WeDataSphere组件容器化部署文档
WeDataSphere是微众银行的大数据开发平台。目前为让用户能够快速体验WeDataSphere所有组件,我们提供一个使用Docker构建的镜像包,里面包括基础组件Hadoop, Spark, Hive, Flink, MySQL。WeDataSphere的组件有DSS,Linkis,Schedulis, Qualitis, Visualis, Exchangis。您只需要准备一台内存大小为32G,磁盘100G的机器,系统推荐使用CentOS或Red Hat,不推荐Ubuntu。按照如下步骤操作就能够在半小时内完成所有服务的部署与使用。
参考文章
WeDataSphere/Docker版本部署指南.md at wds-hadoop2.7.2 · WeBankFinTech/WeDataSphere · GitHub
【必看,官方公众号文章】https://mp.weixin.qq.com/s/HL1UHHkisRiKAY0_5xTOxg
一、准备工作
-
需要准备一台内存大小最少为32G,磁盘大小约为100G的服务器,部署前请确保该服务器上无其他服务在运行,以避免端口冲突
-
将Docker安装在服务器
#1.下载docker依赖环境
yum -y install yum-utils device-mapper-persistent-datalvm2#2.设置docker镜像源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo #3.安装docker
yum makecache fast yum install docker-ce docker-ce-cli containerd.io
##上面的命令systemctl start docker 报错Failed to start docker.service: Unit not found.所以我是用了下面的命令。
yum install docker-ce docker-ce-cli containerd.io#4.启动docker服务
systemctl start docker #5.测试服务是否正常启动
docker run hello-world
docker的安装因网络环境的差异,上述步骤可能无法完全适配,用户可根据实际网络环境安装docker并保证docker可用
- 下载WeDataSphere容器化镜像包点我下载
镜像包较大,请在空闲时间下载
- 上传镜像包到服务器,或直接在服务器上下载
二、部署步骤
- 查看是否存在名称为wedatasphere的镜像,存在的话建议修改已有镜像的名称
docker images
- 在服务器上加载镜像包(预计需要五分钟左右)和查看是否加载成功
#加载镜像包
docker load -i wedatasphere.tar
#查看是否存在REPOSITORY名称为wedatasphere的镜像
docker images
