目录:
- 前言
- 分析vector不同操作对时间的影响
- 1.for循环中使用 size()成员函数
- 2.初始化时初始化为0,与其他值
- 3.vector分配容量问题
- 4. vector赋值操作
- 5. 遍历:下标和迭代器
- 总结
前言
| 打怪升级:第90天 |
|---|
 |
分析vector不同操作对时间的影响
1.for循环中使用 size()成员函数
#include<iostream>
#include<ctime> // time_t, clock
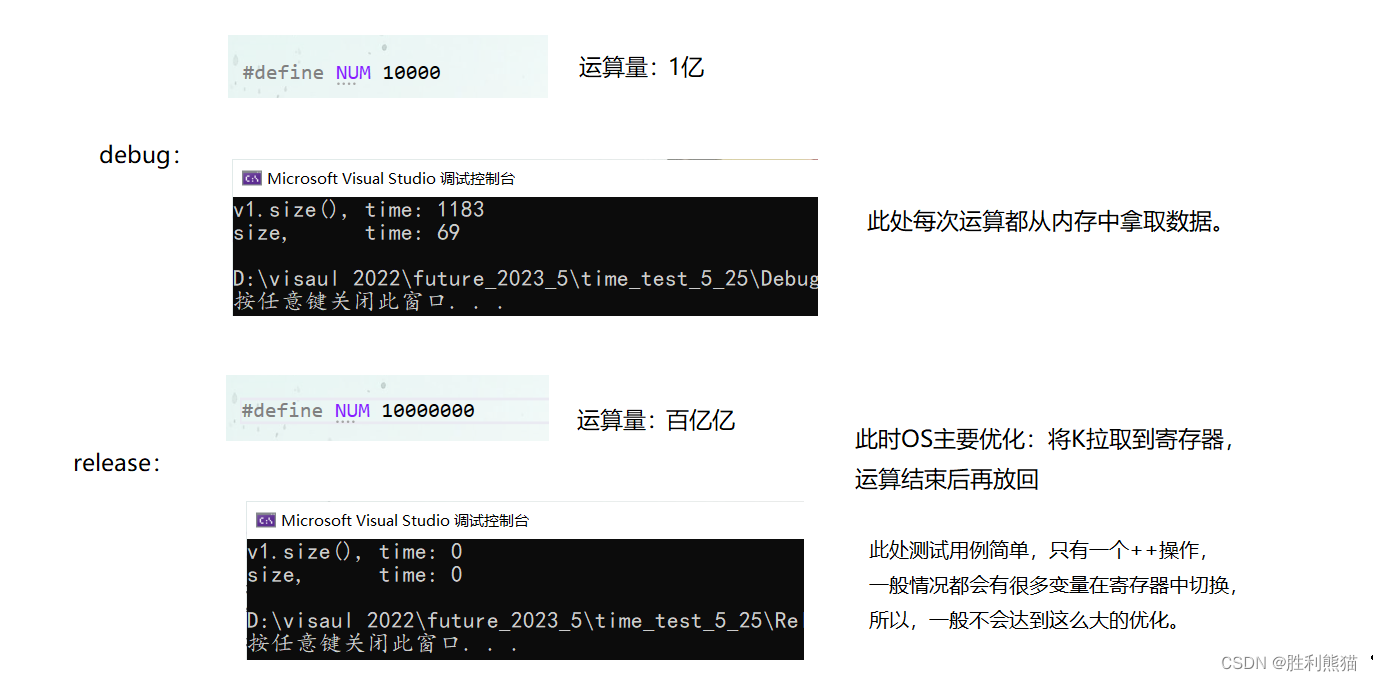
#include<vector>using namespace std;#define NUM 1000000void test_time_1()
{vector<int>v1(NUM);for (int i = 0; i < NUM; ++i) v1[i] = i;int k = 0;time_t begin1 = clock();for (int i = 0; i < v1.size(); ++i){for (int j = 0; j < v1.size(); ++j){++k;}}time_t end1 = clock();k = 0;time_t begin2 = clock();size_t size = v1.size();for (int i = 0; i < size; ++i){for (int j = 0; j < size; ++j){++k;}}time_t end2 = clock();cout << "v1.size(), time: " << end1 - begin1 << endl;cout << "size, time: " << end2 - begin2 << endl;
}
-
