K8s 为什么要弃用 Docker
最近在学习容器技术的过程中,看到有关于Kubernetes“弃用 Docker”的事情,担心现在学 Docker 是否还有价值,是否现在就应该切换到 containerd 或者是其他 runtime。
随着深入了解,这些疑虑的确是有些道理。三年前,Kubernetes 放出消息要“弃用 Docker”的时候,确确实实在 Kubernetes 社区里掀起了一场“轩然大波”,影响甚至波及到社区之外,也导致 Kubernetes 不得不写了好几篇博客来反复解释这么做的原因。三年过去了,虽然 Kubernetes 1.24 已经达成了“弃用”的目标,但对这件事还是没有非常清晰的认识,所以记录下这个事件的始末。
背景:Kubernetes的发展
要理解 K8s 为何“弃用 Docker”,我们得回顾一下 K8s 的发展史。
Kubernetes是Google公司早在2014年就发布开源的一个容器基础设施编排框架,这项技术是有理论依据,即:Borg。Borg是Google公司整个基础设施体系中的一部分,Borg是Google公司整个基础设施体系中的一部分,Google也发布了多篇关于Borg的论文作为其理论支持。其上承载了比如MapReduce、BigTable等诸多业界的头部技术。因此Borg系统一直以来都被誉为Google公司内部最强大的“秘密武器”,也是Google公司最不可能开源的项目,而Kubernetes就是在这样的理论基础上开发的。下图是Google Omega论文所描述的Google已公开的基础设施栈。

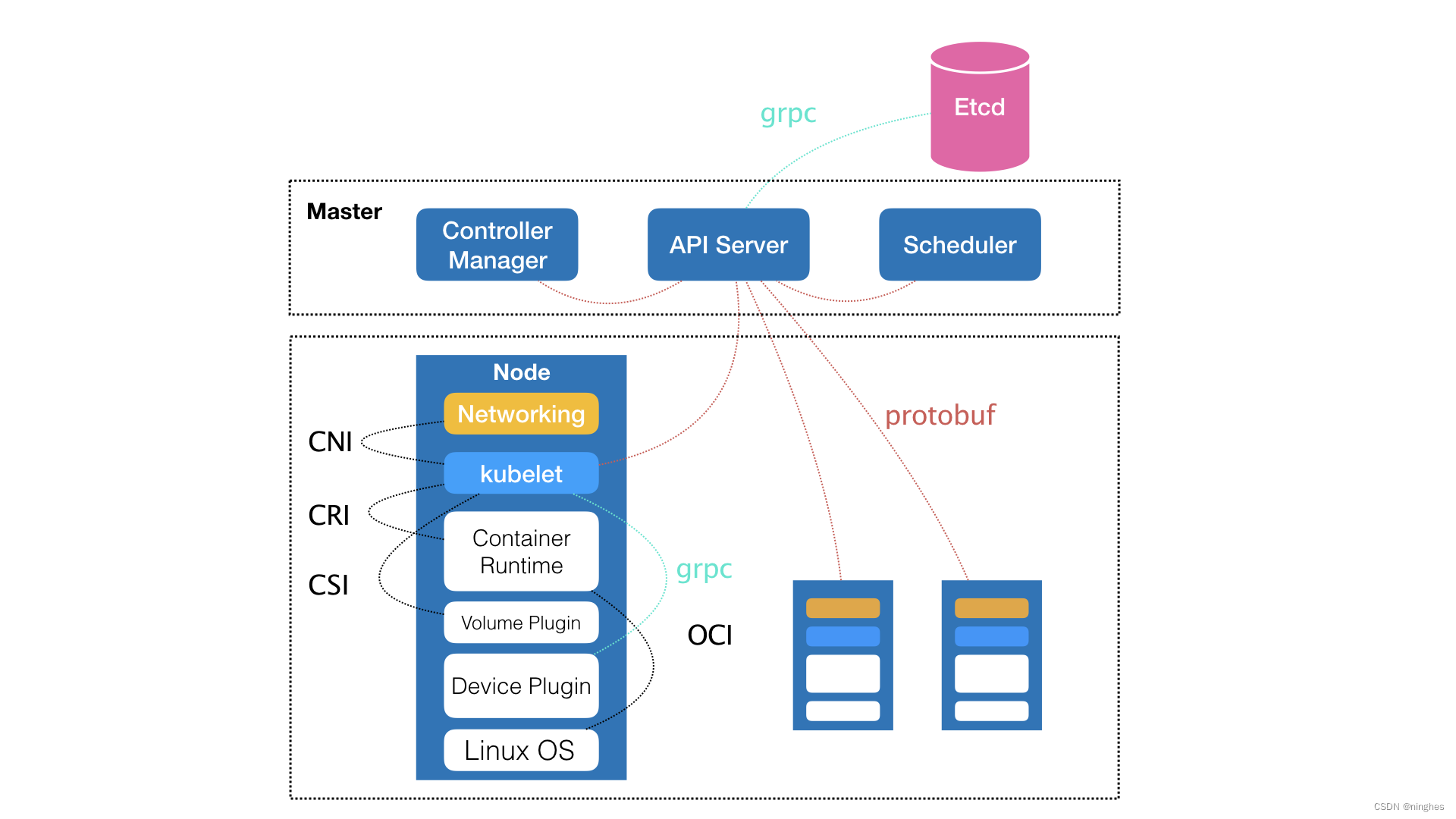
Kubernetes 项目的架构(如下图)跟它的原型项目 Borg 非常类似,都由 Master 和 Node 两种节点组成,而这两种节点分别对应着控制节点和计算节点。
-
Master 节点也就是控制节点,是整个集群的中枢,是 Stateful 的,负责维持整个 Kubernetes
集群的状态。它由三个独立组件组合而成,分别是:负责 API 服务的 kube-apiserver、负责调度的
kube-scheduler,以及负责容器编排的 kube-controller-manager。整个集群的持久化数据,则由
kube-api-server 处理后保存在 Etcd 中。为了保证职责单一,Master 节点一般不会部署容器。Borg 对 Kubernetes 的指导体现在 Master 节点上,Borg 和 Kubernetes 的 Master