- 将镜像运行在容器中 (请确保没有相同名称的container在运行)
docker run -itd --name='wedatasphere' --privileged -p 8085:8085 -p 8087:8087 -p 8083:8083 -p 9500:9500 -p 9400:9400 -p 8090:8090 -p 8080:8080 -p 50070:50070 -p 8088:8088 -p 9001:9001 wedatasphere init
- 进入容器
docker exec -it wedatasphere /bin/bash
- 在容器中切换到hadoop用户和切换目录到/data/docker下
su hadoop
cd /data/docker
- 执行脚本docker_start_all.sh,无报错的情况下就可以去登录DSS并使用
sh docker_start_all.sh
-
在页面登录的ip为所在服务器的ip,端口为8085,用户名和密码均为hadoop/hadoop
-
停止服务可执行docker_stop_all.sh脚本
sh docker_stop_all.sh
三、安装后的效果
- 安装的时候会提示输入ip
You can check all server by acessing eureka URL:http://ip:8087
本人的路径就是:http://192.168.19.142:8087/
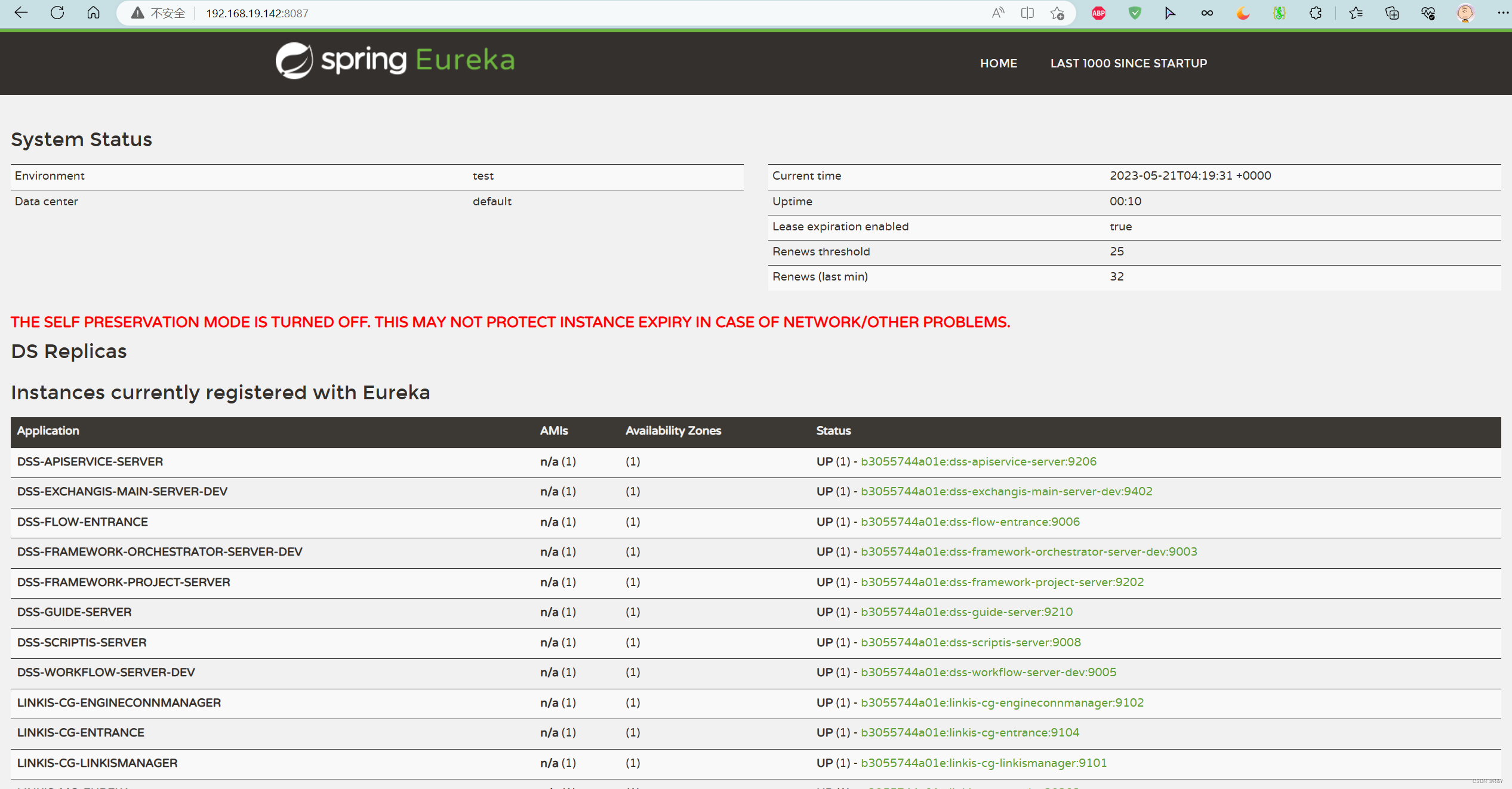
合计16个微服务,如下
【DSS的微服务】
DSS-APISERVICE-SERVER
DSS-EXCHANGIS-MAIN-SERVER-DEV
DSS-FLOW-ENTRANCE
DSS-FRAMEWORK-ORCHESTRATOR-SERVER-DEV
DSS-FRAMEWORK-PROJECT-SERVER
DSS-GUIDE-SERVER
DSS-SCRIPTIS-SERVER
DSS-WORKFLOW-SERVER-DEV
【LINKIS的微服务】
LINKIS-CG-ENGINECONNMANAGER
LINKIS-CG-ENTRANCE
LINKIS-CG-LINKISMANAGER
LINKIS-MG-EUREKA
LINKIS-MG-GATEWAY
LINKIS-PS-PUBLICSERVICE
STREAMIS-SERVER
VISUALIS-DEV
- 登录WDS
在页面登录的ip为所在服务器的ip,端口为8085,用户名和密码均为hadoop/hadoop
本人的路径就是:http://192.168.19.142:8085/#/login
四、Docker版本使用指南
本文档主要介绍在使用Docker镜像包启动WeDataSphere所有组件后该如何使用
需要注意,由于镜像中部署的Hadoop, Spark等基础组件均是单节点的,稳定性必然不高,因此Docker版本无法用于生产