结果:
debug下使用变量快很多很多(20倍左右),release下两者差别不大。 -
结论:
在release模式下可能编译器对函数调用做了很大优化;
但是循环中,还是推荐使用变量保存size,否则每次循环都需要调用 size()成员函数,量级大的情况下消耗还是不小的。
2.初始化时初始化为0,与其他值
#define NUM 100000000 void test_time_2()
{time_t begin1 = clock();// vector<int>v1(NUM);vector<vector<int> >v1(NUM, vector<int>(NUM));time_t end1 = clock();time_t begin2 = clock();//vector<int>v2(NUM, 0);vector<vector<int> >v2(NUM, vector<int>(NUM, 0));time_t end2 = clock();time_t begin3 = clock();// vector<int>v3(NUM, -1);vector<vector<int> >v3(NUM, vector<int>(NUM, 1));time_t end3 = clock();cout << "init empty, time: " << end1 - begin1 << endl;cout << "init zero, time: " << end2 - begin2 << endl;cout << "init 100, time: " << end3 - begin3 << endl;
}
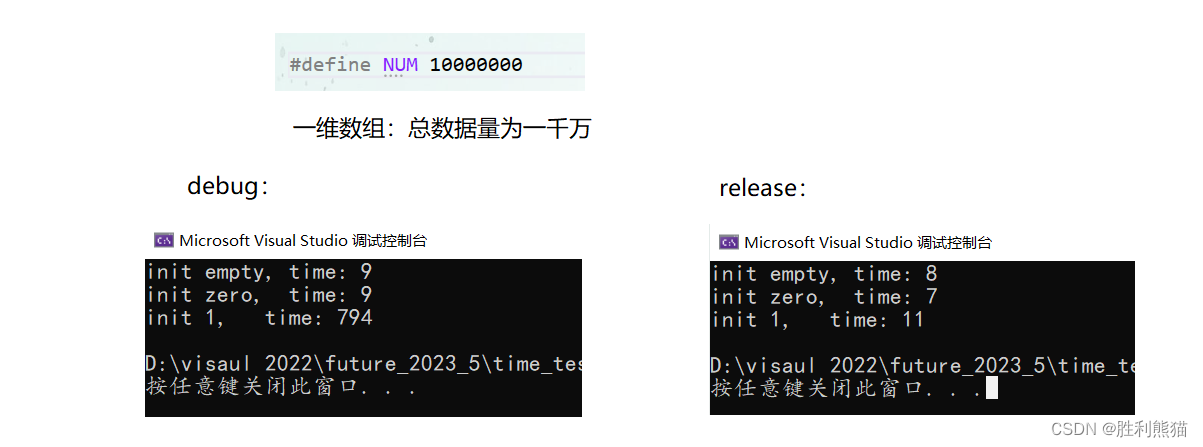
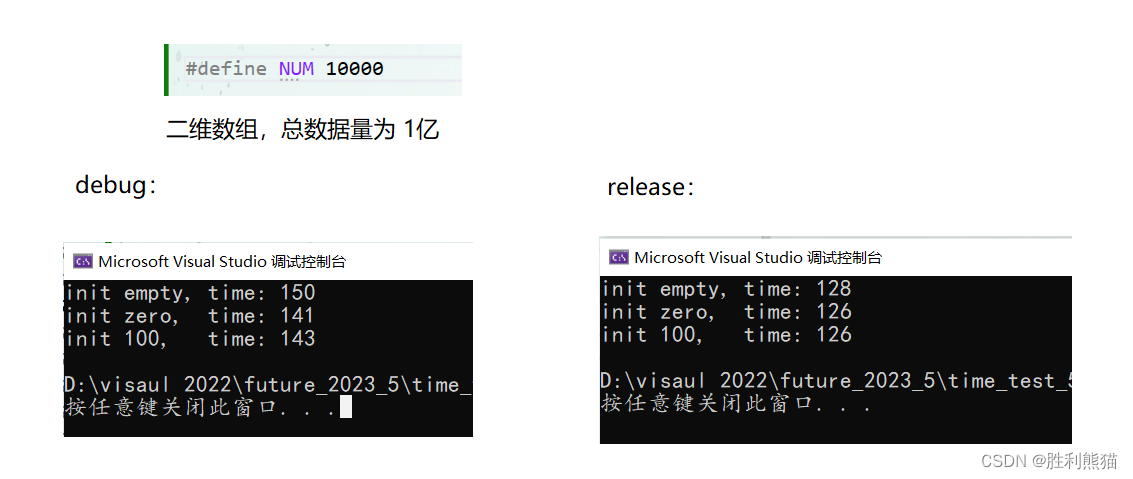
-
结果:
