项目一:
1.写出以下代码的输出结果:
代码如下:

2.写出以下代码的输出结果。
代码如下:

- 根据df创建透视表:
import pandas as pd
import numpy as np
df = pd.DataFrame({"Item":['Item0', 'Item0', 'Item1', 'Item1'],'CType':['Gold', 'Bronze', 'Gold', 'Silver'],'USD':[1,2,3,4],'EU': [1,2,3,4]})
print(df)
输出格式如下:
4.
根据题目要求完成如下操作:
(1)创建一个第五个值为0的1向量,长度为10.
(2)反转(1)中的数组
(3)数组中有1,2,3,4,5,6,7,8,9个数值,直接提取所有的奇数。
(4)将(3)中所有的奇数用-1替代。
项目二:
1.写出以下代码的输出结果
代码如下:

2.写出以下代码的输出结果,ABCDEFGHI处的结果
代码如下:
 项目三:利用字典 data 和列表 labels 完成以下操作。
项目三:利用字典 data 和列表 labels 完成以下操作。
已知:
from copy import deepcopy
import pandas as pd
import numpy as np
data = {'animal':['cat','cat','snake','dog','dog','cat','snake','cat','dog','dog'],\
'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],\
'visits':[1,3,2,3,2,3,1,1,2,1],\
'priority':['yes',np.nan,'no','yes','no','no','no','yes','no','no']}
labels = ['a','b','c','d','e','f','g','h','i','j']
1.创建 DataFrame 类型 df,输出格式如下:

2.输出 df 的前三行,并输出所有 visits 属性值大于 2 的所有行
输出格式如下:

3.输出age为缺失值所在的行,输出'age'与'animal'两列数据。
输出格式如下:

4.输出 animal==cat 且 age<3 的所有行,并将行为”f”,列为”age”的元素值修改为 1

(5)计算 animal 列一共出现几种动物

(6)将 animal 列中所有 snake 替换为 panda
(7)对 df 按列 animal 进行排序,并打印df

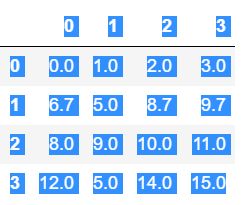
(8)在 df 的在后一列后添加一列列名为 No.数据 0,1,2,3,4,5,6,7,8,9,并输出df

(9)对 df 中的'visits'列求平均值以及乘积、和

(10)将 animal 对应的列中所有字符串字母变为大写

- 利用深复制方式创建 df 的副本 df2 并将其所有缺失值填充为 3,并输出df2
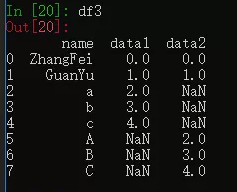
- 利用深复制方式创建 df 的副本 df3 并将其删除缺失值所在的行,并输出df3

答案:
import pandas as pd
import numpy as np
pd.set_option('display.unicode.east_asian_width',True)
pd.set_option('display.unicode.ambiguous_as_wide',True)print()
print("第一题")
df = pd.DataFrame([[np.nan, 2, np.nan, np.nan], [3, 4, 88, np.nan],[np.nan, np.nan, np.nan, 'k'], [np.nan, 3, np.nan, np.nan]],columns=list("ABCD"))
print(df)print()
print("第二题")
dff = pd.DataFrame({"A": [np.nan, 2, np.nan, np.nan], "B": [3, 4, 88, np.nan],"C": [np.nan, np.nan, np.nan, 'k'], "D": [np.nan, 3, np.nan, np.nan]})
print(dff)print()
print("第三题")
df = pd.DataFrame({"Item": ['Item0', 'Item0', 'Item1', 'Item1'], 'CType': ['Gold', 'Bronze', 'Gold', 'Silver'], 'USD': [1, 2, 3, 4],'EU': [1, 2, 3, 4]})
print(df)print()
print("第四题")
number4 = np.ones(10)
number4[4] = 0
print("数组向量", number4)
print("反转数组中的元素", number4[::-1])
number41 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
list4 = []
for i in number41:if i % 2 == 1:list4.append(i)
number42 = np.array(list4)
print(number42)
for i in range(len(number41)):if number41[i] % 2 == 1:number41[i] = -1
print("将数组中的所有奇数替换成-1", number41)print()
print("第五题")
index = pd.date_range('1/1/2022', periods=9, freq='T')
series = pd.Series(range(9), index=index)
print(series)
print(series.resample('3T').sum())print()
print("第六题")
s = pd.Series(data=[80, 90, 100], index=['语文', '数学', '英语'])
for x in s:print(x, end=" ")
print("")
print(s['语文'], s[1])
print(s[0:2]['数学'])
print(s['数学':'英语'][1])
for i in range(len(s.index)):print(s.index[i], end=" ")
s['体育'] = 110
s.pop('数学')
s2 = s.append(pd.Series(120, index=['政治'])) # 不改变s
print(s2['语文'], s2['政治'])
print(list(s2))
print(s.sum(), s.min(), s.mean(), s.median())
print(s.idxmax(), s.argmax())print()
print("第七题")
from copy import deepcopy
data = {'animal':['cat','cat','snake','dog','dog','cat','snake','cat','dog','dog'],'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],'visits':[1,3,2,3,2,3,1,1,2,1],'priority':['yes',np.nan,'no','yes','no','no','no','yes','no','no']}
labels = ['a','b','c','d','e','f','g','h','i','j']
df7 = pd.DataFrame(data,index=labels)
print(df7)print("df的前三行".ljust(20,'='))
print(df7[:3])print("df中visits属性大于2的值".ljust(20,'='))
print(df7[df7['visits']>2])
print("age为缺失值的行".ljust(20,'='))
print(df7[df7['age'].isnull()])print("输出age和animal两列数据".ljust(20,'='))
print(df7[['age','animal']])print("输出 animal==cat 且 age<3 的所有行,并将行为”f”,列为”age”的元素值修改为 1.5".ljust(20,"="))
df7.loc[['f'],['age']]=1.5
print(df7[(df7.animal=='cat')&(df7['age']<3)])print("计算animal有几种动物".ljust(20,'='))
print("出现次数", len(df7['animal'].unique()))print("将animal中所有snake替换为panda".ljust(20,'='))
df7.loc[df7['animal']=='snake','animal']='panda'
print(df7)
print("对 df 按列 animal 进行排序,并打印df".ljust(20,'='))
print(df7.sort_values(by=['animal'],ascending=True))print("在 df 的在后一列后添加一列列名为 No.数据 0,1,2,3,4,5,6,7,8,9,并输出df".ljust(20,'='))
dff = deepcopy(df7.sort_values(by=['animal'],ascending=True))
dff['NO']=[0,1,2,3,4,5,6,7,8,9]
print(dff)print("对 df 中的'visits'列求平均值以及乘积、和".ljust(20,'='))
print("visits的平均值",dff["visits"].mean())
print("visits的成绩",dff["visits"].prod())
print("visits的和",dff["visits"].sum())print("将 animal 对应的列中所有字符串字母变为大写".ljust(20,'='))
dff['animal']=dff['animal'].str.upper()
print(dff)print("利用深复制方式创建 df 的副本 df2 并将其所有缺失值填充为 3,并输出df2".ljust(20,'='))
df2 = deepcopy(dff)
print(df2.fillna(value='3'))print("利用深复制方式创建 df 的副本 df3 并将其删除缺失值所在的行,并输出df3".ljust(20,'='))
df3 = deepcopy(dff)
print(df3.dropna(how='any'))