目录
前言:
1 哈希
1.1 为什么有哈希
1.2 哈希结构
1.3 哈希冲突
2 闭散列
2.1 闭散列结点结构和位置状态表示
2.2 哈希类结构
2.3 插入
2.4 查找
2.5 删除
3 开散列
3.1 哈希表结点结构
3.2 哈希表结构
3.3 插入
3.4 查找、删除
3.5 迭代器实现
4 map和set的封装
4.1 map的封装
4.2 set的封装
5 开散列哈希完整代码
前言:
本篇介绍了两种哈希表的实现方式,一种是开散列、另一种是闭散列,通过闭散列实现的哈希表作为不排序map和set底层封装、实现。
注:本篇的算法逻辑比起前一篇AVL树、红黑树封装简单一些,但是对于类与类之间的联系更加复杂,所以博主希望小伙伴们在看到不明白的地方可以动手画一下传递关系,博主不确定所有的关键点都能讲到,谢谢大家咯。
1 哈希
1.1 为什么有哈希
想必大家在学习C++容器或则是其它语言时,会发现我们的库中不仅仅提供了map、set还有unordereded_map、unordered_set,然后大家会发现,这两类容器好像使用起来并没有什么很大的区别啊?甚至在极大的程度上来说,这两类容器非常的相似,使用起来唯一感受到的区别就是map迭代器输出是排序了的,unordered_map是没有排序的。
那么是大佬们闲得无聊,想要随便写一些东西加入STL库当中?很明显不是的,就用这两种容器的底层来说,map、set是通过红黑树或则是AVL树封装的,但是unordered_map,unordered_set是通过哈希结构封装的。
所以想要找它们之间的区别,不能局限于使用它们,而是要从底层结构出发才行。
我们知道无论是红黑树还是AVL树,因为它们要保证数据的存储顺序,所以每一次查找都要比较至少log2_N次,我们并不希望这样,我们希望的是每一次查找的效率都是直接能够找到对应的数据位置,直接拿到相应的位置数据。所以才有了哈希,才有了unordered_map和_set。
1.2 哈希结构
如我上方所述,哈希是一种结构,通过某种函数方式能够使元素的存储位置与它的关键码之间建立映射关系,可以不通过任何的比较,直接就能够从表中得到搜索的元素。
也就是我们根据插入元素的关键码,通过这个函数计算出该元素的存储位置,按照这个位置存储数据,因为这个关键码的信息是固定的,所以同样的,如果我们得到了一个关键码,直接可以通过映射找到结构当中的那个位置数据。
这种方式被称为哈希散列方法,这种方式中的函数转换称为哈希散列函数,构造出来的结构称为哈希散列表。
根据我所描述的哈希表,我想大家也能猜出来哈希表的结构大概是怎么样的了,那就是数组,因为只有数组才有随机访问的特点,也只有通过它来建立映射,才能满足我们的需求。
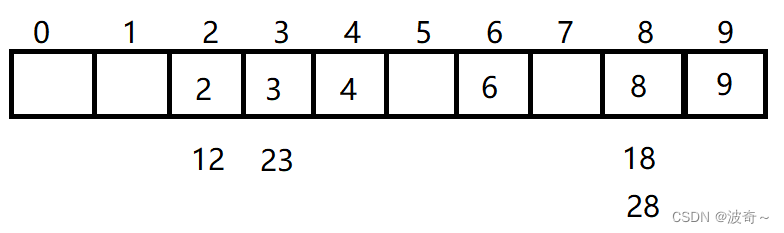
如下:我们的结构容量为10,需要存数据{2,3,4,6,8,9},通过取余的方式建立映射。

也就是当我们得到了一个key值,通过key % 容量大小,就能得到,2映射2位置,4映射4位置这样的插入数据方式。但是这样做有问题吗?有问题,那就是哈希冲突。
1.3 哈希冲突
我上方存储的数据故意避免了取余会得到相同的余数,可是这并不代表着以后我们随机插入的时候就能够避免,难道以后在使用的时候给别人说,你要注意不能插入余数相同的数据哦,不然这个结构就错误了。这种情况很明显是我们不希望出现的,但是这个问题又确实存在,如下,那么我们应该怎么解决呢?这也是我们之后讲解的重点,那就是闭散列和开散列。
