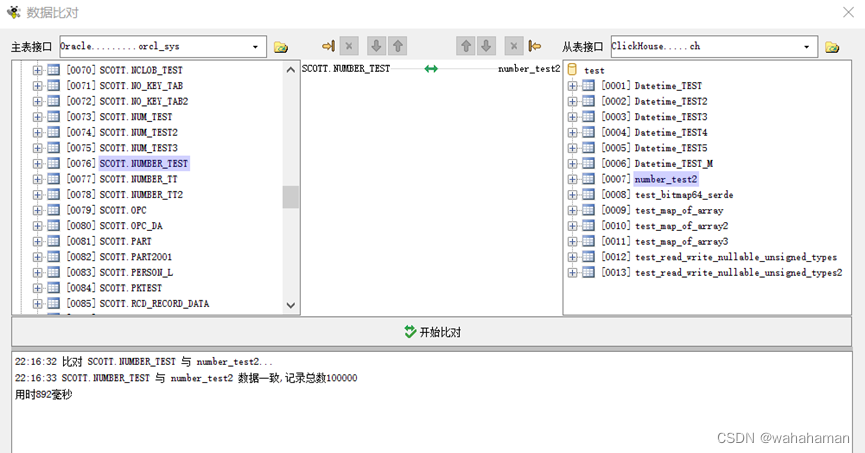
一)什么是虚拟化?容器化?
1)物理机:实际的服务器或者计算机,相对于虚拟机而言的对实体计算机的称呼。物理
机提供给虚拟机以硬件环境,有时也称为“寄主”或“宿主;2)虚拟化:是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机,在一台计算机上
同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统和硬盘,并且应用程序都
可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率;3)容器化:容器化是一种虚拟化技术,又称操作系统层虚拟机,虚拟化的是操作系统软件层,这种技术将操作系统内核虚拟化,可以允许用户空间软件实例,被分割成几个独立的单元,在内核中运行,而不是只有一个单一实例运行,这个软件实例,也被称为是一个容器,对每个实例的拥有者与用户来说,他们使用的服务器程序,看起来就像是自己专用的,容器技术是虚拟化的一种,docker 是现今容器技术的事实标准;
二)为什么要虚拟化?容器化? 实现资源的隔离和控制
一)资源利用率高:比如说像阿里云华为云买了一个1C2G的服务器,其实背后有一个很大的服务器,会切分1C2G给不同的用户,什么时候这个1C2G用户不再使用了,就归还给这个服务器,下一次就分发给不同的用户;
二)环境标准化:在本地开发环境是什么样子,那么在生产环境就是什么样子,一次构建,随处执行,实现执行环境的标准化发布,部署和运维,开发过程中一个常见的问题是环境一致性问题,由于开发环境、测试环境、生产环境不一致,导致有些bug 并未在开发过程中被发现,而 Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性;
三)资源的弹性伸缩:如果不使用虚拟化和容器化,那么如果要进行扩招,只能使用物理机,要100台服务器,就需要扩展100台服务器,而有了虚拟化和容器化之后,第一台物理机扩50个,第二台物理机又扩50个,而收缩也非常简单,从而在一台服务器就可以做伸缩了
四)差异化环境提供:假设说我的服务一个使用Ubuntu的操作系统,一个服务依赖于Centos操作系统,但是没有预算买两个物理机,这个时候容器化就能提供很多不同的环境,可以把一个物理机切分成很多模块,每一块装不同的操作系统,这样每一个人要的不同的操作系统就都满足
五)沙箱安全:为了避免不安全或者是不稳定软件对于整个系统的影响,可以使用虚拟化技术来构建虚拟化环境,虚拟化以后并不会影响宿主机器或者物理机,比如我在容器里面执行 rm -rf /* 不会把整个服务器搞死,也不影响其他人部署的程序使用;
六)容器相比于虚拟机更轻量,启动速度更快:传统的虚拟机技术启动应用服务往往需要数分钟,但是docker容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级,甚至毫秒级的启动时间和进程启动一样快,大大节省了开发测试部署的时间;
七)维护和扩展容易
三)虚拟化的常见类别:
虚拟机:存在于硬件层和操作系统层级别的虚拟化技术,虚拟机通过伪造一个硬件抽象接口,将一个操作系统以及操作系统层以上的层嫁接到硬件上面,实现和真实的物理机一模一样的功能,比如我们在一台 Windows 系统的电脑上使用 Android 虚拟机,就能够用这台电脑打开 Android 系统上的应用;
