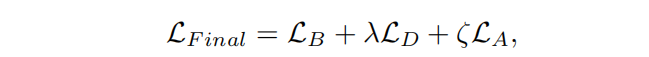文章目录
- 写在前面
- 一、关系型连接
- 1. 连接的基本概念
- 2. 值连接
- 【练一练】
- 3. 索引连接
- 二、方向连接
- 1. concat
- 2. 序列与表的合并
- 三、类连接操作
- 1. 比较
- 2. 组合
- 【练一练】
- 【练一练】
- 四、练习
- Ex1:美国疫情数据集
- Ex2:实现join函数
写在前面
本文内容源自Datawhale 组队学习教程,并结合了部分自己的笔记和感悟。对Datawhale感兴趣且想进一步了解:https://github.com/datawhalechina/joyful-pandas
一、关系型连接
1. 连接的基本概念
把两张相关的表按照某一个或某一组键连接起来是一种常见操作,在关系型连接中, 键 \color{red}{键} 键是十分重要的,往往用on参数表示。
另一个重要的要素是连接的形式。在pandas中的关系型连接函数merge和join中提供了how参数来代表连接形式,分为左连接left、右连接right、内连接inner、外连接outer,它们的区别如图:

- 左连接
left:以左边的键为准,如果右边表中的键于左边存在,那么就添加到左边,否则则处理为缺失值。 - 右连接
right:以右边的键为准,如果左边表中的键于右边存在,那么就添加到右边,否则则处理为缺失值。 - 内连接
inner:只负责合并两边同时出现的键。 - 外连接
outer:会在内连接的基础上包含只在左边出现以及只在右边出现的值,因此外连接又叫全连接。
如果出现重复的键:
只需把握一个原则:只要两边同时出现的值,就以笛卡尔积的方式加入,如果单边出现则根据连接形式进行处理。
其中,关于笛卡尔积可用如下例子说明:设左表中键张三出现两次,右表中的张三也出现两次,那么逐个进行匹配,最后产生的表必然包含2*2个姓名为张三的行,如图:

显然在不同的场合应该使用不同的连接形式。其中左连接和右连接是等价的,由于它们的结果中的键是被一侧的表确定的,因此常常用于有方向性地添加到目标表。内外连接两侧的表,经常是地位类似的,想取出键的交集或者并集,具体的操作还需要业务的需求来判断。
2. 值连接
- 由
merge函数实现通过几列值的组合进行连接,例如第一张图的左连接:
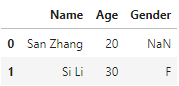
df1 = pd.DataFrame({'Name':['San Zhang','Si Li'], 'Age':[20,30]})
df2 = pd.DataFrame({'Name':['Si Li','Wu Wang'], 'Gender':['F','M']})
df1.merge(df2, on='Name', how='left')
- 两个表中想要连接的列不具备相同的列名,可以通过
left_on和right_on指定:
df1 = pd.DataFrame({'df1_name':['San Zhang','Si Li'], 'Age':[20,30]})
df2 = pd.DataFrame({'df2_name':['Si Li','Wu Wang'], 'Gender':['F','M']})
df1.merge(df2, left_on='df1_name', right_on='df2_name', how='left')
- 两个表中的列出现了重复的列名,可以通过
suffixes参数指定。
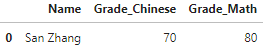
例如合并考试成绩的时候,第一个表记录了语文成绩,第二个是数学成绩:相当于给重复列名加了后缀以区分。
df1 = pd.DataFrame({'Name':['San Zhang'],'Grade':[70]})
df2 = pd.DataFrame({'Name':['San Zhang'],'Grade':[80]})
df1.merge(df2, on='Name', how='left', suffixes=['_Chinese','_Math'])