2 闭散列
闭散列也可以叫做开放定址法,当插入数据出现哈希冲突的时候,如果哈希表还有容量时,那么这个插入的数据就会从冲突位置开始,向后查找空余位置。
这个向后查找空位置的方式可以是线性探测,也可以是二次线性探测,当然对于我来说这两种方式并没有什么本质上面的区别,反正都是往后查找空位置,然后插入数据。
也就是如下图所示:

不过,这个方式有很大的弊端,大家有看出来吗?那就是我的12占用了5号映射位置,那么如果下次插入了一个5时,5号位置有数据了,那么之后向后找另外的空位置,也就是7号位置。不过这样必定会导致整个结构的映射紊乱,也就是我们常说的踩踏问题。
不过没有办法解决,无论是通过线性探测还是二次线性探测都差不多,只不过是影响的位置不一样罢了。所以博主不喜欢这个方式,不过鉴于学习的缘故,博主还是会为大家分享的。
2.1 闭散列结点结构和位置状态表示
//每个位置的状态,空、存在、删除
enum State
{EMPTY = 0,EXIST = 1,DELETE = 2
};//哈希的结构,并不打算用闭散列方式实现unordered_map\set,直接实现KV结构
template<class K, class V>
struct HashElement
{pair<K, V> _data;State _state;//有参构造,初始状态设置为空,数据根据用户自己传的设置HashElement(const pair<K, V>& data = make_pair(K(),V())):_data(data),_state(EMPTY){}
};闭散列每个位置存的并不只是一个简单的数据,而是他有一个结点。里面分别是它的结点状态和数据,只不过这个数据是pair结构,这里博主故意实现的map版本,因为map的结构相对来说比set要复杂一点点。
注意到,博主的结点状态分为了三类,分别是空,存在,删除,这三个状态,可能有的小伙伴认为只用空和存在就能表示了,但是事实是这样吗?博主暂时不揭密,后面讲解。
2.2 哈希类结构
template<class K, class V>
class HashTable
{typedef typename HashElement<K, V> Element;
private://结构通过vector容器辅助实现,需要支持随机访问的特点vector<Element> _ht;size_t _size;
};class getKey
{
public:size_t operator()(const K& key){return key;}
};大家看到这个相信也是很容易理解的了,既然有容器帮助我们实现哈希表,那我们也不费那个力气去再写一遍vector了,我们的vector的每一个位置保存的是之前定义的哈希结点,_size用于表示我们已经插入了多少个位置了。可能有的朋友有一点疑问,vector不是会为我们记录结点个数吗?我们自己再记录它干嘛?同样的我在后面为大家揭秘。
在这个类当中添加一个仿函数,这个本身就是key返回key,没什么特别的意义,但是如果,只是我为了和我之后的开散列实现封装做一个对齐过程,大家现在看到就好了。
2.3 插入
对于插入来说,相信对于大家来说是没有什么太大的难度的,但是呢,这其中有部分的疑问我需要为大家解释以下,首先,相信大家也看到了,我们的闭散列是一个空间,那么我们不断地插入不会导致一个插满地问题吗?