a. 一维数组:不初始化或者初始化为0,都比较快,
如果初始化为其他值:1也好,3423121也好,时间消耗都会增大很多(20倍左右),同时,不同初始化值所用时间是一样的
b. 二维数组:三者时间差别不大。 -
结论:
如果后续需要输入其他数据,不初始化即可;
如果不是必要,不建议刚开始就全部初始化为非0值。
3.vector分配容量问题
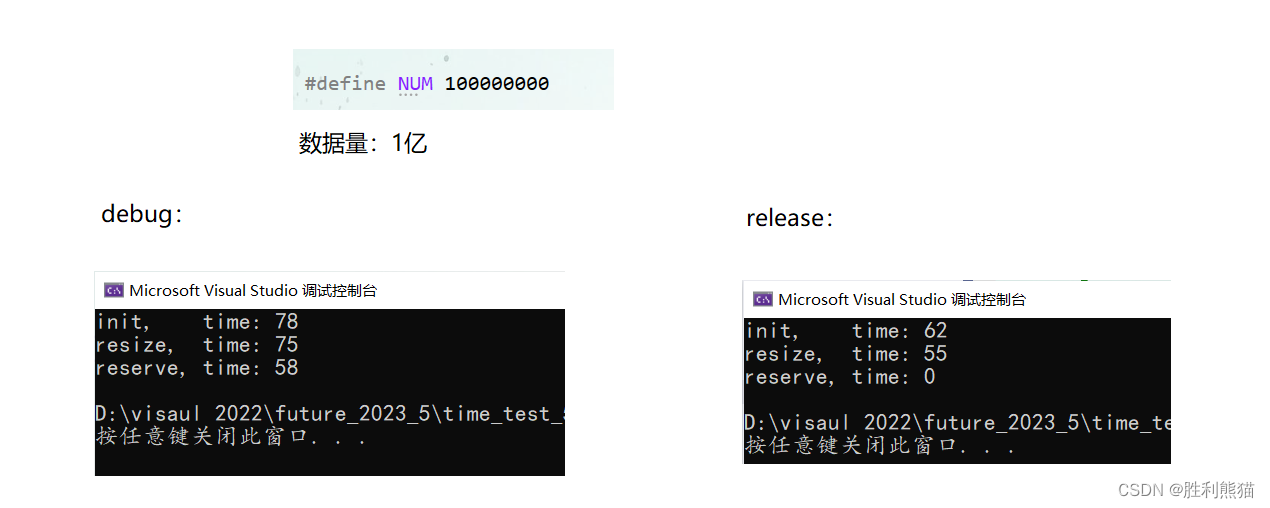
#define NUM 100000000 void test_time_3()
{time_t begin1 = clock();vector<int>v1(NUM);time_t end1 = clock();time_t begin2 = clock();vector<int>v2;v2.resize(NUM);time_t end2 = clock();time_t begin3 = clock();vector<int>v3;v3.reserve(NUM);// v3.resize(NUM); // 在加一个resize,时间消耗基本无差别time_t end3 = clock();cout << "init, time: " << end1 - begin1 << endl;cout << "resize, time: " << end2 - begin2 << endl;cout << "reserve, time: " << end3 - begin3 << endl;
}
-
结果:
声明位置设置大小,以及使用resize、reserve时间消耗差不多,reverse用时略小,因为不用初始化数据。 -
结论:
数据量在百万以内差别不大,如果后面需要输入数据,推荐使用resize,至于原因请看第四个测试用例。
4. vector赋值操作