- 出现重复元素,这种时候就要指定
on参数为多个列使得正确连接:
e.g.:
有df1和df2两张表,df1如下:
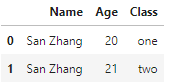
df2如下:
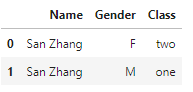
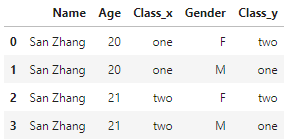
错误连接(笛卡尔积):
df1.merge(df2, on='Name', how='left') # 错误的结果
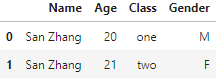
正确连接(相当于进行多列信息的锁定和匹配):
df1.merge(df2, on=['Name', 'Class'], how='left') # 正确的结果
从上面的例子来看,在进行基于唯一性的连接下,如果键不是唯一的,那么结果就会产生问题。举例中的行数很少,但如果实际数据中有几十万到上百万行的进行合并时,如果想要保证唯一性,除了用duplicated检查是否重复外,merge中也提供了validate参数来检查连接的唯一性模式。这里共有三种模式:
- 一对一连接
1:1(左右表的键都是唯一的) - 一对多连接
1:m(左表键唯一) - 多对一连接
m:1(右表键唯一)
【练一练】
上面以多列为键的例子中,错误写法显然是一种多对多连接,而正确写法是一对一连接,请修改原表,使得以多列为键的正确写法能够通过validate='1:m'的检验,但不能通过validate='m:1'的检验。
解:
只需要对df1做如下改动,改成我的名字hhh:
df1 = pd.DataFrame({'Name':['San Zhang', 'Lin Mumu'],'Age':[20, 21],'Class':['one', 'two']})
df2 = pd.DataFrame({'Name':['San Zhang', 'San Zhang'],'Gender':['F', 'M'],'Class':['two', 'one']})
然后1:m:
df1.merge(df2, on='Name', how='left',validate='1:m')
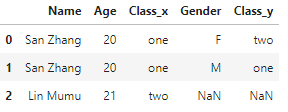
m:1报错:
df1.merge(df2, on='Name', how='left',validate='m:1')

3. 索引连接
索引连接:把索引当作键,因此这和值连接本质上没有区别,pandas中利用join函数来处理索引连接,它的参数选择要少于merge,除了必须的on和how之外,可以对重复的列指定左右后缀lsuffix和rsuffix。其中,on参数指索引名,单层索引时省略参数表示按照当前索引连接。
e.g.
df1和df2分别如下:
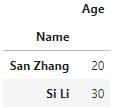
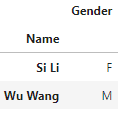
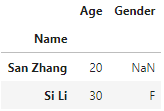
使用join:
df1.join(df2, how='left')
仿照第2小节的例子,语文和数学分数合并的join版本:
df1.join(df2, how='left', lsuffix='_Chinese', rsuffix='_Math')

如果想要进行类似于merge中以多列为键的操作的时候,join需要使用多级索引,例如在merge中的最后一个例子可以如下写出:
df1 = pd.DataFrame({'Age':[20,21]}, index=pd.MultiIndex.from_arrays([['San Zhang', 'San Zhang'],['one', 'two']], names=('Name','Class')))
df2 = pd.DataFrame({'Gender':['F', 'M']}, index=pd.MultiIndex.from_arrays([['San Zhang', 'San Zhang'],['two', 'one']], names=('Name','Class')))
df1
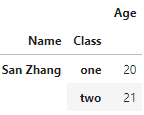
df2

