一、概念
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
二、代码详解
1.基础
pandas最核心的就是Series和DataFrame两个数据结构。
这两种类型的数据结构对比如下:
| 名称 | 维度 | 说明 |
|---|---|---|
| Series | 1维 | 能存储不同类型的数据 |
| DataFrame | 2维 | 表格结构,带有标签,大小可变,并且可以有多种数据类型 |
定义Series
np.nan相当于null,是定义空值
s = pd.Series([1,3,6,np.nan,44,1])
print(s)
结果:
0 1.0
1 3.0
2 6.0
3 NaN
4 44.0
5 1.0
dtype: float64
定义DataFrame
pd.date_range()生成日期序列
DataFrame(1,2,3)
第一个参数是data数据
第二个参数是index,索引
第三个参数是columns是表的列名
默认规则是只有数据
pd.Categorical()将内容数字化存储,运行速度更快
dates = pd.date_range('20190607',periods=6)
print(dates)df = pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])
print(df)df1 = pd.DataFrame(np.arange(12).reshape((3,4))) # 默认df规则
print(df1)df2 = pd.DataFrame({'A':1.,'B':pd.Timestamp('20130102'),'C':pd.Series(1,index=list(range(4)),dtype='float32'),'D':np.array([3]*4,dtype='int32'),'E':pd.Categorical(['test','train','test','train']),'F':'foo'})
print(df2)结果:
DatetimeIndex(['2019-06-07', '2019-06-08', '2019-06-09', '2019-06-10','2019-06-11', '2019-06-12'],dtype='datetime64[ns]', freq='D')a b c d
2019-06-07 0.484568 -0.439881 -0.960222 -1.520919
2019-06-08 1.054979 1.705260 -0.369167 -0.323814
2019-06-09 1.735345 0.404412 -0.306179 -0.380139
2019-06-10 2.583616 0.947599 0.700119 -3.001477
2019-06-11 -0.469525 -0.147207 -0.044570 -1.684648
2019-06-12 -0.345939 0.294284 -0.434633 0.0068240 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
下面介绍一些DataFrame的属性
df2指的是一张DataFrame表
| 名称 | 说明 |
|---|---|
| df2.dtypes | 输出每一列的字符类型 |
| df2.index | 输出序号名 |
| df2.columns | 输出列名 |
| df2.values | 输出所有的值 |
| df2.describe() | 输出dataframe的描述(只输出数字类型) |
| df2.T | 输出df2的转置 |
| df2.sort_index(axis=1,ascending=False) | 输出对烈面进行排序,1代表列,false代表逆序 |
| df2.sort_index(axis=0,ascending=False) | 输出对行号进行排序 ,0代表行,false代表逆序 |
| df2.sort_values(by=‘E’) | 输出根据值进行排序 |
代码;:
print(df2.dtypes) # 输出每一列的字符类型
print(df2.index) # 输出序号名
print(df2.columns) # 输出列名
print(df2.values) # 输出所有的值
print(df2.describe()) # 输出dataframe的描述
print(df2.T) # 输出df2的转置
print(df2.sort_index(axis=1,ascending=False)) #输出对列名进行排序
print(df2.sort_index(axis=0,ascending=False)) # 输出对行号进行排序
print(df2.sort_values(by='E')) # 输出根据值进行排序
输出结果:
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: objectInt64Index([0, 1, 2, 3], dtype='int64')Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')[[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo'][1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo'][1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo'][1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo']]A C D
count 4.0 4.0 4.0
mean 1.0 1.0 3.0
std 0.0 0.0 0.0
min 1.0 1.0 3.0
25% 1.0 1.0 3.0
