1.表值聚合函数概念
自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。
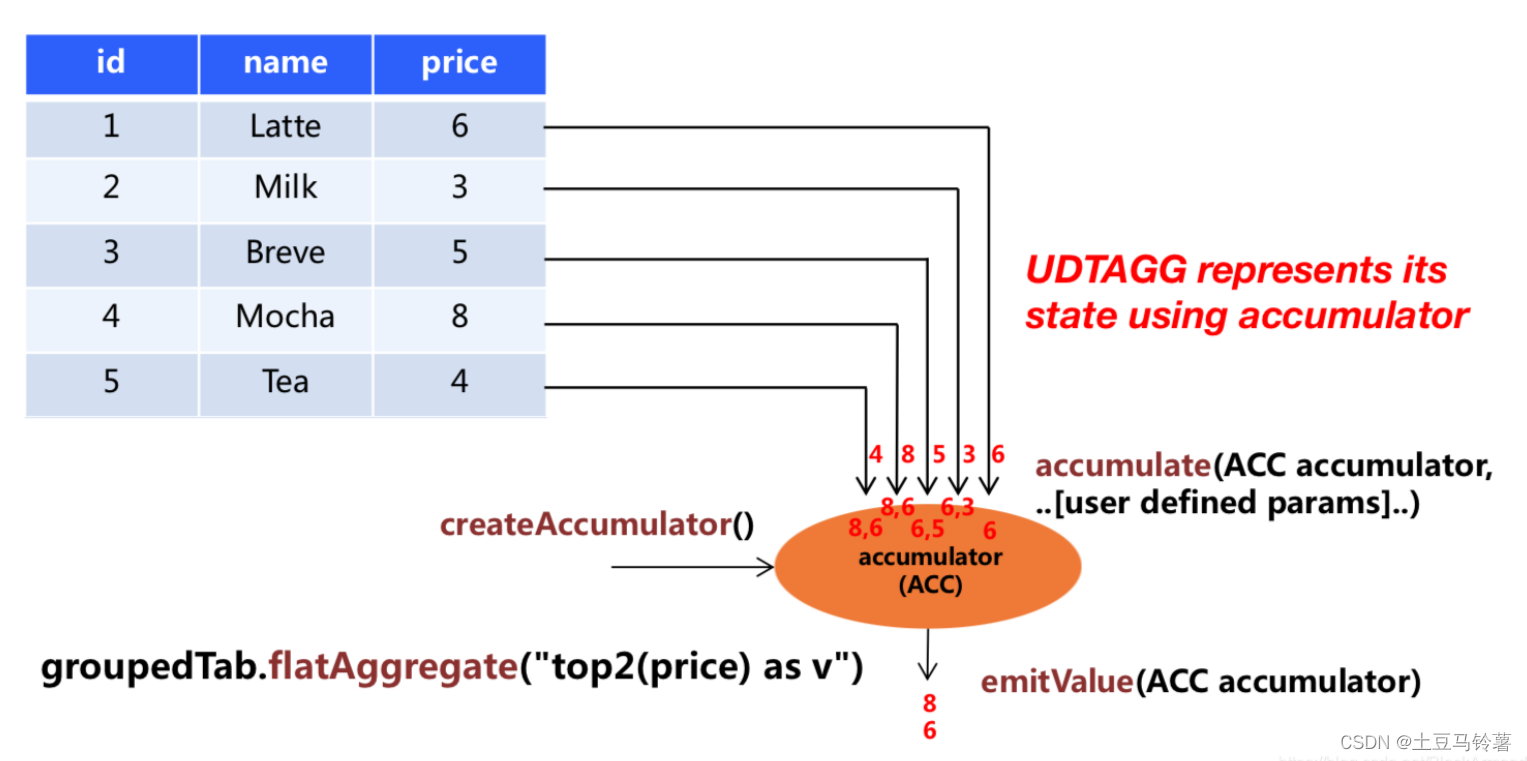
理解:假设有一个饮料的表,这个表有 3 列,分别是 id、name 和 price,一共有 5 行。假设你需要找到价格最高的两个饮料,类似于 top2() 表值聚合函数。你需要遍历所有 5 行数据,结果是有 2 行数据的一个表。
2.表值聚合函数实现
表值聚合函数是通过扩展 TableAggregateFunction 类来实现。
TableAggregateFunction实现原理:
- 构造accumulator,它负责存储聚合的中间结果。 通过调用 TableAggregateFunction 的 createAccumulator 方法来构造一个空的 accumulator。
- 对于每一行数据,调用 accumulate 方法来更新 accumulator。
- 当所有数据都处理完之后,调用 emitValue 方法来计算和返回最终的结果。
对应必须实现以下三个方法:
- createAccumulator():创建累加器
- accumulate():更新累加器
下面几个 TableAggregateFunction 的方法在某些特定场景下是必须要实现的:
- retract() :在 bounded OVER 窗口中的聚合函数必须要实现。
- merge() :在许多批式聚合和以及流式会话和滑动窗口聚合中是必须要实现
- resetAccumulator() :在许多批式聚合中是必须要实现的。
- emitValue() :在批式聚合以及窗口聚合中是必须要实现的。
提升流式任务的效率方式:
emitUpdateWithRetract() 在 retract 模式下,该方法负责发送被更新的值。emitValue 方法会发送所有 accumulator 给出的结果。拿 TopN 来说,emitValue 每次都会发送所有的最大的 n 个值。这在流式任务中可能会有一些性能问题。为了提升性能,用户可以实现 emitUpdateWithRetract 方法。这个方法在 retract 模式下会增量的输出结果,比如有数据更新了,我们必须要撤回老的数据,然后再发送新的数据。如果定义了 emitUpdateWithRetract 方法,那它会优先于 emitValue 方法被使用,因为一般认为 emitUpdateWithRetract 会更加高效,因为它的输出是增量的。
注意:
- TableAggregateFunction 的所有方法都必须是 public 的、非 static 的,而且名字必须跟上面提到的一样。
- createAccumulator、getResultType 和 getAccumulatorType 这三个方法是在抽象父类 TableAggregateFunction 中定义的,而其他的方法都是约定的方法。
- 要实现一个表值聚合函数,必须扩展org.apache.flink.table.functions.TableAggregateFunction,并且实现一个(或者多个)accumulate 方法。
- accumulate 方法可以有多个重载的方法,也可以支持变长参数。