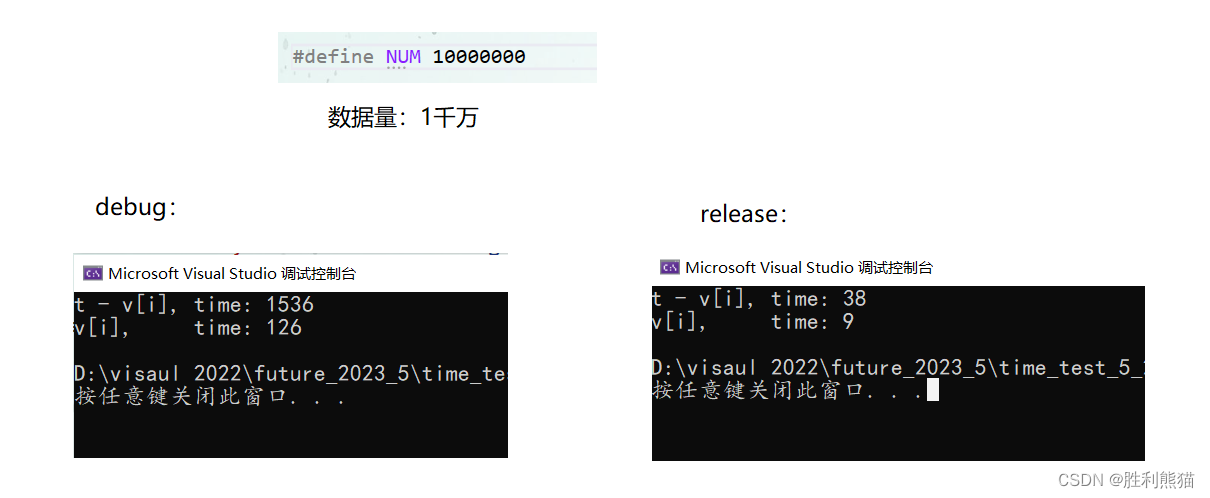
#define NUM 10000000void test_time_4()
{time_t begin1 = clock();vector<int>v1; // 初始不设置大小for (int i = 0; i < NUM; ++i){int t = i;v1.push_back(t);// 模拟: cin >> num;// v.push_back(num);}time_t end1 = clock();time_t begin2 = clock();vector<int>v2(NUM);for (int i = 0; i < NUM; ++i){v2[i] = i;// 模拟:cin >> v[i];}time_t end2 = clock();cout << "t - v[i], time: " << end1 - begin1 << endl;cout << "v[i], time: " << end2 - begin2 << endl;
}
-
结果:
调用push_back消耗很大 – 10倍以上 -
结论:
不推荐借用中间变量后调用push_back,
推荐直接使用 v[i]接收数据
5. 遍历:下标和迭代器
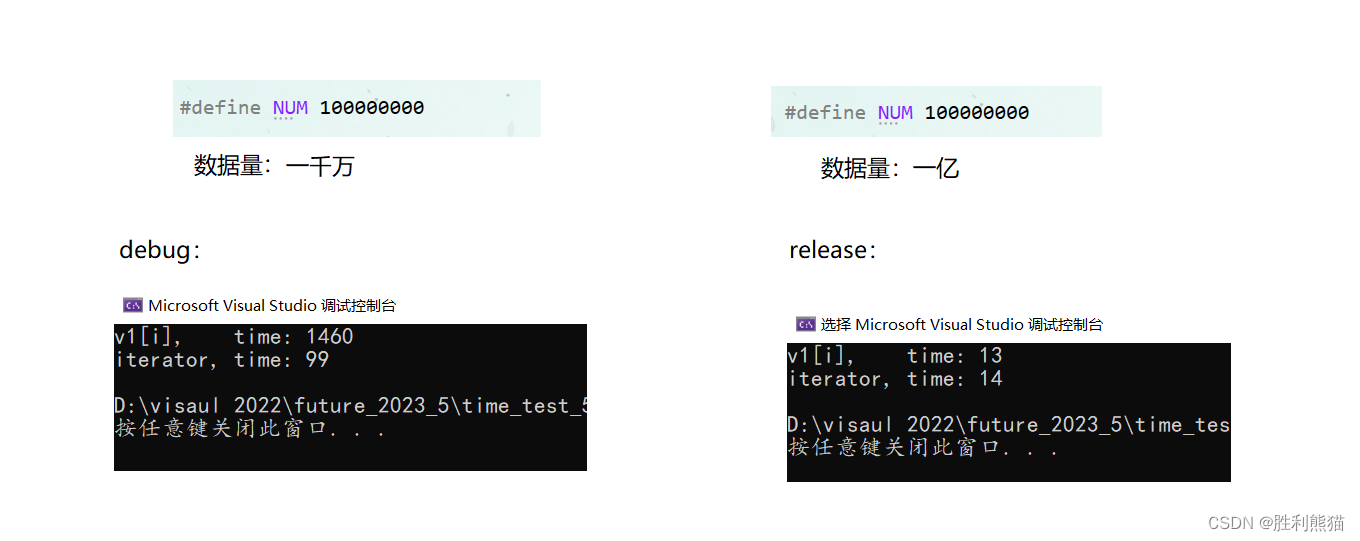
#define NUM 100000000 void test_time_5()
{vector<int>v1(NUM);for (int i = 0; i < NUM; ++i) v1[i] = i;// 测试下标遍历和迭代器遍历的速度time_t begin1 = clock();size_t size = v1.size();for (size_t i = 0; i < size; ++i) v1[i] = 