1 机器学习、深度学习、人工智能
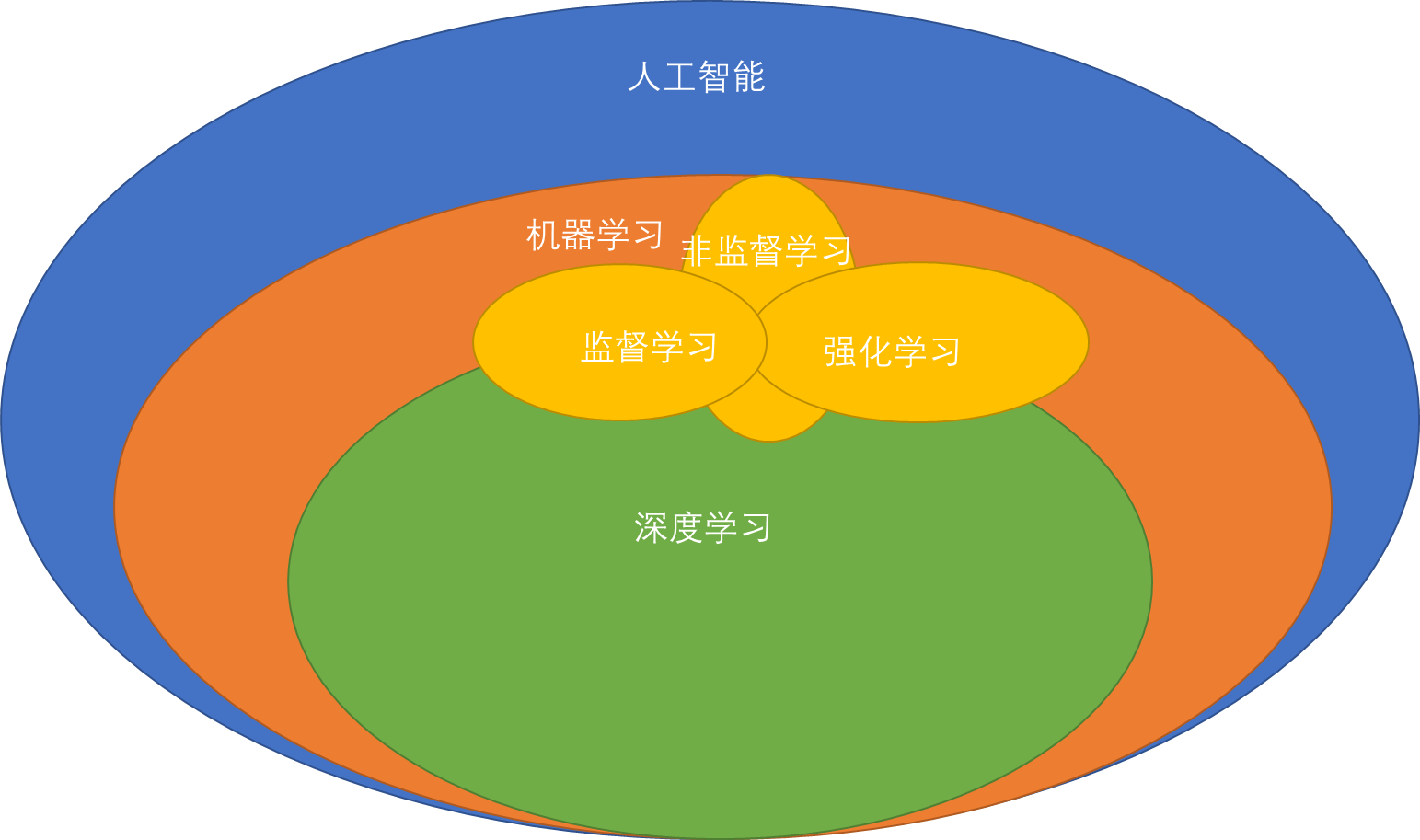
1.1 机器学习
机器学习是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身性能的学科。
基本步骤:获取数据、数据预处理、特征提取、特征选择、推理预测识别(数据预处理、特征提取、特征选择合称为特征表达)
1.2 监督学习
监督学习,是其训练集的数据是提前分好类,带有标签的数据,进行学习到模型以及参数。
1.3 非监督学习
非监督学习,需要将一系列没有标签的训练数据,输入到算法中,需要根据样本之间的相似性对样本集进行分类或者分析。
2 模型相关
2.1 判别模型和生成模型
生成式模型:由数据学习联合概率分布P(X,Y),然后由P(Y|X)=P(X,Y)/P(X),求出概率分布P(Y|X)作为预测的模型,该方法表示了给定输入X与输出Y之间的生成关系。
判别式模型:由数据直接学习决策函数y=f(x)或者条件概率分布P(Y|X)作为预测模型,判别方法关心的是对于给定输入X应预测出什么样的输出Y。
判别式模型方便很多,因为生成式模型要学习一个X,Y的联合分布往往需要很多数据,而判别式模型需要的数据则相对少,因为判别式模型更关注输入特征的差异性。不过生成式既然使用了更多数据来生成联合分布,自然也能够提供更多的信息
2.2 回归模型
回归模型正是表示从输入变量到输出变量之间映射的函数。例如,线性回归代表目标值预期是输入变量的线性组合。
2.3 多层神经网络
由输入层、输出层、隐藏层组成:
- 输入层:接受与处理训练数据集中的各输入变量值
- 隐层:实现非线性数据的线性变换
- 输出层:给出输出变量的分类或预测结果
3 正则化
经常使用的是L1和L2正则化(L2>L1),思想是在损失函数增加一项(正则项)。
3.1 L2正则化
正则项为权重的平方和,公式为:

其中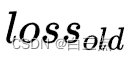 是不添加正则化的损失函数。