我的答案是一定不会,因为我会主动地控制它,不会让有容量满地情况的,这其中的奥妙就在_size和vector里面的size之间的区别。
我们的_size表示现在的哈希表有多少个数据,vector里面的size表示这个表一共能插入多少个数据,别忘了,我们的插入方式是通过除留余数法,那么余什么?余的不就是这个大小吗,难道插入一个数据改一次size?然后每次都调整整个哈希表?这不玩嘛。
那么我们应该怎么控制呢?我通过查阅资料发现,当我们控制插入的数据个数与容量之比为0.7~0.8这个范围内比较号,因为低了会造成空间的浪费,再高就会导致冲突的机会变得非常的高,这很明显是不行的。所以根据这样的理论我们能够写出如下的代码:
bool insert(const pair<K, V>& kv)
{getKey gk;size_t hashi = gk(kv.first) % _ht.size();size_t index = hashi;size_t i = 1;//寻找空余位置while (_ht[index]._state == EXIST){//相同值,不允许再次插入if (_ht[index]._data.first == kv.first)return false;index = hashi + i;index %= _ht.size();i++;}//找到了没有冲突的位置,插入_ht[index]._data = kv;_ht[index]._state = EXIST;++_size;return true;
}但是这个插入总感觉看上去有点奇怪是不是?为什么呢?当然是因为博主连容量的控制都没有写哇,我们直接访问vector位置,这样写不崩死。
但是对于扩容来说,我们不仅要遵守0.7~0.8的负载力度,还应该做什么事情呢?记住,我们的映射关系是通过容量来计算的,那么容量变化之后,我们原来的映射关系正确嘛?不正确了,所以这个时候只能整体的调整了,这是没有办法的事情。
并且,这当中还有一件事情,我们可以直接在当前的vector上面扩容吗?不可以的,因为扩容之后,你想一下我们怎么调整位置呢?所以只能另外开一个vector,然后把数据映射过去,最后交换两个vector。
基于上面的所有理论,我们才能写入如下正确的插入方式:
bool insert(const pair<K, V>& kv)
{//当vector没有数据,则表示只有会有除0风险,当插入的数据个数已经占了70%以上,那么就需要扩容了if (_ht.size() == 0 || (_size * 10) / _ht.size() >= 7){//判断是第一次插入还是多次插入了size_t capacity = _ht.size() == 0 ? 10 : _ht.size() * 2;//扩容之后,数据映射关系会出现问题,那么这个时候就需要重新映射,//但是因为这个vector里面已经有了数据,//无法重新映射那么只能通过重复插入这个过程HashTable<K, V> NewTable;NewTable._ht.resize(capacity);for (size_t i = 0; i < _ht.size(); ++i){//只有当前的数据存在,才会插入数据if (_ht[i]._state == EXIST){//通过新的哈希表调用插入操作,复用不用扩容的插入部分内容NewTable.insert(_ht[i]._data);}}//交换两个哈希表,让原来哈希表通过NewTable释放_ht.swap(NewTable._ht);}//已经没有了扩容问题,正常的插入getKey gk;size_t hashi = gk(kv.first) % _ht.size();size_t index = hashi;size_t i = 1;//寻找空余位置while (_ht[index]._state == EXIST){//相同值,不允许再次插入if (_ht[index]._data.first == kv.first)return false;index = hashi + i;index %= _ht.size();i++;}上面扩容代码当中我运用了一个很巧妙的映射方式,那就是我通过复用插入函数的插入部分,因为我确定扩容之后这个表不会满,所以不会进入扩容部分,只能执行插入部分函数,以次来复用代码,当然将插入部分函数,在封装成单独的函数也能够实现,不过博主这样也挺好的。
2.4 查找
对于查找就不需要博主多说了吧,计算位置,然后向后查找。
//查找
int find(const K& key)
{getKey gk;size_t index = gk(key) % _ht.size();size_t hashi = index;size_t i = 1;while (_ht[index]._data.first != key && _ht[index]._state != EMPTY){index = hashi + i;index = index %= _ht.size();++i;if(index == hashi)return -1;}return index;
}当然其中有一个小问题,那就是如果我们插入一个数据然后删除一个数据,最后导致了每一个位置的状态都是删除,但是我们的找到是通过非空判断的,这是否会导致一个无限循环的问题呢?这样确实会导致无限循环,但是我们为什么要让他无限循环,只要找一遍不就够了。所以才看到我们的index == hashi就会返回-1。
2.5 删除
//删除
bool erase(const K& key)
