前言
c++ 我来了,恭喜牛牛解锁新世界.开启c++的学习之旅.

🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨
🐻推荐专栏: 🍔🍟🌯C语言进阶
🔑个人信条: 🌵知行合一
🍉本篇简介:>:讲解C++入门知识,命名空间的引入,C++中的输入输出,缺省参数的出现,函数重载等.
金句分享:
✨花会沿路盛开,你以后的路也是!✨
目录
- 前言
- 一、命名空间
- 1.1 " 命名空间"出现的原因:
- 1.2 "命名空间"的访问
- 1.3 "命名空间"中可以放什么?
- 1.4 "命名空间"的名称会冲突吗?
- 二、C++中的"输入"与"输出"
- 2.1 为啥C++中的头文件头文件有的没有`.h`?
- 2.2 学习新语言(C++)了,向世界问个好吧!
- 三、缺省参数
- 3.1 缺省参数的分类:
- 四、"关键字"表(资料)
- c语言"关键字":
- c++ "关键字"表:
一、命名空间
1.1 " 命名空间"出现的原因:
大家可以先看下面这一段代码:
#include <stdio.h>
int time = 0;int main()
{printf("%d", time + 66);return 0;
}
这代码可以正常运行,但是我们引用头文件#include <time.h>后,代码就不能正常运行了.
#include <time.h>
#include <stdio.h>
int time = 0;int main()
{printf("%d", time + 66);return 0;
}
原因是time变量在<time.h>中已经有定义了,所以这里就会报变量重命名错误.

不要以为我们只需要修改time变量,例如改为:time1就可以解决问题.
因为可能只是解决这一个当前问题,但是如果有一天,在某个工程中,包含某个头文件之后,代码就出现了一堆错误,那时候就有你头痛的时候了.

除此之外,往往一个大型的项目是由多个人即一个团队组合完成的,程序猿A和程序猿B可能会使用同一个名称去定义变量,这是难以预的.在C/C++中,变量、函数和C++中“类” 都是大量存在的,它们的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化(在本地范围内保持不重名,在外面重名无所谓,只要加上作用域限定符即可),以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的.
