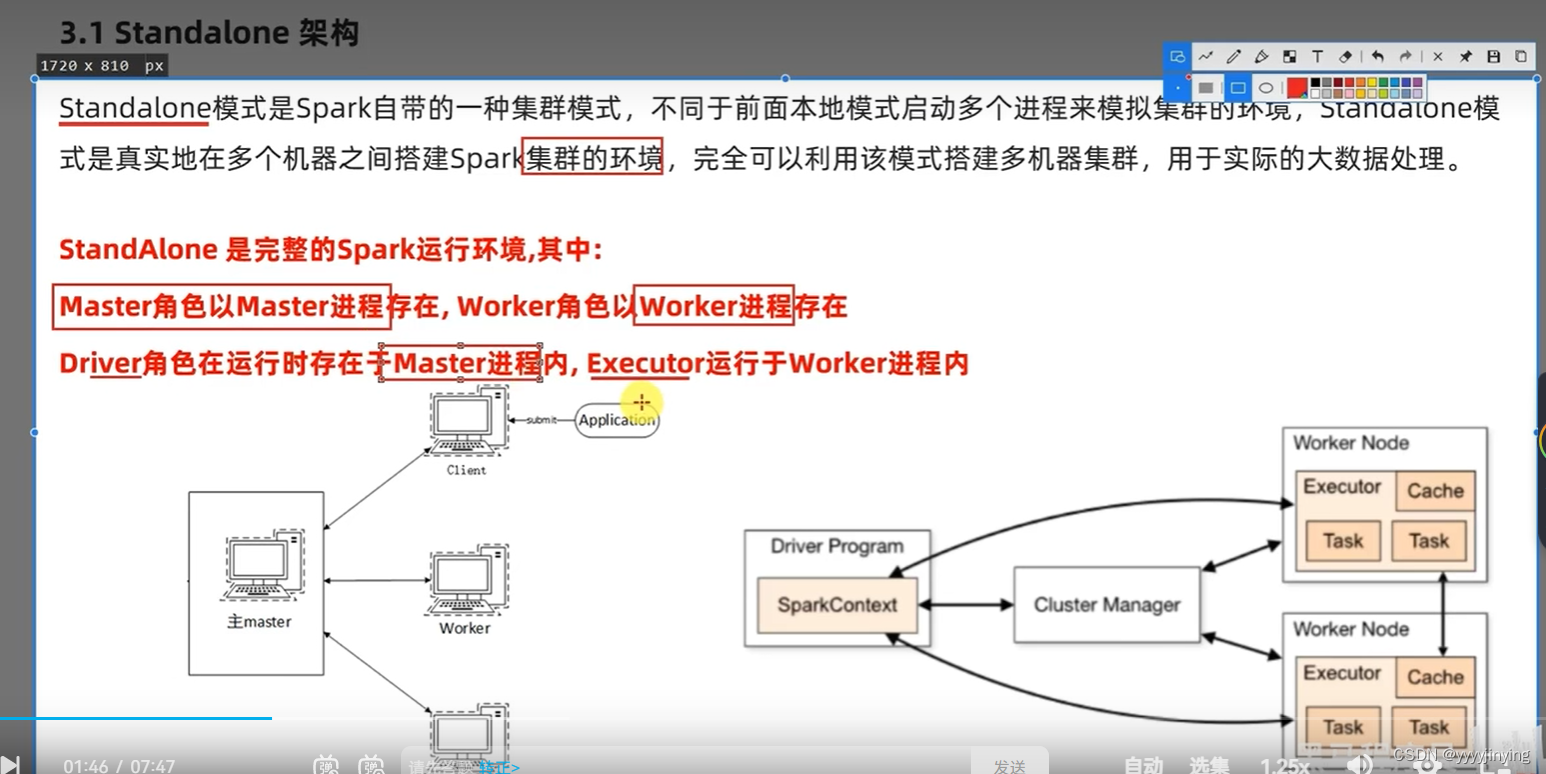## 集群规划
课程中 使用三台Linux虚拟机来组成集群环境, 非别是:
node1\ node2\ node3
node1运行: Spark的Master进程 和 1个Worker进程
node2运行: spark的1个worker进程
node3运行: spark的1个worker进程
整个集群提供: 1个master进程 和 3个worker进程
```linux
配置node2\node3
[hadoop@node1 server]$ scp Anaconda3-2021.05-Linux-x86_64.sh node2:`pwd`/cd /export/server
chown -R hadoop:hadoop spark*
chown -R hadoop:hadoop anaconda3*
su - hadoop
cd /export/server/spark
cd conf
ll
mv workers.template workers
vim workers
node1
node2
node3
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
JAVA_HOME=/export/server/jdkHADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoopexport SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparkog
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/sparklog/
spark.eventLog.compress true配置相同的node2,node3
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/export/server/hadoop
export SPARK_HOME=/export/server/spark
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.9
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinscp -r spark-3.4.0-bin-hadoop3 node2:`pwd`/
scp -r spark-3.4.0-bin-hadoop3 node3:`pwd`/
node2,node3
ln -s spark-3.4.0-bin-hadoop3 spark
启动历史服务
sbin/start-history-server.sh
启动spark的Master和Worker进程
sbin/start-all.sh
sbin/start-master.sh
sbin/start-worker.sh
sbin/stop-all.sh
jps
jobHistoryServer是yarn
historyserver 是spark
连接集群操作
spark/bin ./pyspark --master spark://node1:7077
》》》测试