0;time_t end1 = clock();/* // 范围for的底层实现使用的迭代器vector<int>::iterator it = v1.begin();while (it != v1.end()){*it = 0;++it;}*/time_t begin2 = clock();for (auto& e : v1) e = 0;time_t end2 = clock();cout << "v1[i], time: " << end1 - begin1 << endl;cout << "iterator, time: " << end2 - begin2 << endl;
}
-
结果:
debug条件下,迭代器访问的速度要快很多很多 – 10倍以上;
release条件下,访问速度相差不大。 -
结论:
推荐在能使用迭代器的条件下尽量使用迭代器访问,既范围for
那么什么时候适合使用? – 不需要使用下标的情况下。
总结
- 在for循环中如果使用到成员变量(如size()),作为判断,十分推荐将该值保存到一个临时变量,之后使用临时变量来代替它进行判断,
否则调用多次进行函数调用会拖慢CPU运算速度; - 声明容器变量是,是否初始化大小都可以,因为在任何地方都一样,当然如果需要给容器数据初始化,如果不是一定要使用某些值,不建议初始化为非0值;
- vector添加成员时,十分推荐先开好空间,之后直接通过下标( v[i] )进行赋值;如果借用一个临时变量,再进行push_back()也会大大拖慢cpu指向速度;
- 遍历容器时,如果我们不需要使用下标,就十分推荐使用范围for。
以上的建议都是针对数据量大的情况下使用的,百万、千万以上的量级,
如果平时使用,100、10000等小量级则差别不大,
不过,好习惯早早养成还是很有必要的,希望本文可以为有需要的朋友提供帮助。