介绍" :: "域作用限定符
#include <stdio.h>int a = 10;int main()
{int a = 5;printf("a=%d\n", a); //1printf("a=%d\n", ::a); //2
}
结果:
5
10
在C语言中,如果局部和全局都定义了同一个变量,局部优先,所以1处打印5.
在C中如果不能屏蔽这个局部变量,还想优先访问全局域的10似乎很难办到,
而C++中,引入了域作用限定符,2处的a前面有" :: "域作用限定符,虽然是 空格+:: ,这里空格就代表全局域,所以这里打印10.
#include <iostream>
int main()
{int a = 5;//std是库里面的一个命名空间std::cout << a << std::endl;//cout函数后续会介绍return 0;
}
1.2 "命名空间"的访问
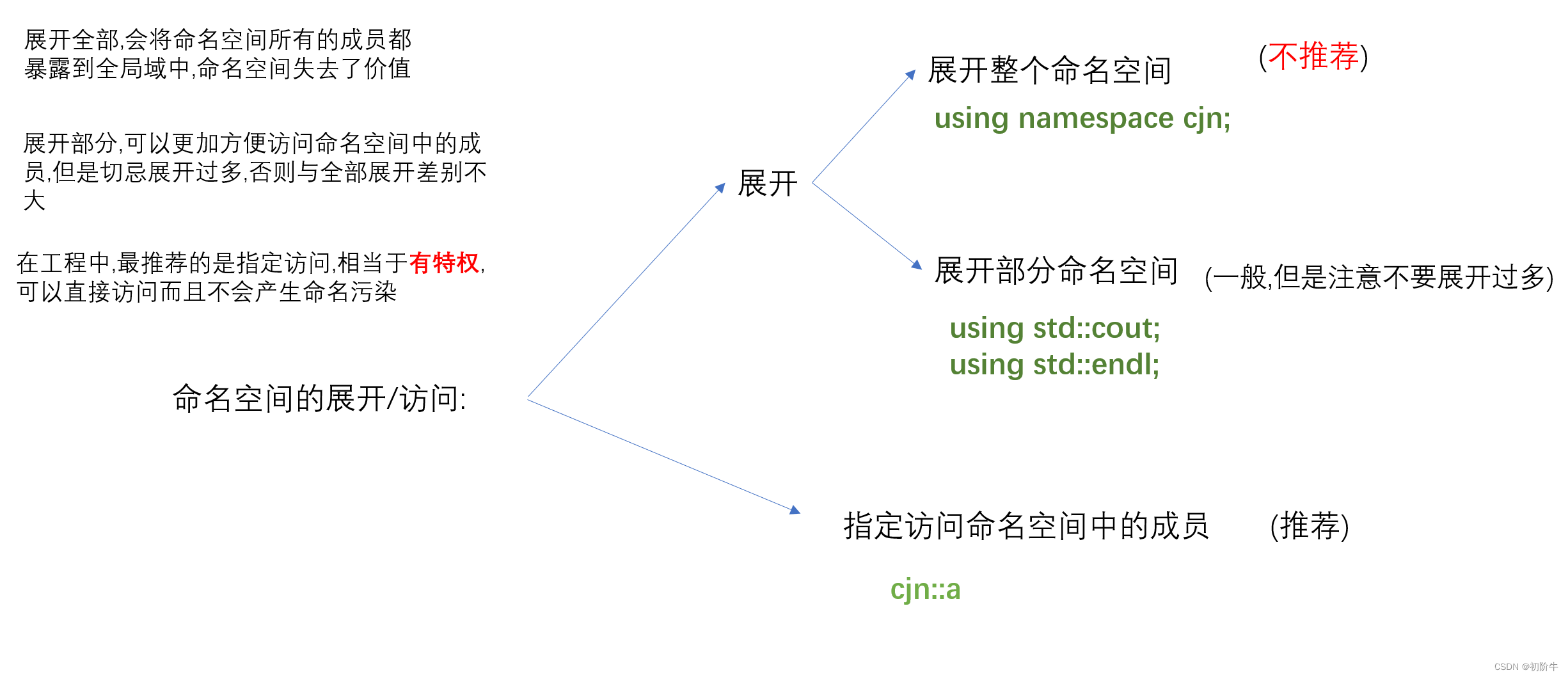
命名空间好似一堵墙,他将变量,函数等对象围了起来,防止与别处的污染,要想使用其中的变量,函数等内容有三种方法.
1.使用域作用限定符号:
命名空间的名字::+变量名
2.展开命名空间(将墙拆掉):
using namespace +命名空间的名字
3,展开命名空间的部分
using std::cout;
🌰栗子1:使用域作用限定符(指定空间访问):
//不推荐
#include <stdio.h>
namespace cjn
{int a = 66;
}
int main()
{printf("a=%d\n", cjn::a);
}
return 0;
🌰栗子2:将命名空间展开:(将墙拆掉)
//推荐
#include <stdio.h>
namespace cjn
{int a = 66;
}
using namespace cjn;//将命名空间展开
int main()
{printf("a=%d\n", a);return 0;
}
在写项目时,不适合使用第二种方法,因为将墙拆掉后,命名空间中的所有成员都暴露在全局域中,这样依旧会产生命名冲突.所以一般采用指定的命名空间域限定符来指定访问.
虽然不建议展开全部的命名空间,但是我们可以展开部分常用的,也很方便.