50% 1.0 1.0 3.0
75% 1.0 1.0 3.0
max 1.0 1.0 3.00 ... 3
A 1 ... 1
B 2013-01-02 00:00:00 ... 2013-01-02 00:00:00
C 1 ... 1
D 3 ... 3
E test ... train
F foo ... foo[6 rows x 4 columns]F E D C B A
0 foo test 3 1.0 2013-01-02 1.0
1 foo train 3 1.0 2013-01-02 1.0
2 foo test 3 1.0 2013-01-02 1.0
3 foo train 3 1.0 2013-01-02 1.0A B C D E F
3 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
0 1.0 2013-01-02 1.0 3 test fooA B C D E F
0 1.0 2013-01-02 1.0 3 test foo
2 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
3 1.0 2013-01-02 1.0 3 train foo
2.选择数据
第一种方式:
普通的索引
df[‘A’]=df.A这两种都是筛选列为A的
df[0:3],df[‘20190608’:‘20190610’] 这两种都是筛选行为0:3的值,后面那种是行的序号的名字。
代码;
dates = pd.date_range('20190607',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
print(df)
print(df['A'],df.A) # 筛选列为A的
print(df[0:3],df['20190608':'20190610']) # 筛选行为0:3的值
结果;
A B C D
2019-06-07 0 1 2 3
2019-06-08 4 5 6 7
2019-06-09 8 9 10 11
2019-06-10 12 13 14 15
2019-06-11 16 17 18 19
2019-06-12 20 21 22 232019-06-07 0
2019-06-08 4
2019-06-09 8
2019-06-10 12
2019-06-11 16
2019-06-12 20
Freq: D, Name: A, dtype: int32 2019-06-07 0
2019-06-08 4
2019-06-09 8
2019-06-10 12
2019-06-11 16
2019-06-12 20
Freq: D, Name: A, dtype: int32A B C D
2019-06-07 0 1 2 3
2019-06-08 4 5 6 7
2019-06-09 8 9 10 11 A B C D
2019-06-08 4 5 6 7
2019-06-09 8 9 10 11
2019-06-10 12 13 14 15
第二种方式是标签索引
select by label :loc方法
通过代码看loc使用方法,下列df都是上述的df
代码;
print(df.loc['20190608']) # 筛选20190608这一行的数据
print(df.loc[:,['A','B']]) # 筛选A,B这两列的数据
print(df.loc['20190607',['A','B']]) # 筛选20190607这一行 和A,B这两列的数据
结果:
A 4
B 5
C 6
D 7
Name: 2019-06-08 00:00:00, dtype: int32A B
2019-06-07 0 1
2019-06-08 4 5
2019-06-09 8 9
2019-06-10 12 13
2019-06-11 16 17
2019-06-12 20 21A 0
B 1
Name: 2019-06-07 00:00:00, dtype: int32
第三种通过行列号索引
select by position:iloc
iloc[]索引只能是行列号,不能像loc一样用标签
代码展示;
# select by position :iloc #通过行号列号索引
print(df.iloc[3:5,1:3]) # 切片3:5行 1:3列
print(df.iloc[[1,3,5],1:3]) # 切片 1,3,5行,1:3列
结果:
B C
2019-06-10 13 14
2019-06-11 17 18B C
2019-06-08 5 6
2019-06-10 13 14
2019-06-12 21 22
第四种方式 ix
mixed selection:ix
ix方法可以标签与行列号混用
代码:
# mixed selection:ix
print(df.ix[:3,['A','C']]) # 筛选前三行和A,C列数据结果:
A C
2019-06-07 0 2
2019-06-08 4 6
2019-06-09 8 10
第五种索引
df.A>8 :满足A列中大于8的所有行
代码;
# Boolean indexing
print(df[df.A>8]) # 满足df.A大于8的所有行
结果:
A B C D
2019-06-10 12 13 14 15
2019-06-11 16 17 18 19
2019-06-12 20 21 22 23
第三讲、设置值
通过不同的方法改变dataframe中的值
可以通过上述方式赋值
loc
iloc
df[df.A>4]
df[‘F’]
df[]里面单个内容时代表是列,如果是0:3,则代表是0到3行
代码:
import numpy as np
import pandas as pddates = pd.date_range('20190607',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
print(df)
df.iloc[2,2] =1111 # 更改数值
