参考:
关系抽取之TPLinker解读加源码分析
TPLinker 实体关系抽取代码解读
实体关系联合抽取:TPlinker
TPLinker中文注释版
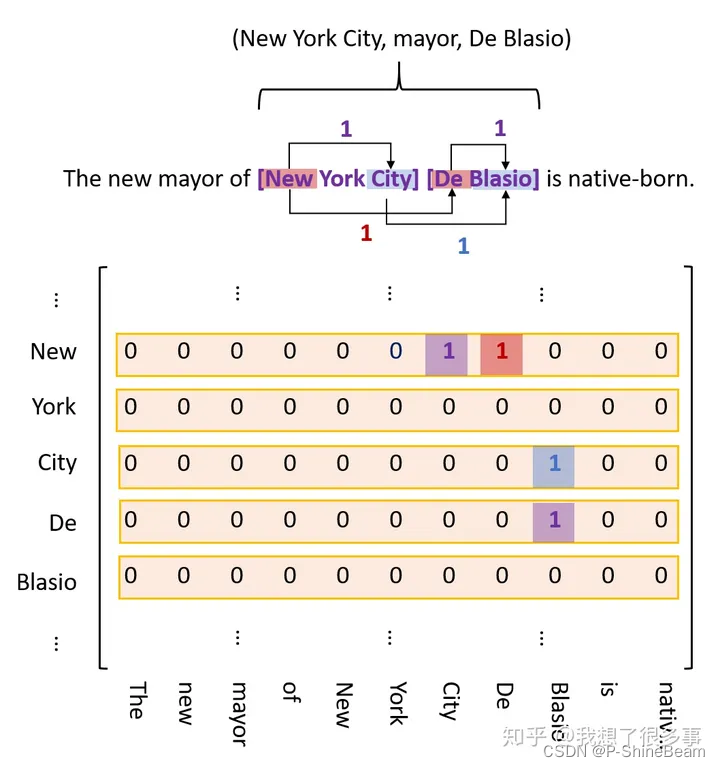
Tagging
TPLinker模型需要对关系三元组(subject, relation, object)进行手动Tagging,过程分为三部分:
(1)entity head to entity tail (EH-TO-ET)
(2)subject head to object head (SH-to-OH)
(3)subject tail to object tail (ST-to-OT)
标记示例见下图,EH-TO-ET用紫色表示,SH-to-OH用红色表示,ST-to-OT用蓝色表示。

模型框架
模型比较简单,整个句子过一遍 encoder,然后将 token 两两拼接输入到一个全连接层,再激活一下输出作为 token 对的向量表示,最后对 token 对进行分类即可。换句话说,这其实是一个较长序列的标注过程。

预测三元组
将模型对应的输出结果与输入的text进行匹配,解码出所需要的三元组。
通常先进行实体抽取得到字典D(key是实体头部,value是实体尾部)。
通过解码ST-to-OT关系得到有关系的两个实体的尾部,构建为字典E
通过解码SH-to-OH关系得到有关系的两个实体的头部,然后结合字典D,可以得到后续两个实体尾部。判断这两个实体尾部在不在字典E里面,如果在就是成功抽取了一条三元组。
训练数据的格式:
{"text": "In Queens , North Shore Towers , near the Nassau border , supplanted a golf course , and housing replaced a gravel quarry in Douglaston .", "id": "valid_0", "relation_list":
[{"subject": "Douglaston", "object": "Queens", "subj_char_span": [125, 135], "obj_char_span": [3, 9], "predicate": "/location/neighborhood/neighborhood_of", "subj_tok_span": [26, 28], "obj_tok_span": [1, 