🌰栗子3:
#include <iostream>
//展开部分常用的
using std::cout;
using std::endl;
int main()
{int a = 0, b = 1;cout <<"abcdef" << " " << "a" << endl;cout << a << endl;cout << b << endl;return 0;
}
总结:
展示解决命名冲突问题:
#include <stdio.h>
int a = 10;
namespace cjn
{int a = 66;
}
//using namespace cjn;//将命名空间展开,不推荐
int main()
{int a = 5;printf("a1=%d\n", a);printf("a2=%d\n", ::a);//推荐printf("a3=%d\n", cjn::a);//推荐return 0;
}
注意:
如果命名空间未展开,编译器在默认情况下并不会搜索命名空间中的变量.(即如果在命名空间的定义的变量,不指定访问,编译器会找不到).
访问优先级:
优先级:局部域>全局域
小试牛刀:下面这段代码打印的结果是什么?
#include <stdio.h>
int a = 10;
namespace cjn
{int a = 66;
}
int main()
{int a = 5;printf("a=%d\n", a);return 0;
}

答案:
5
因为局部域优先,并且cjn命名空间没有展开编译器不会去里面搜索,所以也不会与全局变量冲突.
1.3 "命名空间"中可以放什么?
. 命名空间中可以定义很多东西,可以有函数,变量,结构体等,甚至可以嵌套其他命名空间等.
#include <iostream>
namespace cjn
{//定义函数void swap(int* e1, int* e2){int tmp = *e1;*e1 = *e2;*e2 = tmp;}//声明类型struct student{char name[10];int age;};//定义变量int time = 0;//嵌套定义命名空间namespace cjn2{int time = 2;int c=1;}}int main()
{//printf("%d", cjn::time + 66);std::cout << cjn::time + 66 << std::endl;return 0;
}
1.4 "命名空间"的名称会冲突吗?
命名空间是为了解决全局变量的命名冲突问题,那它自己的名字会被冲突吗?
🌰栗子1:同一个源文件中,定义相同名称的命名空间
#include <iostream>namespace cjn
{int a = 66;
}namespace cjn
{int b = 7;
}int main()
{std::cout << cjn::a <<" "<< cjn::b << std::endl;return 0;
}
🌰栗子2:同一个源文件中,定义相同名称的命名空间
#include <iostream>
//test1.cpp
namespace cjn
{int a = 66;
}
//test2.cpp
namespace cjn
{int b = 7;
}int main()
{std::cout << cjn::a <<" "<< cjn::b << std::endl;return 0;
}
运行:
66 7
答案是并不冲突的,对于在同一个文件或在不同文件中定义的同名命名空间,会被自动合并在一起.
总结:
-
命名空间是为了解决名称冲突而出现的,当然,也要学会合理使用命名空间,指定访问是更加推荐的这一种写法.
-
命名空间中可以定义很多东西,可以有函数,变量,结构体等,也可以嵌套其他命名空间等.
-
在不同文件中定义同一名称的命名空间不会报错,而是会被合并!
二、C++中的"输入"与"输出"
在讲上面的命名空间的时候,牛牛刚刚使用了cout函数,有没有友友好奇是怎么回事呢?
其实cin和cout是C++中的"输入"和"输出"函数.
使用时需要注意以下几点:
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)之前,需要包含头文件
< iostream >头文件,并且使用命名空间std。

cout和cin是全局的流对象,endl是特殊的C++符号,与C语言中的"\n"类似,表示换行,他们都包含在包含< iostream >头文件中。<<是流插入运算符,>>是流提取运算符。是一种很形象的"输入"和"输出"符号.- 很明显使用C++的
cin和cout更方便,不需要像c语言中的printf/scanf输入输出时使用格式输出符(%d,%c,%lf等等).cin和cout可以自动识别变量类型。 - 实际上
cout和cin分别是ostream和istream类型的对象.
2.1 为啥C++中的头文件头文件有的没有.h?
早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可.
后来C++中出现了命名空间的概念,就将实现方在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此推荐使用<iostream>+std的这种不带.h方式。
2.2 学习新语言(C++)了,向世界问个好吧!