df1.join(df2)
二、方向连接
1. concat
前面介绍了关系型连接,其中最重要的参数是on和how,但有时候用户并不关心以哪一列为键来合并,只是希望把两个表或者多个表按照纵向或者横向拼接,为这种需求,pandas中提供了concat函数来实现。
在concat中,最常用的有三个参数:
axis拼接方向join连接形式keys指示来自于哪一张旧表的名字- 特别注意,
join和keys与之前提到的join函数和键的概念没有任何关系。
在默认状态下的axis=0,表示纵向拼接多个表,常常用于多个样本的拼接;
而axis=1表示横向拼接多个表,常用于多个字段或特征的拼接。
例如,纵向合并各表中人的信息:
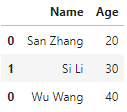
df1 = pd.DataFrame({'Name':['San Zhang','Si Li'], 'Age':[20,30]})
df2 = pd.DataFrame({'Name':['Wu Wang'], 'Age':[40]})
pd.concat([df1, df2])
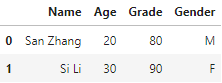
横向合并各表中的字段:
df2 = pd.DataFrame({'Grade':[80, 90]})
df3 = pd.DataFrame({'Gender':['M', 'F']})
pd.concat([df1, df2, df3], 1)
虽然说concat是处理关系型合并的函数,但是它仍然是关于索引进行连接的。
- 纵向拼接会根据列索引对其,默认状态下
join=outer,表示保留所有的列,并将不存在的值设为缺失;join=inner,表示保留两个表都出现过的列。 - 横向拼接则根据行索引对齐,
join参数可以类似设置。
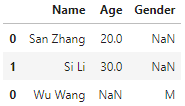
df2 = pd.DataFrame({'Name':['Wu Wang'], 'Gender':['M']})
pd.concat([df1, df2])
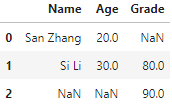
df2 = pd.DataFrame({'Grade':[80, 90]}, index=[1, 2])
pd.concat([df1, df2], 1)
pd.concat([df1, df2], axis=1, join='inner')