容器:存在于操作系统层和函数库层之间的虚拟化技术,容器通过"伪造"操作系统的接口,
将函数库层以上的功能置于操作系统上,以 Docker 为例,其就是一个基于 Linux 操作
系统的 Namespace 和 Cgroup 功能实现的隔离容器,可以模拟操作系统的功能,简单
来说,如果虚拟机是把整个操作系统封装隔离,从而实现跨平台应用的话,那么容器
则是把一个个应用单独封装隔离,从而实现跨平台应用,所以容器体积比虚拟机小很
多,理论上占用资源更少,容器化就是应用程序级别的虚拟化技术,容器提供了将应
用程序的代码、运行时、系统工具、系统库和配置打包到一个实例中的标准方法,容
器共享一个操作系统内核,它安装在硬件上;
四)容器的虚拟化
1)实现原理:是操作系统级别的一个虚拟化,对程序的隔离以及对资源的控制来实现的,假设现在有两个进程,进程A和进程B,当这两个进程启动的时候,各自进程会把自己所需要的所有文件包括操作系统的文件放好准备好,当进程启动的时候,让这个进程只是看到这些文件和操作系统的文件,假设这个容器在8G的物理机上面分配了2G的内存,那么这个容器启动的时候是只能看到2G的内存的,那么这个进程就被欺骗了操作系统内存以及网络文件等资源信息;
2)这样就是两个进程或者两个操作系统所看到的操作系统的文件完全不一样;
3)操作系统内核是共用的;
总结:容器虚拟化是操作系统级别的虚拟化,通过namespace进行个程序的隔离,加上cgroups实现对资源的控制,以此来完成虚拟化;
五)namespace:
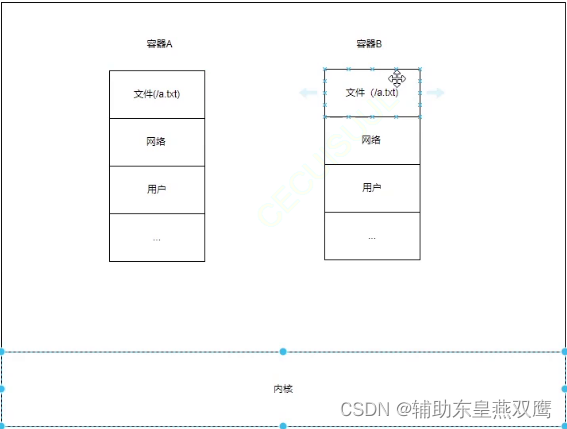
namespace是linux内核用来隔离内核资源的技术方式,通过namespace可以让一些进程只能看到和自己相关的一分部资源,而让另外一些进程也只能看到和他们自己相关的一部分资源,这两拨进程根本就感受不到对方的存在,具体的实现方式是把一个进程或者多个进程的内核相关资源指定在同一个namespace中;
下面是linux进行隔离的内核资源
1)主机名和域名:即使两个进程运行在同一台主机上,它们可以有不同的主机名和域名
2)例如说网络端口,A进程可以有自己的80端口,但是B进程也可以有自己的80端口
3)文件系统挂载点:两个进程都看到了/etc目录,但是他们并不都是同一个目录
4)用户和用户组:两个进程可以可以有不同的用户和用户组
5)IPC:同一个 IPC namespace 的进程之间能互相通讯,不同的 IPC namespace之间
不能通信
6)PID:每个 PID namespace 中的进程可以有其独立的 PID,每个容器可以有其 PID 为
1 的 root 进程7)Network:每个容器用有其独立的网络设备,IP 地址,IP 路由表,/proc/net 目录,端
口号8)Mount:每个容器能看到不同的文件系统层次结构


六)空间隔离实战:
隔离能力并不是docker提供的,而是由操作系统提供的
1.dd命令:用于读取,转换并且输出数据,dd可以读取一个文件经过中间的转换之后再输出到另外一个文件中
一)基本使用dd OPTION(选项)
1)if=文件名:输入文件名,默认为标准输入,即指定源文件
2)of=文件名:输出文件名,默认为标准输出,即指定目的文件
3)ibs=bytes:一次读入 bytes 个字节,即指定一个块大小为 bytes 个字节