#include <iostream>using namespace std;//使用std命名空间域,cin和cout在其中被定义int main()
{cout << "hello world" << endl;//endl代表换行return 0;
}
但是对于输出特定格式的内容,cin和cout就没有那么方便了,比如:输出一个浮点型数字,保留3位小数.
printf表示:(建议)
#include <stdio.h>
using namespace std;
int main(){float a=0;scanf("%f",&a);printf("%0.3f",a);
}
cout表示:(不建议)
#include <iostream>
#include <iomanip>
using namespace std;
int main(){float a;cin>>a;cout<<fixed<<setprecision(5)<<a;
}
这种情况建议使用printf,毕竟C++是兼容c的,可以混着用.😍
三、缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
缺省参数是舔狗或者可以说是备胎,如果有合适的人选(实参),则就会立马抛弃缺省参数,毫不犹豫选择实参,实在没有合适的人选(实参),才会没办法选择缺省参数.
🌰栗子
#include <iostream>
using std::cout;
using std::endl;
void fun(int a=3)
{cout << a << endl;
}
int main()
{fun(); //1fun(66); //2return 0;
}
运行结果:
3
66
1.调用函数时,并没有传参,则会采用缺省值(默认值)a=3.
2.调用函数时,实参传入了66,则采用实参.
还记得顺序表的初始化操作吗?
//顺序表的初始化操作
void InitSQL(SQL* SL)
{assert(SL);//防止传入空指针SL->capacity = MAX;SL->size = 0;//顺序表初始状态,当前数据量为0SL->data = (DataType*)malloc(sizeof(DataType) * MAX);//初始化顺序表大小if (SL->data == NULL){printf("初始化申请空间失败.\n");}
}
此时我们可以使用缺省参数将这个函数优化一下.
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef int DataType;typedef struct SQList
{DataType* data;//指向一段连续的内存空间int size;//代表当前顺序表的长度int capacity;//表示最大容量
}SQL;//优化后
void InitSQL(SQL* SL,int defaultsize=4)//这里设置了缺省参数
{assert(SL);//防止传入空指针SL->capacity = defaultsize;SL->size = 0;//顺序表初始状态,当前数据量为0SL->data = (DataType*)malloc(sizeof(DataType) * defaultsize);//初始化顺序表大小if (SL->data == NULL){printf("初始化申请空间失败.\n");}
}int main()
{SQL SL;//用顺序表类型创建一个SL顺序表InitSQL(&SL); //1//InitSQL(&SL,100); //2return 0;
}
这里我们就可以很灵活的设置顺序表的初始大小,如果我们确定这个顺序表至少要100大小的空间,我们可以采用方法2,直接传入实参过去.这样就减少了一次次扩容至100,更加方便高效.
如果不确定大小,这里不传参也没事,采用方法1,默认会设置为4大小的空间.
这种方式更加灵活,C语言中采用宏替换则没有这么灵活.
除此之外,缺省参数还有一些需要注意:
3.1 缺省参数的分类:
1.全缺省
2.半缺省
#include <iostream>
using std::cout;
using std::endl;void fun1(int a=1, int b=2, int c=3,int d=4)//全缺省
{cout << "fun1:" << endl;cout << a << endl;cout << b << endl;cout << c << endl;cout << d << endl << endl;
}void fun2(int a , int b , int c = 3, int d = 4)//半缺省
{cout << "fun2:" << endl;cout << a << endl;cout << b << endl;cout << c << endl;cout << d << endl;
}int main()
{fun1();fun2(6,7);return 0;
}
注意1:
半缺省值不是指一定非要缺省一半的参数,而是指缺省部分参数.
半缺省参数必须从右往左依次来给出,不能间隔着给.
传参是从左到右依次赋值,这点需要注意.这里需要理解,不是考记.
比如:如果赋值传参也是从右往左,则缺省的意义不大.