{int res = find(key);if (res == -1)return false;size_t index = res;_ht[index]._state = DELETE;return true;
}复用查找函数,如果没有找到返回错误,找到就将那个位置的状态设置为DELETE,也就是删除状态,这里想必大家也知道了为什么我们要设置三个状态了,如果我们只有两个状态,那么删除之后一定是置空,但是对于查找函数呢?别忘了,我们的查找逻辑可是遇到空就会停止查找的,我们能确定这个空后面没有数据了嘛?不能,所以这才是博主设置三个状态的原因。
3 开散列
对于闭散列来说,博主想要讲解的就上面这一部分,相信大家无论是通过对代码分析,还是原理分析都认为这并不是一个很好的方式,因为这个踩踏的问题实在是太让人受不了了,反正博主是受不了,既然你有自己的位置,为什么要去占别人的位置?导致别人的位置没了又要去抢另一个人的位置,这不是恶性循环嘛,所以才有了开散列的概念。算出你的位置,那你就在这个位置上,这个位置上有人了,那你和它站在一起,反正你不能去抢别人的位置。
那么通过上面的结构描述,我们也能想到开散列是怎么样的:
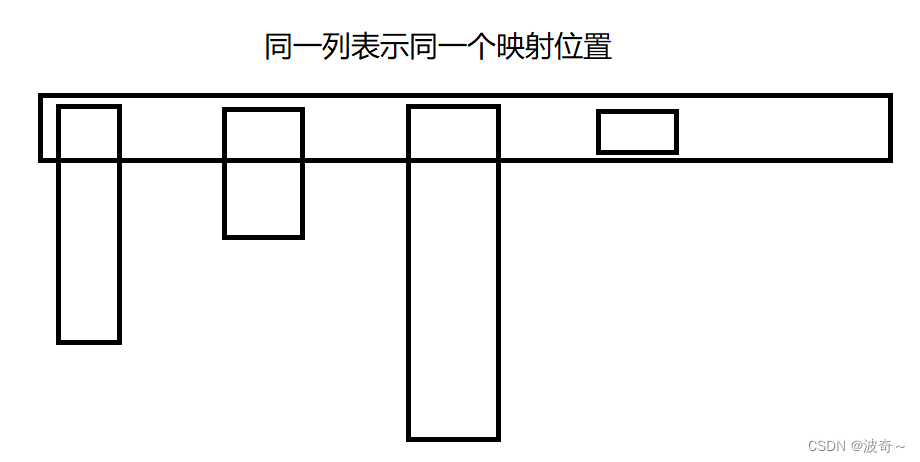
博主也懒得插入数据了,这个结构也足够了,也就是vector和链表的结合。当计算出一个数据的映射为2,插入2位置,下一个数据的映射也是2,还是插入2位置,通过链表头插方式将他们连接起来即可。
3.1 哈希表结点结构
对于开散列的结点来说,和单向链表一致,一个指针域和一个数据域:
//哈希结点
template<class T>
struct HashNode
{HashNode<T>* _next;T _data;HashNode<T>(const T& data):_data(data){}
};3.2 哈希表结构
template<class K, class T, class KeyOfT,class Hash>
class HashTable2
{template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend class __HashIterator;typedef HashNode<T> Node;
public:typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;typedef __HashIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;private://vector存结点指针,结点指针通过链表挂接vector<Node*> _ht;size_t _size;KeyOfT _kot;Hash hash;
};因为这个哈希表博主要将他变为map和set共同的底层结构,所以它的模板构造方式,我使用了和红黑树封装的同种方式,T参数可以是key也可以是一个pair结构,这并不确定。所以KeyOfT参数的作用就是为了获取不同结构下的key值。所以它应该是一个仿函数。因为虽然对于我们来说它是不确定的,但是对于map和set来说,它是确定的,这样就能保证之后传参的正确性。
后面的hash参数表示我们的哈希转换映射关系的方式,毕竟我们的传参并不一定是整型咯,具体的后面博主再讲。
其中的_ht和_size我相信大家看了闭散列大家也是能明白它是什么的,所以博主也不过多的讲解,没意思。
3.3 插入
pair<iterator,bool> insert(const T& data)
{//插入时,结点需要有空间,顺序表本身也需要有空间,那么就涉及到正常插入和扩容//扩容//调整的容量因素设置为插入个数和顺序表大小相等就调整if (_ht.size() == 0 || (_size * 10) / _ht.size() >= 10){//两倍扩容规则size_t newCapacity = _ht.size() == 0 ? 10 : _ht.size() * 2;//由于更改顺序表大小之后,映射关系出现错误,但是不能在原来的空间调整,需要另外开一个空间vector<Node*> newht(newCapacity);//无法做到和闭散列一样,复用下方代码,因为结点的开辟和释放需要消耗空间和时间for (Node* cur : _ht){while (cur != nullptr){Node* next = cur->_next;size_t index = hash(_kot(cur->_data)) % newht.size();cur->_next = newht[index];newht[index] = cur;cur = next;}}//交换两个vector的数据,更新_ht.swap(newht);}iterator it = find(_kot(data));if (it != end()){return make_pair(it, false);}//正常插入//通过头插的方式插入,更加的节省时间,只需要替换vector位置指针并连接即可size_t hashi = hash(_kot(data)) % _ht.size();Node* cur = new Node(data);cur->_next = _ht[hashi];_ht[hashi] = cur;_size++;return make_pair(iterator(cur, this), true);
}对于闭散列的插入来说很简单,它只需要通过hash仿函数计算出自己的key值映射关系,然后头插那个位置的结点。如果空间不够就需要通过扩容来解决问题,但是同样的我们还是不能原地扩容,需要另外开辟一个载体,和闭散列一样,但是对于开散列来说,它的负载可以超过vector的size大小,因为他只要结点映射的是相同位置,那么永远都只会占据一个位置,这一点我不过多的解释。
对于开散列来说,它不能做到和vector一样,直接把那个位置的结点丢了,因为他保存的是结点的指针,vector可不会帮我们释放,所以如果复用插入部分代码会出现内存泄漏的问题,对于我们来说是灾难,这不可行,但是每次都释放结点内存又太耗时间了,所以咱们就直接用原来的结点了,因为对于结点来说,他只是一个保存数据的载体,他是谁,它的地址是什么,对我们都没有任何的意义。
3.4 查找、删除
代码带简单了,博主不想做解释。
iterator find(const K& key)
{size_t hashi = hash(key) % _ht.size();Node* cur = _ht[hashi];while (cur && _kot(cur->_data) != key){cur = cur->_next;}if (cur == nullptr)return iterator(nullptr, this);return iterator(cur, this);
}//删除
bool erase(const K& key)
{//因为计算方式通过hash,所以查找也需要通过这种方式size_t hashi = hash(key) % _ht.size();Node* prev = nullptr;Node* cur = _ht[hashi];//如果当前位置存在结点,并且这个key值不是,那就向后查找while (cur && _kot(cur->_data) != key){cur = cur->_next;}//没有找到数据,返回错误if (cur == nullptr)return false;if (prev == nullptr){_ht[hashi] = cur->_next;delete cur;}else{prev->_next = cur->_next;delete cur;}
}3.5 迭代器实现
对于开散列的哈希表来说,它的迭代器是一个只支持往前走的这样一个形式,并且这个迭代器当中不仅仅要有这个当前位置的结点指针用于访问数据,还需要有这个结点的哈希表,否则无法走下去,因为一个链走完之后是空,需要借助哈希表找到下一个位置才行。
又因为我们要在迭代器当中访问哈希表的私有属性,所以需要将这个迭代器作为哈希表的友元类才能访问到。
//哈希表的迭代器
template<class K, class T,class Ref, class Ptr,class KeyOfT, class Hash>
class __HashIterator
{typedef HashNode<T> Node;typedef HashTable2<K, T, KeyOfT, Hash> HT;typedef __HashIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;public:__HashIterator(Node* node, const HT* ht):_node(node), _tableptr(ht){}__HashIterator(const iterator& it):_node(it._node), _tableptr(it._tableptr) {}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}Self& operator++(){//如果当前迭代器已经走到了空,直接返回if (_node == nullptr)return *this;Node* cur = _node;cur = cur->_next;if (cur == nullptr){//找到下一个哈希桶Hash hash;KeyOfT kot;size_t hashi = hash(kot(_node->_data)) % _tableptr->_ht.size();++hashi;while (_tableptr->_ht[hashi] == nullptr){++hashi;if (hashi == _tableptr->_ht.size()){_node = nullptr;return *this;}}cur = _tableptr->_ht[hashi];_node = cur;}return *this;}//存当前迭代器的指针还有一张哈希表用于遍历Node* _node;const HT* _tableptr;
};4 map和set的封装
博主不打算讲这一部分,并不是他简单,相反他还挺复杂的,但是博主的上篇已经详细讲解过了,所以博主内心很抗拒再写一遍,所以这里只做分享,原谅博主咯。
map和set封装
4.1 map的封装
template<class K, class V>
class MyMap
{