df.loc['20190610','B']=2222 # 更改数值
#df[df.A>4] = 0 # 当A列中的中大于4的项全部变成0,包括B列
#df.A[df.A>4] = 0 #仅仅A列中大于4的项变成0
df.B[df.A>4] = 0 #确认A列中大于4的项使得B列中与之对应的项变成零
df['F'] = np.nan
df['E'] = pd.Series([1,2,3,4,5,6],index=pd.date_range('20190607',periods=6))
print(df)结果;
A B C D
2019-06-07 0 1 2 3
2019-06-08 4 5 6 7
2019-06-09 8 9 10 11
2019-06-10 12 13 14 15
2019-06-11 16 17 18 19
2019-06-12 20 21 22 23A B C D F E
2019-06-07 0 1 2 3 NaN 1
2019-06-08 4 5 6 7 NaN 2
2019-06-09 8 0 1111 11 NaN 3
2019-06-10 12 0 14 15 NaN 4
2019-06-11 16 0 18 19 NaN 5
2019-06-12 20 0 22 23 NaN 6
第四讲、处理丢失数据
| 属性 | 说明 |
|---|---|
| df.dropna(axis=1,how=‘any’) | 丢弃缺失方法,how={‘any’,‘all’} how代表的是丢掉方式, any是指只要存在1个或者1个以上,该列就要丢弃,all是必须此列全丢失nan值才能丢弃。 |
| df.fillna(value=0) | 将nan值填充成value值 |
| df.isnull() | isunull判断是否有nan值,若有,即在那个位置返回true |
| np.any(df.isnull())==True | 判断是否至少有一个nan值,若有则返回True |
代码:
import numpy as np
import pandas as pddates = pd.date_range('20190607',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])df.iloc[0,1] = np.nan
df.iloc[1,2] = np.nan
print(df)
print(df.dropna(axis=1,how='any')) # how ={'any','all'} how 代表的是丢掉方式
print(df.fillna(value=0)) # 将nan值填充成value值
print(df.isnull()) # isnull判断是否有nan值,若有,即在那个位置返回trueprint(np.any(df.isnull())==True) # 判断是否至少有一个nan值,若有则返回True
结果;
A B C D
2019-06-07 0 NaN 2.0 3
2019-06-08 4 5.0 NaN 7
2019-06-09 8 9.0 10.0 11
2019-06-10 12 13.0 14.0 15
2019-06-11 16 17.0 18.0 19
2019-06-12 20 21.0 22.0 23A D
2019-06-07 0 3
2019-06-08 4 7
2019-06-09 8 11
2019-06-10 12 15
2019-06-11 16 19
2019-06-12 20 23A B C D
2019-06-07 0 0.0 2.0 3
2019-06-08 4 5.0 0.0 7
2019-06-09 8 9.0 10.0 11
2019-06-10 12 13.0 14.0 15
2019-06-11 16 17.0 18.0 19
2019-06-12 20 21.0 22.0 23A B C D
2019-06-07 False True False False
2019-06-08 False False True False
2019-06-09 False False False False
2019-06-10 False False False False
2019-06-11 False False False False
2019-06-12 False False False FalseTrue第五讲、导入导出
导入导出方法很多,但是格式很相似,无非就是打开格式和保存格式不同。
可以查看官方文档,这里只简单看一下用法。
代码;
import pandas as pddata = pd.read_csv('student.csv') # 读取文件
print(data)
print(type(data))data.to_pickle('student.pickle') # 保存文件
代码可以读出student.csv的数据
data的类型是pandas.core.frame.DataFrame
保存形式为pickle形式,序列化
第六讲、合并concat
先简单运用concat合并dataframe
pd.concat([df1,df2,df3],axis=0) # 竖向合并
当axis为1时,为横向合并。
pd.concat([df1,df2,df3],axis=0,ignore_index=True) # 竖向合并,忽略index
ignore_index为真忽略每个dataframe中的index,重新排列
代码;
# concatenating
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])res = pd.concat([df1,df2,df3],axis=0) # 竖向合并
print(res)res = pd.concat([df1,df2,df3],axis=0,ignore_index=True) # 竖向合并,忽略index
print(res)
下面看concat的另一个参数join{‘inner’,‘outer’}