注意2:
缺省值必须是常量或者全局变量
注意3:
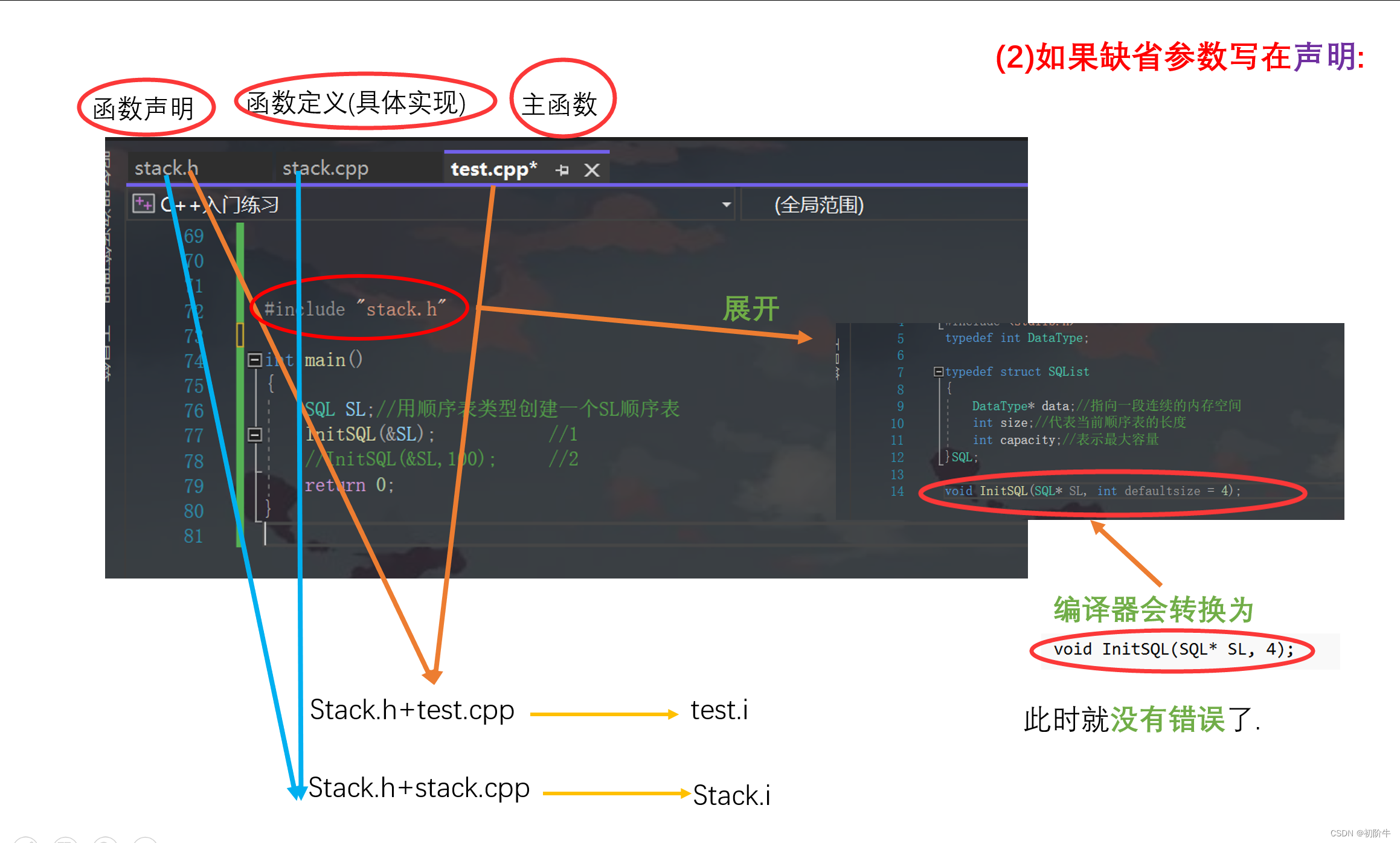
缺省参数,在函数的声明和定义不能同时给出,只能在声明中给出.