4)obs=bytes:一次输出 bytes 个字节,即指定一个块大小为 bytes 个字节
5)bs=bytes:同时设置读入/输出的块大小为 bytes 个字节
6)cbs=bytes:一次转换 bytes 个字节,即指定转换缓冲区大小7)skip=blocks:从输入文件开头跳过 blocks 个块后再开始复制。
8)seek=blocks:从输出文件开头跳过 blocks 个块后再开始复制。
9)count=blocks:仅拷贝 blocks 个块,块大小等于 ibs 指定的字节数。
10conv=<关键字>,关键字可以有以下 11 种:
1.1)conversion:用指定的参数转换文件。
1.2)ascii:转换 ebcdic 为 ascii
1.3)ebcdic:转换 ascii 为 ebcdic1.4)ibm:转换 ascii 为 alternate ebcdic
1.5)block:把每一行转换为长度为 cbs,不足部分用空格填充
1.6)unblock:使每一行的长度都为 cbs,不足部分用空格填充
1.7)lcase:把大写字符转换为小写字符
1.8)ucase:把小写字符转换为大写字符
1.9)swap:交换输入的每对字节
1.9.1)noerror:出错时不停止
1.9.2)notrunc:不截短输出文件
1.9.3)sync:将每个输入块填充到 ibs 个字节,不足部分用空(NUL)字符补齐二)生成一个指定大小的镜像文件:dd if=/dev/zero(of=test.image bs=8K count=1024,这个命令最后生成的文件是8*1024K=8M大小的一个文件;
/dev/zero 这个文件是linux系统中的一个特殊的文件设备能够连续不断地产生空白的字符流
三)将redis.txt中的文件的所有英文字母转化成大写,然后写入到mysql.txt文件里面
dd if=redis.txt of=mysql.txt conv=ucase
2.mkfs命令:
一.mkfs命令主要是为了在设备上创建linux文件系统,比如说我们使用U盘的时候可以进行格式化,linux文件系统是指文件存在的物理空间,linux的每一个分区都是一个文件系统,都有着自己的目录层次结构,linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构
mkfs [-V] [-t fstype] [fs-options] filesys [blocks]
1)-t fstype:指定要建立何种文件系统;如 ext3,ext4
2)filesys :指定要创建的文件系统对应的设备文件名;
3)blocks:指定文件系统的磁盘块数。
4)-V : 详细显示模式
5)fs-options:传递给具体的文件系统的参数格式化镜像文件为 ext4
mkfs -t ext4 ./fdimage.img将 sda6 分区格式化为 ext4 格式
mkfs -t ext4 /dev/sda6
3.df:linux中的df命令用于显示目前在linux系统上面的文件系统磁盘的使用情况统计
df [OPTION]... [FILE]...
常见参数
1)-a, --all 包含所有的具有 0 Blocks 的文件系统
2)-h,--human-readable 使用人类可读的格式(预设值是不加这个选项的...)