节点虽然实现细节上可能会不同,但它们出发的高度却是一致的,即:如何编排、管理、调度用户提交的作业。 -
Node 节点也就是计算节点,它才是部署的容器真正运行的地方。它上面最核心的是 kubelet 组件(master 节点上也会有
kubelet 组件),Kubelet 主要负责同容器运行时(比如 Docker 项目)打交道,使用了 CRI(Container
Runtime Interface)的远程调用接口。这个接口定义了容器运行时的各项核心操作,比如启动一个容器需要的所有参数。这也是为什么
Kubernetes 项目并不关心你使用的是什么容器运行时,只要这个容器运行时能够运行标准的容器镜像,它就可以通过实现 CRI 接入到
Kubernetes 项目当中。具体的容器运行时,比如 Docker 项目,则一般通过 OCI 这个容器运行时规范同底层的 Linux 操作系统进行交互,即:把 CRI
请求翻译成对 Linux 操作系统的调用,比如调用 Namespace 和 Cgroups 等。此外,kubelet 还通过 gRPC 协议与 Device Plugin 进行交互,这个插件是 Kubernetes 用来管理 GPU
等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能。kubelet 还可以通过 CNI(Container Networking Interface)和 CSI(Container
Storage Interface)接口分别调用网络插件和存储插件为容器配置网络和持久化存储。kubelet 这个名字来自于 Borg 项目中的同源组件 Borglet。只是,Borg 项目中并不支持容器技术,而只是简单地使用了
Linux Cgroups 对进程进行限制。这也就意味着,像 Docker 这样的“容器镜像”在 Borg
中并不存在,自然不需要对容器镜像进行管理,但是 Google 内部却有在使用一个包管理工具,名叫 Midas Package
Manager(MPM),它可以部分取代 Docker 镜像的角色。之外,Borglet 组件也不需要考虑如何同 Docker
进行交互,也不需要支持 CRI、CNI、CSI 等诸多容器技术接口。可以说 kubelet 完全就是为了实现 Kubernetes