原因:
如果两个地方都给出缺省参数,则双方给的默认参数不同时,编译器不知道选择哪一个.
只有在声明给出缺省参数,是因为声明在.h文件中,而定义在另外一个.cpp文件中,
在编译阶段后,不同的.cpp文件会生成不同的目标文件.如果在定义处写则会出错,具体看下图.
(1)定义处写缺省参数:(报错)

(2)声明处写缺省参数:(正确写法)
在声明中给出缺省参数:
- 如果不传参,编译后会默认替换为默认值,
- 如果传参过去,则编译器会采用实参.
其中对于函数定义部分从始至终都是没有缺省值的,因为此处无论上面声明是何种情况,都会传足够的参数过来.
C++入门第一篇就讲到这里了,后续会讲解函数重载,引用、内联函数等.请保持持续关注哦!!!
如果文章对大家有用的话记得一键三连哦!💗💗💗
如果文章中有部分错误之处,可以私信牛牛,互相讨论哦!!!

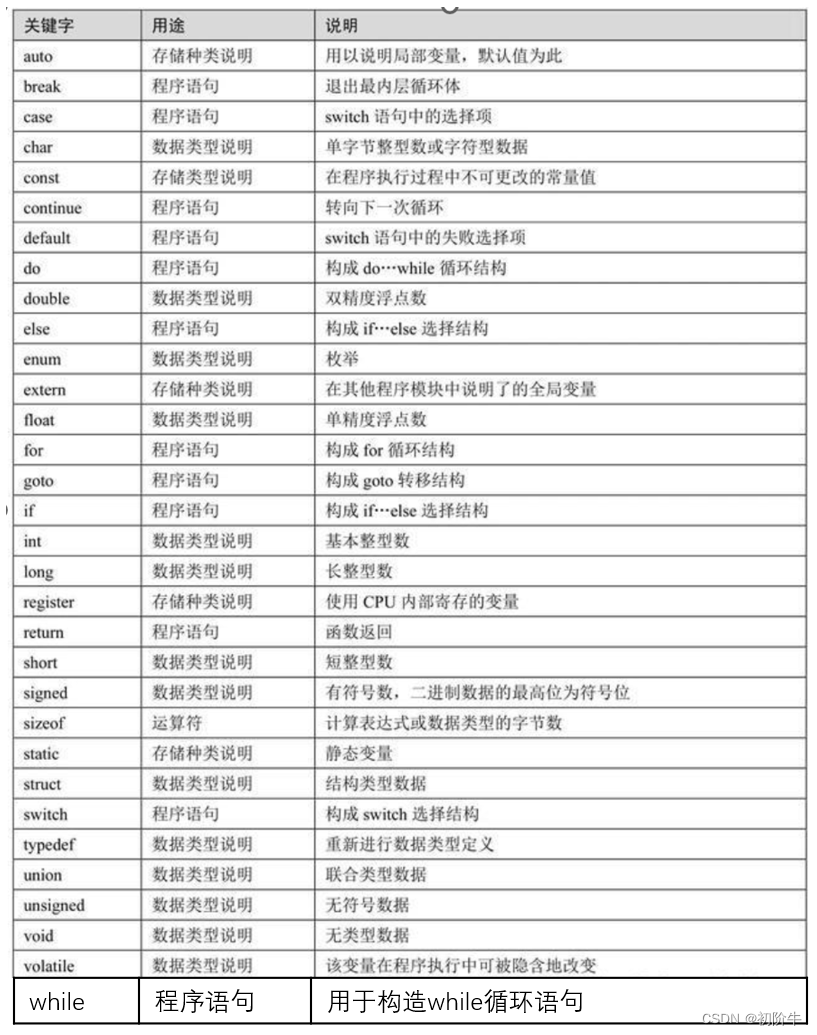
最后附上C语言和C++关键字的资料
四、"关键字"表(资料)
c语言"关键字":
(图片来源于:百度)
c++ "关键字"表: