数据准备
可以通过以下链接获取数据集:
百度网盘 请输入提取码
共包含三个csv文件:
《train.csv》训练数据集,包含特征信息和标签(是否幸存)
《test.csv》 测试数据集, 只包含特征信息
《gender_submission.csv》测试数据集的标签(是否幸存)
数据集各列含义如下:
- PassengerId :ID
- Pclass :舱位等级(分为1/2/3等)
- Name : 姓名
- Sex : 性别
- Age : 年龄
- SibSp : 堂兄弟/妹个数
- Parch : 父母/小孩个数
- Ticket : 船票信息
- Fare :票价
- Cabin : 客舱位置
- Embarked : 登船港口
实验思路
数据处理——特征选择——模型构建——预测分析——可视化
1、导入数据集
import pandas as pd# 首先导入数据
train = pd.read_csv("train.csv")
test_x = pd.read_csv("test.csv")
test_y = pd.read_csv("gender_submission.csv")print(train.info()) # 打印数据,查看是否有缺失值
我们需要使用train来训练模型,使用test_x和test_y来测试模型的效果
然后可以通过info方法来查看数据结构信息:

可以看到,一共有891条数据,其中属性Age、Cabin、Embarked是有空白值的,因此我们需要对这些空白值进行处理;
2、缺省值处理
在进行缺省值处理的时候,我们首先需要确定要用哪些特征来构建决策树;
通过直观感受可以判断,生存概率应该与年龄、性别、船舱位置有关
其余的特征好像无法与生存概率有较为直观的联系
接下来,通过上面数据结构的分析,年龄和船舱位置都有部分空白值,尤其是船舱位置,有着大面积的空白
所以我们需要想办法对这些缺省值进行处理(删除/填充)

通过上图对于Cabin这一列数据的分析,可以看到,Cabin的值没有分布规律,且信息缺失尤其严重,不易处理,因此我们选择放弃这一属性;而对于Age属性,可以选择使用中位数或者平均数进行填充:
# 填充缺失值 # Cabin信息缺失太严重,不作为特征,因此不填充 # Age需要作为特征值,采用平均值进行填充 train.Age.fillna(train.Age.mean(),inplace=True) test_x.Age.fillna(test_x.Age.mean(),inplace=True)# 使用mean()方法计算均值;如需使用中位数,可以使用median()方法
数据填充使用fillna()方法,具体用法:fillna(填充值,inplace=True)
其中inplace=True表示直接修改原始数据框,如果为False则不修改原始数据框,而是返回一个新的数据框;
对于fillna函数,还有以下多种用法,这里不再赘述:

3、特征选取
根据上面的分析,我们最终选取了Age和Sex作为特征;
但是Sex的值是分类变量,无法使用决策树进行处理,所以需要先转化为数字标签

具体的转化使用LabelEncoder()方法
LabelEncoder是sklearn中一种用于将分类变量转换为数字标签的工具。它可以将一个类别字符串(如“狗”、“猫”、“鸟”等)映射到一个整数标签(如0、1、2等),从而方便地进行数据处理和分析
from sklearn.preprocessing import LabelEncoder# 选取特征 # 选用 Sex Age 作为特征 # 将Sex进行编码处理:使用LabelEncoder将分类变量映射为数字标签 le=LabelEncoder() train['Sex']=le.fit_transform(train['Sex']) # 男性为1 女性为0 test_x['Sex'] = le.fit_transform(test_x['Sex'])
具体使用的是fit_transform()方法;该方法时fit()方法和transform()方法的组合,首先使用 fit() 方法将 LabelEncode 对象拟合到输入数据集中,得到一个转换矩阵。然后,使用 transform() 方法将该转换矩阵应用于输入数据集,得到转换后的结果
4、构建决策树
from sklearn.tree import DecisionTreeClassifier# 构建决策树 features = ['Sex','Age'] x_train = train[features] y_train = train['Survived'] x_test = test_x[features] y_test = test_y['Survived']clf = DecisionTreeClassifier(criterion='entropy',splitter='best')
使用DecisionTreeClassifier来构建决策树
相关参数设置可以参考官网:
sklearn.tree.DecisionTreeClassifier — scikit-learn 1.2.2 documentation
我在这里仅设置了criterion和splitter:
- criterion(分类器准测){“gini”, “entropy”, “log_loss”}, default=”gini”
这里选择entropy,通过计算信息增益来选取优先用于分类的属性;具体来说
- splitter{“best”, “random”}, default=”best”
用于在每个节点上选择分割的策略,这里选用best,在特征的所有划分点中找出最优的划分点
5、模型训练
clf.fit(x_train,y_train) # 训练模型clf.predict(x_test)score = clf.score(x_test,y_test) print(score)
最终的结果是
![]()
可以看到模型的准确率达到了86%左右
6、可视化
from sklearn.tree import export_graphvizwith open('Titanic.dot','w')as f:f=export_graphviz(clf,feature_names=['Sex','Age'],out_file=f)
将生成的决策树保存为.dot类型的文件
我们可以下载专门的graphviz软件来生成图片,下载链接如下:
Download | Graphviz
或者直接从百度网盘获取也可:
百度网盘 请输入提取码
最终生成的图片如下:
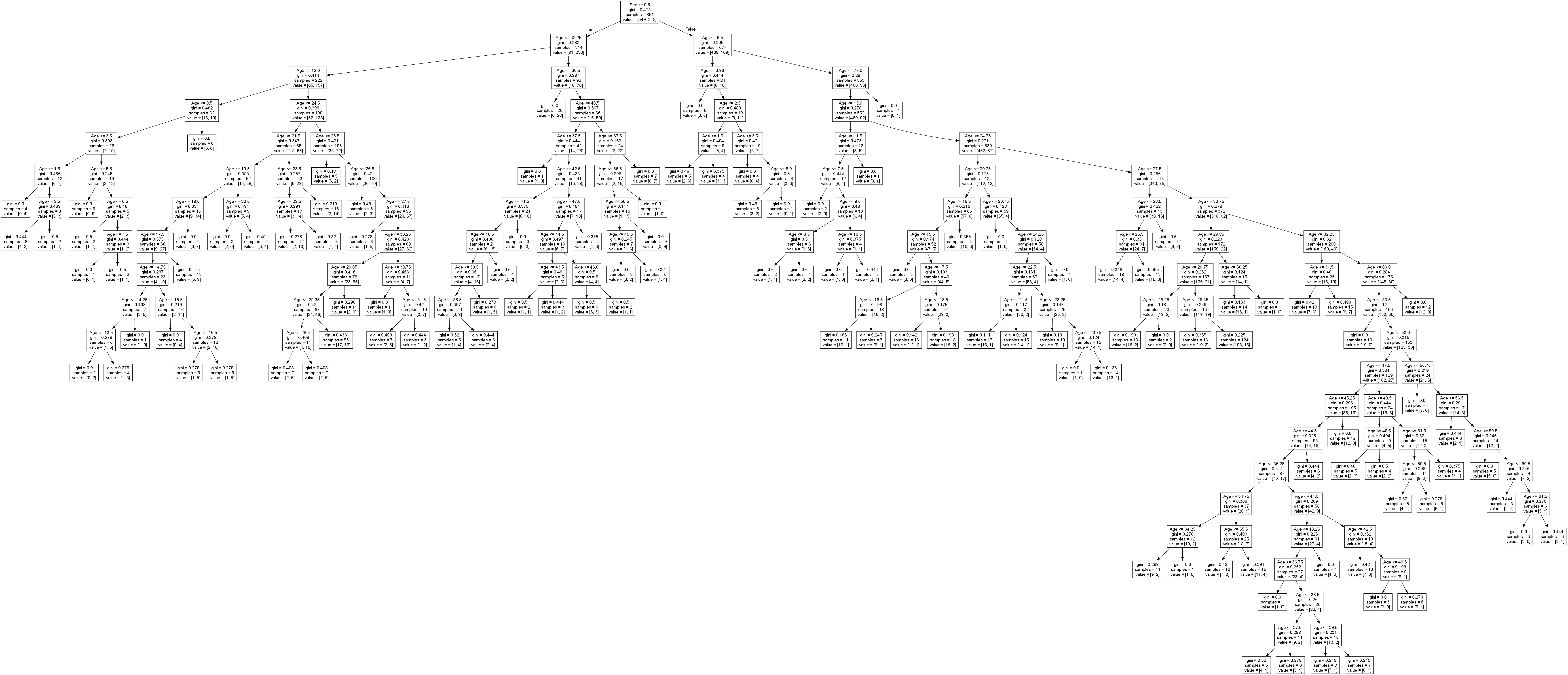
实验源码
最后将完整代码总结如下:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier,export_graphviz# 打印完整的train数据
def display_options():display = pd.options.displaydisplay.max_columns = 12display.max_rows = 5display.width = 1000
display_options()# 首先导入数据
train = pd.read_csv("train.csv")
test_x = pd.read_csv("test.csv")
test_y = pd.read_csv("gender_submission.csv")
print(train.info()) # 打印数据,查看是否有缺失值# 填充缺失值
# Cabin信息缺失太严重,不作为特征,因此不填充
# Age需要作为特征值,采用平均值进行填充
train.Age.fillna(train.Age.mean(),inplace=True)
test_x.Age.fillna(test_x.Age.mean(),inplace=True)# 选取特征
# 选用 Sex Age 作为特征
# 将Sex进行编码处理:使用LabelEncoder将分类变量映射为数字标签
le=LabelEncoder()
train['Sex']=le.fit_transform(train['Sex']) # 男性为1 女性为0
test_x['Sex'] = le.fit_transform(test_x['Sex'])# 构建决策树
features = ['Sex','Age']
x_train = train[features]
y_train = train['Survived']
x_test = test_x[features]
y_test = test_y['Survived']clf = DecisionTreeClassifier(criterion='entropy',splitter='best')
clf.fit(x_train,y_train) # 训练模型clf.predict(x_test)score = clf.score(x_test,y_test)
print(score)# # 决策树可视化
with open('Titanic.dot','w')as f:f=export_graphviz(clf,feature_names=['Sex','Age'],out_file=f)