对于一些表中列名并完全相同的时候合并要用到join,outer是默认加入方式,将合并的几个表格的列全部列出来,没有值的设为nan值。inner是取几个表列的交集。
注意:python3后默认加入方式要加一个参数sort=True
下面通过代码展示:
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])res = pd.concat([df1,df2],join='outer',sort = True) # 默认加入方式
print(res)res = pd.concat([df1,df2],join='inner',ignore_index=True) # inner模式
print(res)
结果;
a b c d e
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 0.0 0.0 0.0 0.0 NaN
2 NaN 1.0 1.0 1.0 1.0
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0b c d
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
5 1.0 1.0 1.0
另一个参数join_axes
join_axes=[df1.index]使用df1表格的索引
代码:
# join_axes
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])
res = pd.concat([df1,df2],axis=1,join_axes=[df1.index]) # 横向合并,按照df1的index合并
print(res)
结果;
a b c d b c d e
1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
append()方法
指定一个df调用此方法,然后扩展此表
可以添加df和序列
代码;
# append
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
res=df1.append([df2,df3],ignore_index=True) # 竖向添加
print(res)
s1 = pd.Series([1,2,3,4],index=['a','b','c','d'])
res = df1.append(s1,ignore_index=True) # 添加一个序列
print(res)
结果:
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 1.0 1.0 1.0 1.0
7 1.0 1.0 1.0 1.0
8 1.0 1.0 1.0 1.0a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 2.0 3.0 4.0第七讲、合并merge
利用关键字进行合并,有点像数据库中的主键。
上来举一个简单的例子。
代码;
import pandas as pd
# merging two df by key/keys.(may be used in database)
# simple example
left = pd.DataFrame({'key':['K0','K1','K2','K3'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key':['K0','K1','K2','K3'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})print(left)
print(right)
res = pd.merge(left,right,on='key')
print(res)
结果:
A B key
0 A0 B0 K0
1 A1 B1 K1
2 A2 B2 K2
3 A3 B3 K3C D key
0 C0 D0 K0
1 C1 D1 K1
2 C2 D2 K2
3 C3 D3 K3A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K2 C2 D2
3 A3 B3 K3 C3 D3
可以看出,是根据key这一列的值进行了合并。
下面看由两个key控制的例子
merge()里面也有一个how的参数
how = [‘left’,‘right’,‘outer’,‘inner’]
‘left’指的是关键字的内容按照第一个dataframe来
‘right’指的是关键字的内容按照最后一个dataframe来
‘outer’指的是关键字
# consider two keys
left = pd.DataFrame({'key1':['K0','K0','K1','K2'],'key2':['K0','K1','K0','K1'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key1':['K0','K1','K1','K2'],'key2':['K0','K0','K0','K0'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})print(left)
print(right)
how = ['left','right','outer','inner']
res = pd.merge(left,right,on=['key1','key2'],how='inner')
print(res)结果:
A B key1 key2
0 A0 B0 K0 K0
1 A1 B1 K0 K1
2 A2 B2 K1 K0
3 A3 B3 K2 K1C D key1 key2
0 C0 D0 K0 K0
1 C1 D1 K1 K0
2 C2 D2 K1 K0
3 C3 D3 K2 K0A B key1 key2 C D
0 A0 B0 K0 K0 C0 D0
1 A2 B2 K1 K0 C1 D1