对容器的管理能力而重新实现的一个组件,与 Borg 之间并没有直接的传承关系。
Kubernetes 项目并没有像同时期的各种“容器云”项目那样,把 Docker 作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现。也就相当于把 Docker 仅仅看成一种新的应用打包方式,那么 Borg 过去在大规模作业管理与编排上的经验就可以直接应用到 Kubernetes 项目上。
CRI
而在2014 年,Docker 正处于鼎盛时期,K8s 刚刚诞生,虽然它得到了 Google 和 Borg 的支持,但它还是比较新的。
因此,K8s 首先选择支持 Docker 。
快进到 2016 年,CNCF 成立一年,K8s 也发布了 1.0 版本,可以正式用于生产环境。这些都表明 K8s 已经长大了。
于是宣布加入 CNCF,成为第一个 CNCF 托管项目。它想利用基金会的力量联合其他厂商来“打倒”Docker。
在 2016 年底的 1.5 版本中,K8s 引入了新的接口标准:CRI:Container Runtime Interface 容器运行时接口。
CRI 使用ProtoBufferandgPRC来指定kubelet应该如何调用容器运行时来管理容器和镜像,但这是一组与以前的 Docker 调用完全不兼容的新接口。
显然它不想再和 Docker 绑定,在底层允许访问其他容器技术(如 rkt、kata 等),可以随时“踢开” Docker。
但此时 Docker 已经非常成熟,市场的惯性也非常强。各大云厂商不可能一下子全部替换掉 Docker。
因此,K8s 只能同时提供一种“折中”的方案,在kubelet和 Docker 之间增加一个“适配器”,将 Docker 的接口转换为 CRI 兼容的接口:
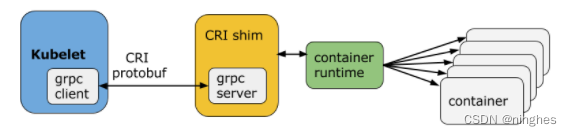
因为这个“适配器”夹在kubeletDocker 和 Docker 之间,所以形象地称为“shim”,意思是“垫片”。
有了 CRI 和 shim,虽然 K8s 仍然使用 Docker 作为底层运行时,但它也具备了与 Docker 解耦的条件,从而拉开了“弃用 Docker”大戏的帷幕。
Containerd
面对挑战,Docker 采取了“断臂求生”的策略,推动自身重构,将原有单一架构的 Docker Engine 拆分成多个模块,其中 Docker daemon 部分捐赠给 CNCF,containerd 形成。
