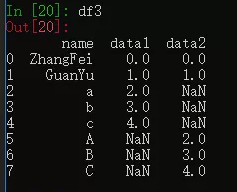
需要循环读取文件夹中的csv,创建dataframe
使用exec函数
rootPath""
excelNames os.listdir(rootPath)
for i in range(len(excelNames)):csvpathrootPath"\\"excelNames[i] exec(df{0} pd.read_csv(csvpath).format(i))
df2df
df2.loc[:,"id"]35
#随后发现df也被改变了import copya [1, 2, 3]
b a
# 把下面2行注释并运行会发现a,b改变数据后会影响彼此
b copy.deepcopy(a) #避免办法1:深拷贝,让b与a相互独立(值相同,但在内存中的ID不同…