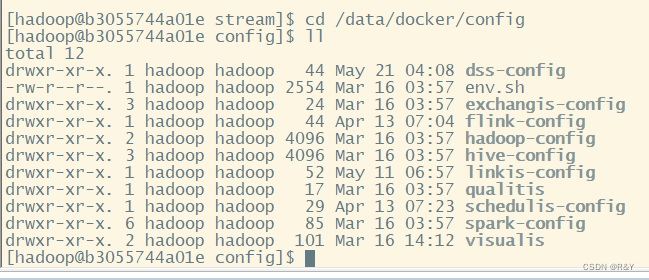
- 容器中各组件安装包均在/data/docker/Install目录下,除Streamis的配置文件在/data/docker/Install/streamis/streamis-server/conf目录,其他组件配置文件均在/data/docker/config目录下,日志均在/data/docker/logs目录,
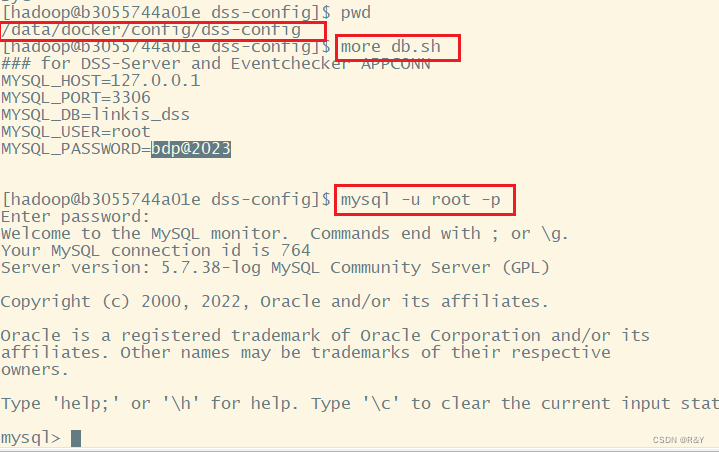
如何链接WDS的mysql数据库
MYSQL_HOST=127.0.0.1
MYSQL_PORT=3306
MYSQL_DB=linkis_dss
MYSQL_USER=root
MYSQL_PASSWORD=bdp@2023 所以输入 mysql -u root -p
如何链接WDS的hive查看HDSF数据输入beeline。输入hive会报错
- Linkis和Visualis的前端包分别在目录/data/docker/Install/web/dss/linkis和/data/docker/Install/web/dss/visualis;DSS前端包在/data/docker/Install/web/dist;Schedulis前端包在/data/docker/Install/schedulis/schedulis-web/;Qualitis前端包在目录/data/docker/config/qualitis/dev/static;Exchangis前端包在目录/data/docker/Install/exchangis/frontend;Streamis前端包在/data/docker/Install/streamis/streamis-server/frontend
- 镜像中提供了两个简单Demo项目TestDemoDocker和TestStreamis,用户登录后选择首页在默认工作空间bdapWorkspace下能够看到
- 项目TestDemoDocker中有工作流TestDemo,该工作流主要包含DataSphereStudio中常用的节点,您可以选择执行并查看执行结果,并且可以将该工作流发布到调度中心,再从左侧菜单栏进入Schedulis调度中心,查看发布过去的工作流,对其进行调度
- 项目TestStreamis是流式生产中心的Demo,您打开项目后需要在从开发中心切换到流式生产中心,启动作业名称为flink-cdc的作业。该作业的功能是读取数据库streamis_test中表streamis_source_table的binlog信息,写到表streamis_sink_table中
- 除已有的两个项目外,您也可以选择自己创建项目和工作流,进行简单测试和演示,但是需要主要的是由于基础引擎对资源要求较高,若部署镜像的机器可用内存只有32G,执行复杂的任务会出现OOM异常