作为 CNCF 的托管项目,containerd 必须符合 CRI 标准。但是由于很多原因,Docker 只是 containerd 在 Docker Engine 中调用,对外的接口保持不变,也就是说不兼容 CRI。
由于 Docker 的“固执”,此时 K8s 中有两条调用链:
- 使用 CRI 接口调用 dockershim,然后 dockershim 调用 Docker,Docker 再去 containerd
操作容器。 - 使用 CRI 接口直接调用 containerd 操作容器。
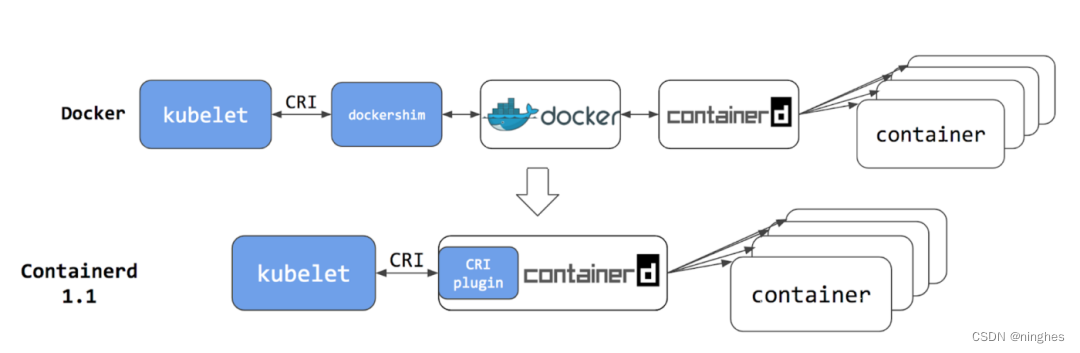
显然,因为 containerd 是用来管理容器的,所以这两个调用链的最终效果是完全一样的,但是第二种方法去掉了 dockershim 和 Docker Engine 这两个环节,更加简洁明了,性能也更好。
2018 年 Kubernetes 1.10 发布时,containerd 也更新到 1.1 版本,正式与 Kubernetes 集成,并发表[博文](https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration- gos-ga/ “博文”)显示一些性能测试数据:
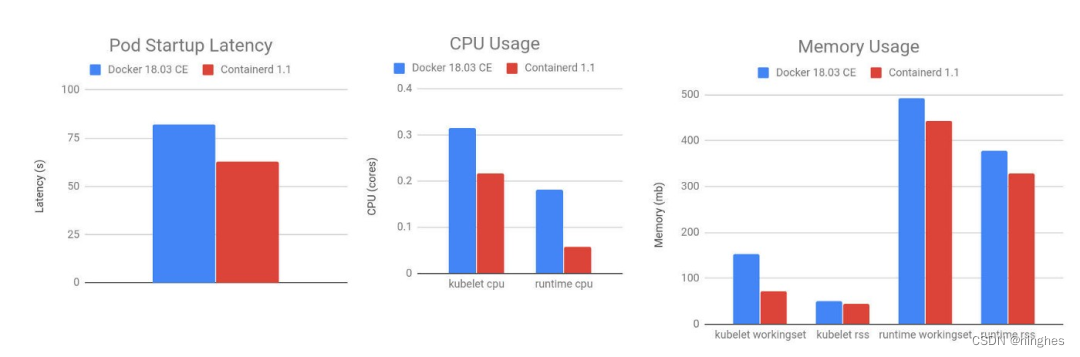
从这些数据可以看出,相比当时的 Docker 18.03,containerd1.1Pod 启动延迟降低了 20% 左右,CPU 使用率降低了 68%,内存使用率降低了 12%,这样可观的性能提升对云厂商来说是非常有诱惑力的。
弃用Docker
2020 年,K8s 1.20 终于正式向 Docker “宣战”:kubelet将弃用 Docker 支持,并将在未来的版本中完全移除。
但由于 Docker 几乎已经成为容器技术的代名词,而且 K8s 已经使用 Docker 多年,该公告在传播时很快“变味了”,“kubelet 将弃用 Docker 支持”被简化为更吸人眼球的东西 “K8s 将弃用”Docker”。
这自然引起了 IT 界的恐慌,“不明真相的群众”纷纷表示震惊:
用了这么久的 Docker 突然不能用了。
为什么 K8s 会这样对待 Docker?
之前对 Docker 的投资会归零吗?现有的大量镜像怎么办?