2]}, {"subject": "Queens", "object": "Douglaston", "subj_char_span": [3, 9], "obj_char_span": [125, 135], "predicate": "/location/location/contains", "subj_tok_span": [1, 2], "obj_tok_span": [26, 28]}], "entity_list":
[{"text": "Douglaston",
"type": "DEFAULT",
"char_span": [125, 135],
"tok_span": [26, 28]},
{"text": "Queens", "type": "DEFAULT", "char_span": [3, 9], "tok_span": [1, 2]},
{"text": "Queens", "type": "DEFAULT", "char_span": [3, 9], "tok_span": [1, 2]},
{"text": "Douglaston", "type": "DEFAULT", "char_span": [125, 135], "tok_span": [26, 28]}]}训练数据的最外层有4个主键:
- “text”:输入数据的文本
- “id”:输入数据的id
- “relation_list”:输入数据文本当中存在的关系。
- “entity_list”:输入数据文本当中存在的实体。
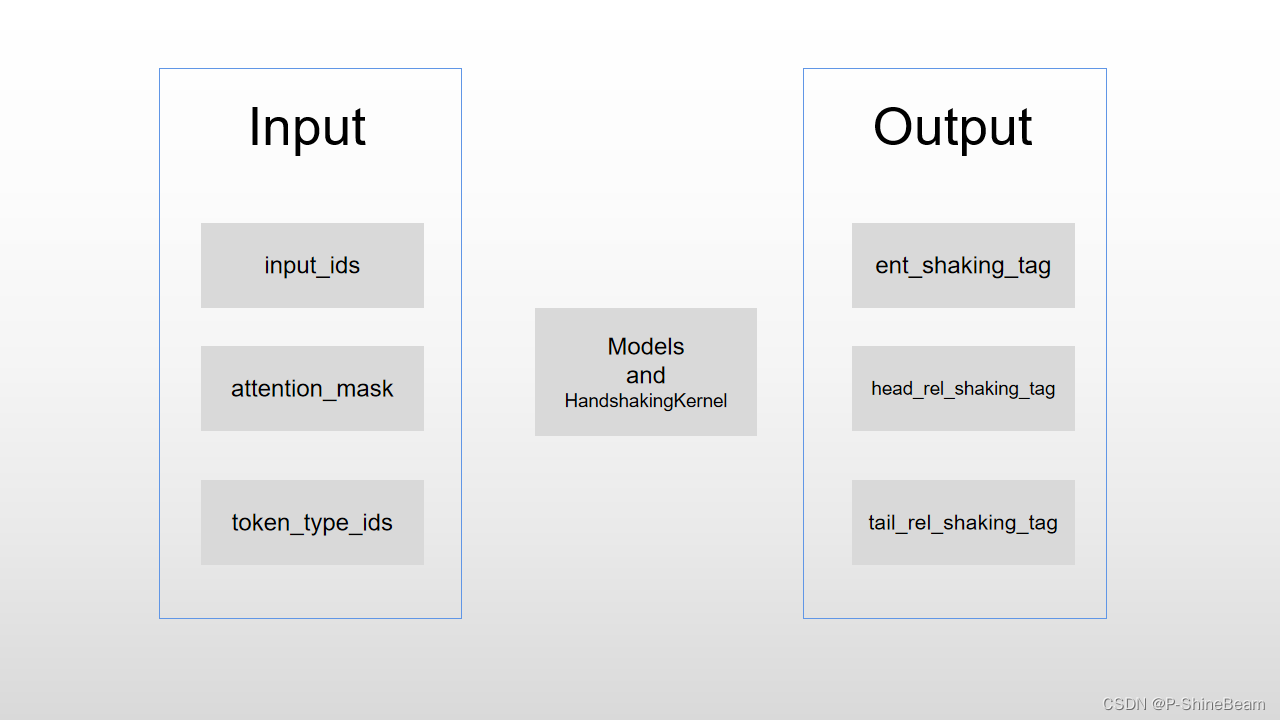
模型所需要的输入数据
- 其中作为输入的有:
- batch_input_ids:是单词在词典中的编码
- batch_attention_mask:指定对哪些词进行self - Attention操作
- batch_token_type_ids:区分两个句子的编码(上句全为0,下句全为1)
- 其中作为模型输出的标签来辅助更新权重的有:
- batch_ent_shaking_tag:token的【起始位置,尾部位置,实体标签】
- batch_head_rel_shaking_tag:【关系类别,实体_1 头部,实体_2头部,关系标签a】
- batch_tail_rel_shaking_tag:【关系类别,实体_1 尾部,实体_2尾部,关系标签b】
根据模型所需要输入的数据对训练数据进行一系列的处理。
调整训练时的参数去训练自己的数据。
调整输入输出为自己喜欢的样式。