public:class MapKeyOfT{public:const K& operator()(const pair<K, V>& data){return data.first;}};typedef typename HashTable2<K, pair<const K, V>, MapKeyOfT, Hash<K>>::iterator iterator;typedef typename HashTable2<K, pair<const K, V>, MapKeyOfT, Hash<K>>::const_iterator const_iterator;iterator begin(){return _t.begin();}iterator end(){return _t.end();}const_iterator begin() const{return _t.begin();}const_iterator end() const{return _t.end();}pair<iterator, bool> insert(const pair<const K, V>& data){return _t.insert(data);}bool erase(const K& key){return _t.erase(key);}iterator find(const K& key){return _t.find();}V& operator[](const K& key){iterator res = _t.insert(make_pair(key, V())).first;return (*res).second;}vector<int> getCnt(){return _t.get_link_cnt();}private:HashTable2<K, pair<const K, V>, MapKeyOfT, Hash<K>> _t;};4.2 set的封装
template<class K>
class MySet
{
public:class SetKeyofT{public:const K& operator()(const K& key){return key;}};typedef typename HashTable2<K, K, SetKeyofT, Hash<K>>::const_iterator iterator;typedef typename HashTable2<K, K, SetKeyofT, Hash<K>>::const_iterator const_iterator;iterator begin() const{return _t.begin();}iterator end() const{return _t.end();}pair<iterator,bool> insert(const K& key){return _t.insert(key);}bool erase(const K& key){return _t.erase(key);}iterator find(const K& key){return _t.find();}
private:HashTable2<K, K, SetKeyofT, Hash<K>> _t;
};5 开散列哈希完整代码
#pragma once#include<iostream>
#include<vector>using namespace std;//哈希表,开散列实现//哈希结点
template<class T>
struct HashNode
{HashNode<T>* _next;T _data;HashNode<T>(const T& data):_data(data){}
};template<class K>
class Hash
{
public:size_t operator()(const K& key){return key;}
};template<>
class Hash<string>
{
public:size_t operator()(const string& key){size_t res = 0;for (auto val : key){res = res * 31 + val;}return res;}
};template<class K, class T, class KeyOfT, class Hash>
class HashTable2;//哈希表的迭代器
template<class K, class T,class Ref, class Ptr,class KeyOfT, class Hash>
class __HashIterator
{typedef HashNode<T> Node;typedef HashTable2<K, T, KeyOfT, Hash> HT;typedef __HashIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;public:__HashIterator(Node* node, const HT* ht):_node(node), _tableptr(ht){}__HashIterator(const iterator& it):_node(it._node), _tableptr(it._tableptr) {}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}Self& operator++(){//如果当前迭代器已经走到了空,直接返回if (_node == nullptr)return *this;Node* cur = _node;cur = cur->_next;if (cur == nullptr){//找到下一个哈希桶Hash hash;KeyOfT kot;size_t hashi = hash(kot(_node->_data)) % _tableptr->_ht.size();++hashi;while (_tableptr->_ht[hashi] == nullptr){++hashi;if (hashi == _tableptr->_ht.size()){_node = nullptr;return *this;}}cur = _tableptr->_ht[hashi];_node = cur;}return *this;}//存当前迭代器的指针还有一张哈希表用于遍历Node* _node;const HT* _tableptr;