因此,当确认要使用多表直接的方向合并时,尤其是横向的合并,可以先用reset_index方法恢复默认整数索引再进行合并,防止出现由索引的误对齐和重复索引的笛卡尔积带来的错误结果。
keys参数的使用场景在于多个表合并后,用户仍然想要知道新表中的数据来自于哪个原表,这时可以通过keys参数产生多级索引进行标记。
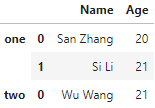
例如,第一个表中都是一班的同学,而第二个表中都是二班的同学,可以使用如下方式合并:
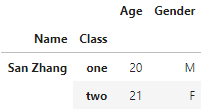
df1 = pd.DataFrame({'Name':['San Zhang','Si Li'], 'Age':[20,21]})
df2 = pd.DataFrame({'Name':['Wu Wang'],'Age':[21]})
pd.concat([df1, df2], keys=['one', 'two'])
2. 序列与表的合并
利用concat可以实现多个表之间的方向拼接,如果想要把一个序列追加到表的行末或者列末,则可以分别使用append和assign方法。
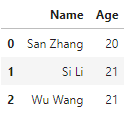
- 在
append中,如果原表是默认整数序列的索引,那么可以使用ignore_index=True对新序列对应索引的自动标号,否则必须对Series指定name属性。
s = pd.Series(['Wu Wang', 21], index = df1.columns)
df1.append(s, ignore_index=True)
- 对于
assign而言,虽然可以利用其添加新的列,但一般通过df['new_col'] = ...的形式就可以等价地添加新列。同时,使用[]修改的缺点是它会直接在原表上进行改动,而assign返回的是一个临时副本:
s = pd.Series([80, 90])
df1.assign(Grade=s)
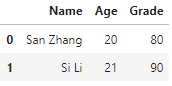
df1['Grade'] = s
df1
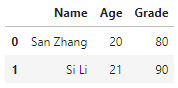
df1本身发生了变化
三、类连接操作
除了上述介绍的若干连接函数之外,pandas中还设计了一些函数能够对两个表进行某些操作,这里把它们统称为类连接操作。
1. 比较
compare是在1.1.0后引入的新函数,它能够比较两个表或者序列的不同处并将其汇总展示:
df1 = pd.DataFrame({'Name':['San Zhang', 'Si Li', 'Wu Wang'],'Age':[20, 21 ,21],'Class':['one', 'two', 'three']})
df2 = pd.DataFrame({'Name':['San Zhang', 'Li Si', 'Wu Wang'],'Age':[20, 21 ,21],'Class':['one', 'two', 'Three']})
df1.compare(df2)
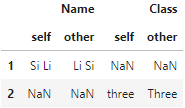
结果中返回了不同值所在的行列,如果相同则会被填充为缺失值NaN,其中other和self分别指代传入的参数表和被调用的表自身。
如果想要完整显示表中所有元素的比较情况,可以设置keep_shape=True:
df1.compare(df2, keep_shape=True)
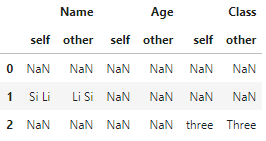
2. 组合
combine函数能够让两张表按照一定的规则进行组合,在进行规则比较时会自动进行列索引的对齐。- 对于传入的函数而言,每一次操作中输入的参数是来自两个表的同名
Series,依次传入的列是两个表列名的并集。
例如下面这个例子会依次传入A,B,C,D四组序列,每组为左右表的两个序列。同时,进行A列比较的时候,s1指代的就是一个全空的序列,因为它在被调用的表中并不存在,并且来自第一个表的序列索引会被reindex成两个索引的并集。具体的过程可以通过在传入的函数中插入适当的print方法查看。
下面的例子表示选出对应索引位置较小的元素:
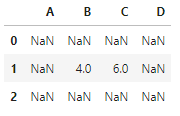
def choose_min(s1, s2):s2 = s2.reindex_like(s1)res = s1.where(s1<s2, s2)res = res.mask(s1.isna()) # isna表示是否为缺失值,返回布尔序列return res
df1 = pd.DataFrame({'A':[1,2], 'B':[3,4], 'C':[5,6]})
df2 = pd.DataFrame({'B':[5,6], 'C':[7,8], 'D':[9,10]}, index=[1,2])
df1.combine(df2, choose_min)
【练一练】
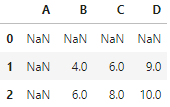
请在上述代码的基础上修改,保留df2中4个未被df1替换的相应位置原始值。
解:
修改后代码:
def choose_min(s1, s2):s2 = s2.reindex_like(s1)res = s1.where(s1<s2, s2)return res
df1 = pd.DataFrame({'A':[1,2], 'B':[3,4], 'C':[5,6]})
df2 = pd.DataFrame({'B':[5,6], 'C':[7,8], 'D':[9,10]}, index=[1,2])
df1.combine(df2, choose_min)
简而言之去掉“res = res.mask(s1.isna()) ”
则可得到题目要求的结果:
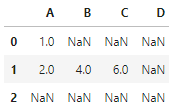
此外,设置overtwrite参数为False可以保留 被 调 用 表 \color{red}{被调用表} 被调用表中未出现在传入的参数表中的列,而不会设置未缺失值:
df1.combine(df2, choose_min, overwrite=False)
【练一练】
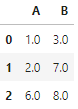
除了combine之外,pandas中还有一个combine_first方法,其功能是在对两张表组合时,若第二张表中的值在第一张表中对应索引位置的值不是缺失状态,那么就使用第一张表的值填充。下面给出一个例子,请用combine函数完成相同的功能。
df1 = pd.DataFrame({'A':[1,2], 'B':[3,np.nan]})
df2 = pd.DataFrame({'A':[5,6], 'B':[7,8]}, index=[1,2])
df1.combine_first(df2)
解:
def myfunc(s1, s2):res = s1.mask(s1.isna(),s2)return res
df1 = pd.DataFrame({'A':[1,2], 'B':[3,np.nan]})
df2 = pd.DataFrame({'A':[5,6], 'B':[7,8]}, index=[1,2])
df1.combine(df2,myfunc)
四、练习
Ex1:美国疫情数据集
现有美国4月12日至11月16日的疫情报表,请将New York的Confirmed, Deaths, Recovered, Active合并为一张表,索引为按如下方法生成的日期字符串序列:
date = pd.date_range('20200412', '20201116').to_series()
date = date.dt.month.astype('string').str.zfill(2) +'-'+ date.dt.day.astype('string').str.zfill(2) +'-'+ '2020'
date = date.tolist()
date[:5]['04-12-2020', '04-13-2020', '04-14-2020', '04-15-2020', '04-16-2020']
解:
先创建一个空的dataframe
df_empty = pd.DataFrame()
然后读取美国4月12日至11月16日的疫情报表,并将New York的Confirmed, Deaths, Recovered, Active合并为一张表:
import os
datalist=os.listdir('data/us_report/')
for file in datalist:df = pd.read_csv('data/us_report/'+file,usecols = ['Province_State','Confirmed','Deaths','Recovered','Active'])df = df.set_index('Province_State')df = df.loc['New York', ['Confirmed','Deaths','Recovered','Active']]df_empty = df_empty.append(df,ignore_index=True)
df_empty

最后把index按照题目要求改成data里的格式:
df_empty.index = date
df_empty

Ex2:实现join函数
请实现带有how参数的join函数
- 假设连接的两表无公共列
- 调用方式为
join(df1, df2, how="left") - 给出测试样例
解:
本题有点复杂,两脑空空,只能对参考答案做了一遍阅读理解。为了笔记的完整性,将参考答案搬运至此,便于日后查阅和新的理解:
def join(df1, df2, how='left'):res_col = df1.columns.tolist() + df2.columns.tolist()dup = df1.index.unique().intersection(df2.index.unique())res_df = pd.DataFrame(columns = res_col)for label in dup:cartesian = [list(i)+list(j) for i in df1.loc[label].values for j in df2.loc[label].values]dup_df = pd.DataFrame(cartesian, index = [label]*len(cartesian), columns = res_col)res_df = pd.concat([res_df,dup_df])if how in ['left', 'outer']:for label in df1.index.unique().difference(dup):if isinstance(df1.loc[label], pd.DataFrame):cat = [list(i)+[np.nan]*df2.shape[1] for i in df1.loc[label].values]else:cat = [list(i)+[np.nan]*df2.shape[1] for i in df1.loc[label].to_frame().values]dup_df = pd.DataFrame(cat, index = [label]*len(cat), columns = res_col)res_df = pd.concat([res_df,dup_df])if how in ['right', 'outer']:for label in df2.index.unique().difference(dup):if isinstance(df2.loc[label], pd.DataFrame):cat = [[np.nan]+list(i)*df1.shape[1] for i in df2.loc[label].values]else:cat = [[np.nan]+list(i)*df1.shape[1] for i in df2.loc[label].to_frame().values]dup_df = pd.DataFrame(cat, index = [label]*len(cat), columns = res_col)res_df = pd.concat([res_df,dup_df])return res_df
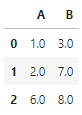
df1 = pd.DataFrame({'col1':list('01234')}, index=list('AABCD'))
df1
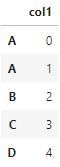
df2 = pd.DataFrame({'col2':list('opqrst')}, index=list('ABBCEE'))
df2

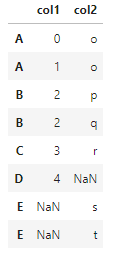
join(df1, df2, how='outer')

![[ICCV2019]DF2Net: A Dense-Fine-Finer Network for Detailed 3D Face Reconstruction](https://img-blog.csdnimg.cn/661b54e6c1b646ee8e3a082df2c50262.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5rex6JOd6JOd6JOd6JOd6JOd,size_20,color_FFFFFF,t_70,g_se,x_16)