是不添加正则化的损失函数。
3.2 L1正则化
正则项为权重的和,公式为:
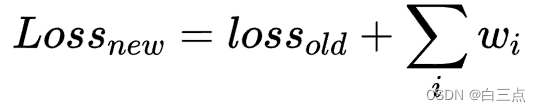
3.3 偏差和方差
偏差是描述模型的期望预测与真实结果之间的偏离程度。偏差大说明模型拟合能力差,此时欠拟合。
方差是描述数据扰动造成的模型性能的变化,即模型在不同数据集上的稳定程度。方差大,说明模型稳定性差,训练集上拟合优秀,测试集上拟合差,则方差大,此时过拟合。
3.4 欠拟合
欠拟合,模型参数学习的过少,模型不能很好地拟合数据
3.5 过拟合
过拟合:把一些不必要的特征过度计算了
4 数据集相关
评估方法就是如何划分数据集,应该要求测试集与训练集之间互斥,用测试集来预测评估模型方法。
4.1 留出法
就是将整个数据集按照某种比例进行划分成训练集和测试集,训练集和测试集比例一般为7:3。
4.2 交叉验证法
将全部数据集S分成 k个不相交的子集,每次从分好的子集中里面,拿出一个作为测试集,其它k-1个作为训练集,根据训练集训练出模型,放到测试集上,得出结果。计算k次求得的结果的平均值,作为该模型的真实结果。
如果k太大,误差估计的偏差很小。但是误差估计的方差很大(由于验证点少)计算时间非常大(试验次数多),会导致过拟合。
如果k太小,计算量小,计算时间短。但是误差估计的方差小(由于验证点多)误差估计的偏差会很大,会导致欠拟合。
4.3 留一法
交叉验证法的一种,每次只留下一个样本做测试集,其它样本做训练集,如果有k个样本,则需要训练k次,测试k次(注意这里是以样本为单位,交叉验证法以子集为单位)。
适合小样本数据
4.4 自助法
留出法每次从数据集D中抽取一个样本加入数据集D’中,然后再将该样本放回到原数据集D中,即D中的样本可以被重复抽取。这样,D中的一部分样本会被多次抽到,而另一部分样本从未被抽到。
5 最大似然学习
已经知道结果,寻找使该结果出现可能性最大的参数的过程。计算步骤如下:
- 写出似然函数
- 对似然函数取对数
- 求导,令导数为0得到似然方程
- 解似然方程得到参数