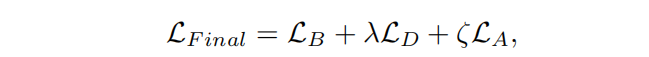合并df1和df2时保留df1和df2的所有列,并且按照df2的列顺序排序,可以按照以下步骤进行操作:
import pandas as pd# 示例数据
data1 = {'F': [1, 2, 3],'A': [1, 2, 3],'B': [4, 5, 6],'E': [4, 5, 6]}
df1 = pd.DataFrame(data1)data2 = {'C': [7, 8, 9],'A': [10, 11, 12],'B': [13, 14, 15],'D': [16, 17, 18]}
df2 = pd.DataFrame(data2)# 获取目标列顺序
columns_order = list(df2.columns) + list(df1.columns)
columns_order = [x for i, x in enumerate(columns_order) if x not in columns_order[:i]]# 合并df1和df2
merged_df = pd.concat([df1, df2], ignore_index=True)# 按照df2的列顺序重新排列列
merged_df = merged_df.reindex(columns=columns_order)print(merged_df)
结果如下:
C A B D F E
0 NaN 1 4 NaN 1.0 4.0
1 NaN 2 5 NaN 2.0 5.0
2 NaN 3 6 NaN 3.0 6.0
3 7.0 10 13 16.0 NaN NaN
4 8.0 11 14 17.0 NaN NaN
5 9.0 12 15 18.0 NaN NaN
通过以上步骤,我们成功按照df2的列顺序合并了df1和df2,并保留了两个DataFrame的所有列,包括B列。在合并后的结果中,df1的列保留了原始的顺序,而df2的列按照df2的顺序进行了排序。缺失的部分用NaN进行填充。
灵感来自:
要删除列表中重复的元素,只保留先出现的元素,可以使用列表推导式和集合(Set)来实现。以下是示例代码:
original_list = [1, 2, 3, 2, 4, 1, 5, 3]# 使用列表推导式和集合来删除重复元素,只保留先出现的
unique_list = [x for i, x in enumerate(original_list) if x not in original_list[:i]]print(unique_list)
输出结果为:
[1, 2, 3, 4, 5]
在这个例子中,我们使用列表推导式和集合来删除重复元素。在列表推导式中,我们遍历原始列表original_list,并使用切片original_list[:i]来获取当前元素之前的子列表。然后,使用条件x not in original_list[:i]来判断当前元素是否在子列表中出现过。如果没有出现过,则将该元素添加到新的列表unique_list中。通过这种方式,我们可以只保留先出现的元素,并删除重复的元素。
![[ICCV2019]DF2Net: A Dense-Fine-Finer Network for Detailed 3D Face Reconstruction](https://img-blog.csdnimg.cn/661b54e6c1b646ee8e3a082df2c50262.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rex6JOd6JOd6JOd6JOd6JOd,size_20,color_FFFFFF,t_70,g_se,x_16)