其实,如果你了解了上面提到的这两个项目CRI,containerd你就会知道,K8s 的这一举动并不奇怪,一切都是“自然”的:其实只是“弃用 dockershim ”,也就是dockershim搬出kubelet,并不是“弃用 Docker”的软件产品。
因此,“弃用 Docker”对 K8s 和 Docker 的影响不大,因为它们都已经将底层改为开源containerd,原有的 Docker 镜像和容器仍然可以正常运行。唯一的变化是K8s绕过了Docker,直接调用Docker内部的containerd。
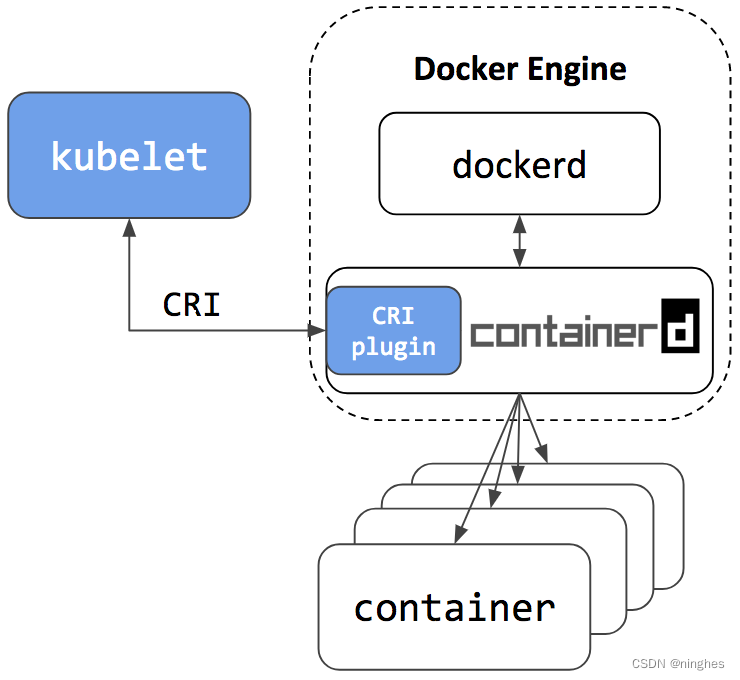
然而,还是会有一些影响。如果K8s直接使用containerd来操作容器,那么它就是一个独立于Docker的工作环境,两者都无法访问对方管理的容器和镜像。换句话说,使用docker ps命令将不会看到K8s中运行的容器。
这对一些人来说可能需要花一点时间来适应并使用新工具crictl,但用于查看容器和镜像的子命令仍然是相同的,例如ps,images等,不难适应(如果你一直在用kubectl管理K8s,这个没有影响)。
K8s 原本计划用一年时间完成“弃用 Docker”的工作,但它确实低估了 Docker 的基础。1.23版本还是没能移除dockershim,只好延期半年。最后,1.24版本从kubelet中删除了dockershim的代码。
从此,Kubernetes 与 Docker 彻底“分道扬镳”。
结语:Docker 的未来
那么,Docker 的未来会怎样呢?云原生时代就没有它的立足之地吗?这个问题的答案显然是否定的。
作为容器技术的奠基人,没有人可以质疑 Docker 的历史地位。虽然 K8s 默认不再绑定 Docker,但 Docker 仍然可以以其他形式的 K8s 共存。
首先,由于容器镜像格式已经标准化(OCI规范,Open Container Initiative),Docker镜像在K8s中仍然可以正常使用,不需要改变原有的开发测试和CI/CD流程。我们仍然可以拉取 Docker Hub,或者编写一个 Dockerfile 来打包应用程序。
其次,Docker是一个完整的软件产品线,不仅仅是containerd,它还包括镜像构建、分发、测试等很多服务,甚至连K8s都内置于Docker Desktop中。
就容器开发的便利性而言,Docker暂时还难以被取代。大多数云原生开发人员可以继续在这个熟悉的环境中工作,使用Docker来开发在K8s中运行的应用程序。
同样,虽然 K8s 不再包含dockershim,Docker 已经接管了这部分代码并构建了一个名为cri-dockerd的项目,该项目也同样工作,将 Docker Engine 适配为 CRI 接口,这样就kubelet可以通过它再次操作Docker,就好像它从来没有发生过一样。
总的来说,Docker虽然在容器编排大战中败下阵来,被K8s挤到了墙角,但依然具有很强的生命力。多年积累的众多忠实用户和大量应用形象是其最大的资本和后盾。足以支持它在另一条不与 K8s 正面交锋的道路上。
对于初学者来说,Docker简单易用,工具链完整,界面友好,市面上很难找到与之相媲美的软件。应该说是入门级学习容器技术和云原生的“最佳选择”。
参考
【K8s 为什么要弃用 Docker?】https://mp.weixin.qq.com/s/qEKyEseD370xWI-2yIyUzg
【Docker与k8s的恩怨情仇】https://www.cnblogs.com/powertoolsteam/p/14980851.html
【k8s为什么会抛弃docker】https://boilingfrog.github.io/2023/01/07/k8s为什么会抛弃docker/
今天的分享就到此结束了