};template<class K, class T, class KeyOfT,class Hash>
class HashTable2
{template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend class __HashIterator;typedef HashNode<T> Node;
public:typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;typedef __HashIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;Node* LeftMost() const{for (auto e : _ht){if (e != nullptr) return e;}return nullptr;}iterator begin(){return iterator(LeftMost(),this);}iterator end(){return iterator(nullptr, this);}const_iterator begin() const{return const_iterator(LeftMost(), this);}const_iterator end() const{return iterator(nullptr, this);}HashTable2():_size(0){}pair<iterator,bool> insert(const T& data){//插入时,结点需要有空间,顺序表本身也需要有空间,那么就涉及到正常插入和扩容//扩容//调整的容量因素设置为插入个数和顺序表大小相等就调整if (_ht.size() == 0 || (_size * 10) / _ht.size() >= 10){//两倍扩容规则size_t newCapacity = _ht.size() == 0 ? 10 : _ht.size() * 2;//由于更改顺序表大小之后,映射关系出现错误,但是不能在原来的空间调整,需要另外开一个空间vector<Node*> newht(newCapacity);//无法做到和闭散列一样,复用下方代码,因为结点的开辟和释放需要消耗空间和时间for (Node* cur : _ht){while (cur != nullptr){Node* next = cur->_next;size_t index = hash(_kot(cur->_data)) % newht.size();cur->_next = newht[index];newht[index] = cur;cur = next;}}//交换两个vector的数据,更新_ht.swap(newht);}iterator it = find(_kot(data));if (it != end()){return make_pair(it, false);}//正常插入//通过头插的方式插入,更加的节省时间,只需要替换vector位置指针并连接即可size_t hashi = hash(_kot(data)) % _ht.size();Node* cur = new Node(data);cur->_next = _ht[hashi];_ht[hashi] = cur;_size++;return make_pair(iterator(cur, this), true);}//计算每个桶的连接数vector<int> get_link_cnt(){vector<int> result;int cnt = 0;for (Node* cur : _ht){while (cur){cnt++;cur = cur->_next;}result.push_back(cnt);cnt = 0;}return result;}iterator find(const K& key){size_t hashi = hash(key) % _ht.size();Node* cur = _ht[hashi];while (cur && _kot(cur->_data) != key){cur = cur->_next;}if (cur == nullptr)return iterator(nullptr, this);return iterator(cur, this);}//删除bool erase(const K& key){//因为计算方式通过hash,所以查找也需要通过这种方式size_t hashi = hash(key) % _ht.size();Node* prev = nullptr;Node* cur = _ht[hashi];//如果当前位置存在结点,并且这个key值不是,那就向后查找while (cur && _kot(cur->_data) != key){cur = cur->_next;}//没有找到数据,返回错误if (cur == nullptr)return false;if (prev == nullptr){_ht[hashi] = cur->_next;delete cur;}else{prev->_next = cur->_next;delete cur;}}private://vector存结点指针,结点指针通过链表挂接vector<Node*> _ht;size_t _size;KeyOfT _kot;Hash hash;
};以上就是博主想要分享的全部内容了,谢谢大家观看。