2 A2 B2 K1 K0 C2 D2
下一个参数indicator参数
当indicator= True时,会给出一列用来存储两个df中值的存在情况
当indicator=‘ indicator_column’ 会重命名该列
代码;
# indicator
df1 = pd.DataFrame({'col1':[0,1],'col_left':['a','b']})
df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]})
print(df1)
print(df2)
#res = pd.merge(df1,df2,on='col1',how='outer',indicator=True) # 给出一列用来存储两个df中值的存在情况
# give the indicator a custom name
res = pd.merge(df1,df2,on='col1',how='outer',indicator='indicator_column')
print(res)
结果:
col1 col_left
0 0 a
1 1 bcol1 col_right
0 1 2
1 2 2
2 2 2col1 col_left col_right indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_onlymerge 用 索引
pd.merge(left,right,left_index=True,right_index=True,how=‘outer’)
令left_index和right_index都为True
同时how的作用同前面的一样
代码:
# merged by indexleft = pd.DataFrame({'A':['A0','A1','A2'],'B':['B0','B1','B2']},index=['K0','K1','K2'])
right = pd.DataFrame({ 'C':['C0','C1','C2'],'D':['D0','D1','D2']},index=['K0','K2','K3'])
print(left)
print(right)# left_index and right_index
res = pd.merge(left,right,left_index=True,right_index=True,how='outer') # 基于index合并
# res = pd.merge(left,right,left_index=True,right_index=True,how='inner')
print(res)
print('*'*50)
结果;
A B
K0 A0 B0
K1 A1 B1
K2 A2 B2C D
K0 C0 D0
K2 C1 D1
K3 C2 D2A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C1 D1
K3 NaN NaN C2 D2
当一个表中关键字有相同的时候,要全部对应起来
pd.merge(boys,girls,on=‘k’,suffixes=[’_boy’,’_girl’],how=‘outer’)
suffixes参数是在要合并的两个表中列名后面加的内容。
代码:
# handle overlapping
boys = pd.DataFrame({'k':['K0','K1','K2'],'age':[1,2,3]})
girls = pd.DataFrame({'k':['K0','K0','K3'],'age':[4,5,6]})print(boys)
print(girls)
res = pd.merge(boys,girls,on='k',suffixes=['_boy','_girl'],how='outer')
print(res)
结果:
age k
0 1 K0
1 2 K1
2 3 K2age k
0 4 K0
1 5 K0
2 6 K3age_boy k age_girl
0 1.0 K0 4.0
1 1.0 K0 5.0
2 2.0 K1 NaN
3 3.0 K2 NaN
4 NaN K3 6.0
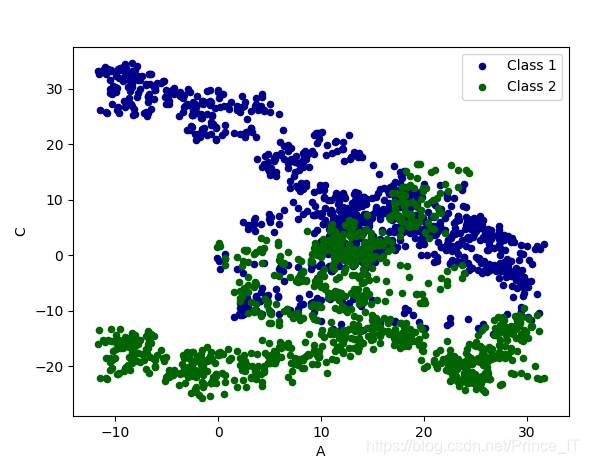
第八讲、plot画图
plot在matplotlib经常使用,在pandas中也可以使用。
plot method:
‘bar’,‘hist’,‘box’,‘kde’,‘area’,‘scatter’,‘hexbin’,‘pie’
plot有很多图,大家需要的可以找官方文档学习一下。这里展示一下plot使用。
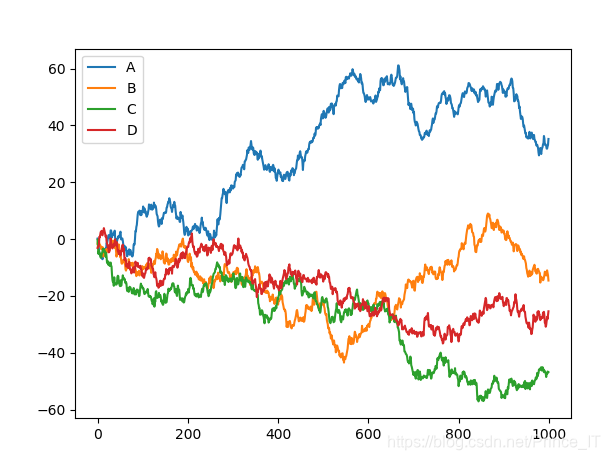
我们随机了一组数据,进行画图操作。
代码;
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# plot data# Series 线性数据
data = pd.Series(np.random.randn(1000),index=np.arange(1000))
data = data.cumsum()# DataFrame
data = pd.DataFrame(np.random.randn(1000,4),index=np.arange(1000),columns=list("ABCD"))
print(data.head())
data=data.cumsum() # 累加函数data.plot()
# plot method:
# 'bar','hist','box','kde','area','scatter','hexbin','pie'ax=data.plot.scatter(x='A',y='B',color='DarkBlue',label='Class 1')data.plot.scatter(x='A',y='C',color='DarkGreen',label='Class 2',ax=ax)
plt.show()
结果;
(未完待续)