3)-H,--si 很像 -h,但是用 1000 为单位而不是用 1024
4)-t,--type=TYPE 限制列出文件系统的 TYPE
5)-T, --print-type 显示文件系统的形式df:系统会把可用量,使用量,使用的比例全部完成打印以及挂载点的信息
df -a:把当前的0 block快的内容全部给打印出来了
df -h
df -t ext4:是把ext4这个文件系统完成了过滤
df -T也把具体的文件系统的类型也打印出来了,当然后面也可以跟上对应的目录,就可以看到对应的文件系统的信息了
df -H
df -h单位不同
4.mount:mount 命令用于加载文件系统到指定的加载点。此命令的也常用于挂载光盘,使我们可以访问光盘中的数据,因为你将光盘插入光驱中,Linux 并不会自动挂载,必须使用
Linux mount 命令来手动完成挂载,Linux 系统下不同目录可以挂载不同分区和磁盘设备,它的目录和磁盘分区是分离的,可以自由组合(通过挂载),不同的目录数据可以跨越不同的磁盘分区或者不同的磁盘设备,挂载的本质是为磁盘添加入口比如说我买了一个U盘,插在了我的电脑上面,这个时候产生了一个新的磁盘E:,这就叫做把U盘挂载到这个windows系统上面的E目录;
mount [-l]
mount [-t vfstype] [-o options] device dir1)l:显示已加载的文件系统列表;
2)-t: 加载文件系统类型支持常见系统类型的 ext3,ext4,iso9660,tmpfs,xfs 等,大部分情况
可以不指定,mount 可以自己识别
3)-o options 主要用来描述设备或档案的挂接方式。
3.1)loop:用来把一个文件当成硬盘分区挂接上系统
3.2)ro:采用只读方式挂接设备
3.3)rw:采用读写方式挂接设备
4)device: 要挂接(mount)的设备。
5)dir: 挂载点的目录将 /dev/hda1 挂在 /mnt 之下
mount /dev/hda1 /mnt
将镜像挂载到/mnt/testext4 下面,需要确保挂载点也就是目录存在
mkdir -p /mnt/testext4
mount ./fdimage.img /mnt/testext4
5)unshare命令主要是为了使用父亲程序不共享的命名空间运行程序
unshare [options] program [arguments]
-i, --ipc 不共享 IPC 空间
-m,--mount 不共享 Mount 空间
-n,--net 不共享 Net 空间
-p, --pid 不共享 PID 空间
-u, --uts 不共享 UTS 空间
-U, --user 不共享用户
-V, --version 版本查看
--fork 执行 unshare 的进程 fork 一个新的子进程,在子进
程里执行 unshare 传入的参数。
--mount-proc 执行子进程前,将 proc 优先挂载过去进行主机名字的隔离:unshare -u /bin/bash
hostname test1
hostname-----此时返回的结果是test1
exit---退出进程
hostname----此时返回的结果是hecs-133460
一)实现进程的PID隔离:
unshare -p /bin/bash
一旦指定了-p的隔离之后,/bin/bash看不见外部的pid信息,因为内部的PID已经发生了隔离,没有看见自己的父进程,所以说解决方案就是创建一个全新的进程;
--fork 新建了一个 bash 进程,是因为如果不建新进程,新的 namespace 会用 unshare
的 PID 作为新的空间的父进程,而这个 unshare 进程并不在新的 namespace 中,所
以会报个错 Cannot allocate memory;unshare -p /bin/bash --fork
走到这里,成功完成了PID的隔离,进行ps aux来观察启动的新进程和宿主机上的进程是否相同,但是此时PID尽然是相同的,没有发生隔离呢?
unshare -p /bin/bash --fork --mount
--pid 表示我们的进程隔离的是 pid,而其他命名空间没有隔离
mount-proc 是因为 Linux 下的每个进程都有一个对应的 /proc/PID 目录,该目录包含
了大量的有关当前进程的信息。 对一个 PID namespace 而言,/proc 目录只包含当前
namespace 和它所有子孙后代 namespace 里的进程的信息。创建一个新的 PID
namespace 后,如果想让子进程中的 top、ps 等依赖 /proc 文件系统的命令工作,还
需要挂载 /proc 文件系统。而文件系统隔离是 mount namespace 管理的,所以 linux
特意提供了一个选项--mount-proc 来解决这个问题。如果不带这个我们看到的进程还
是系统的进程信息