influxDB聚合类函数
1)count()函数
返回一个(field)字段中的非空值的数量。
SELECT COUNT(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
例子1
计算非空water_level数量
SELECT COUNT(water_level) FROM h2o_feet
结果
name: h2o_feet
time count
1970-01-01T00:00:00Z 15258
说明 water_level这个字段在 h2o_feet表中共有15258条数据。
注意:聚合函数中如果没有指定时间的话,会默认以 epoch 0 (1970-01-01T00:00:00Z) 作为时间。
可以在where 中加入时间条件,如下:
例子2
计算非空值water_level每4天时间间隔里的数量
SELECT COUNT(water_level) FROM h2o_feet WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-09-18T17:00:00Z' GROUP BY time(4d)
结果如下:
name: h2o_feet
--------------
time count
2015-08-17T00:00:00Z 1440
2015-08-21T00:00:00Z 1920
2015-08-25T00:00:00Z 1920
2015-08-29T00:00:00Z 1920
2015-09-02T00:00:00Z 1915
2015-09-06T00:00:00Z 1920
2015-09-10T00:00:00Z 1920
2015-09-14T00:00:00Z 1920
2015-09-18T00:00:00Z 335
这样结果中会包含时间结果。
COUNT() and controlling the values reported for intervals with no data(控制时间间隔内没有值的返回值)
其他的InfluxQL功能时函数间间隔内没有值返回null值,count()用0添加:
fill()到查询里,用 . COUNT(),代替null值返回。用0来代替没有值的间隔数,加入fill()来代替0来输出count()数。
Example:用 fill(none) to 去除0的间隔输出数量
COUNT()不用 fill(none):
SELECT COUNT(water_level) FROM h2o_feet WHERE location = ‘santa_monica’ AND time >= ‘2015-09-18T21:41:00Z’ AND time <= ‘2015-09-18T22:41:00Z’ GROUP BY time(30m)
name: h2o_feet
time count
2015-09-18T21:30:00Z 1
2015-09-18T22:00:00Z 0
2015-09-18T22:30:00Z 0
COUNT() 用 fill(none):
SELECT COUNT(water_level) FROM h2o_feet WHERE location = ‘santa_monica’ AND time >= ‘2015-09-18T21:41:00Z’ AND time <= ‘2015-09-18T22:41:00Z’ GROUP BY time(30m) fill(none)
name: h2o_feet
time count
2015-09-18T21:30:00Z 1
For a more general discussion of fill(), see Data Exploration.
2、DISTINCT()函数
返回一个字段(field)的唯一值。
语法:
SELECT DISTINCT(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
例子1
在level description选择唯一的值
SELECT DISTINCT("level description") FROM h2o_feet
结果
name: h2o_feet
--------------
time distinct
1970-01-01T00:00:00Z between 6 and 9 feet
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z at or greater than 9 feet
这个例子显示level description这个字段共有四个值,然后将其显示了出来,时间为默认时间。
注:聚合函数返回的时代0(1970-01-01t00:00:00z)为时间戳,除非您指定一个下界的时间范围。然后返回下界作为时间戳。
例子2
选择唯一的值在leve description 以location 标签分组
SELECT DISTINCT("level description") FROM h2o_feet GROUP BY location
结果
name: h2o_feet
tags: location=coyote_creek
time distinct
---- --------
1970-01-01T00:00:00Z between 6 and 9 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z at or greater than 9 feetname: h2o_feet
tags: location=santa_monica
time distinct
---- --------
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z between 6 and 9 feet
例子3
聚合函数DISTINCT() 使用count(),以location分组获得level_description的唯一数量
SELECT COUNT(DISTINCT("level description")) FROM h2o_feet GROUP BY location
结果
name: h2o_feet
tags: location = coyote_creek
time count
---- -----
1970-01-01T00:00:00Z 4name: h2o_feet
tags: location = santa_monica
time count
---- -----
1970-01-01T00:00:00Z 33)MEAN() 函数
返回一个字段(field)中的值的算术平均值(平均值)。字段类型必须是长整型或float64。
语法格式
SELECT MEAN(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
例子1
计算water_level的平均值
SELECT MEAN(water_level) FROM h2o_feet
结果
name: h2o_feet
--------------
time mean
1970-01-01T00:00:00Z 4.286791371454075
解释:说明water_level字段的平均值为4.286791371454075时间为默认时间,当然,你也可以加入where条件。
注意:
聚合函数返回的时代0(1970-01-01t00:00:00z)为时间戳,除非您指定一个下界的时间范围。然后他们返回下界的时间戳。
在float64点同一套执行mean()可能会产生稍微不同的结果。
InfluxDB之前不适用的功能,结果在那些小差异排序分。
例子2:
计算wate_level以4天为间隔的平均值
SELECT MEAN(water_level) FROM h2o_feet WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-09-18T17:00:00Z' GROUP BY time(4d)
结果:
name: h2o_feet
--------------
time mean
2015-08-17T00:00:00Z 4.322029861111125
2015-08-21T00:00:00Z 4.251395512375667
2015-08-25T00:00:00Z 4.285036458333324
2015-08-29T00:00:00Z 4.469495801899061
2015-09-02T00:00:00Z 4.382785378590083
2015-09-06T00:00:00Z 4.28849666349042
2015-09-10T00:00:00Z 4.658127604166656
2015-09-14T00:00:00Z 4.763504687500006
2015-09-18T00:00:00Z 4.232829850746268
实战测试:
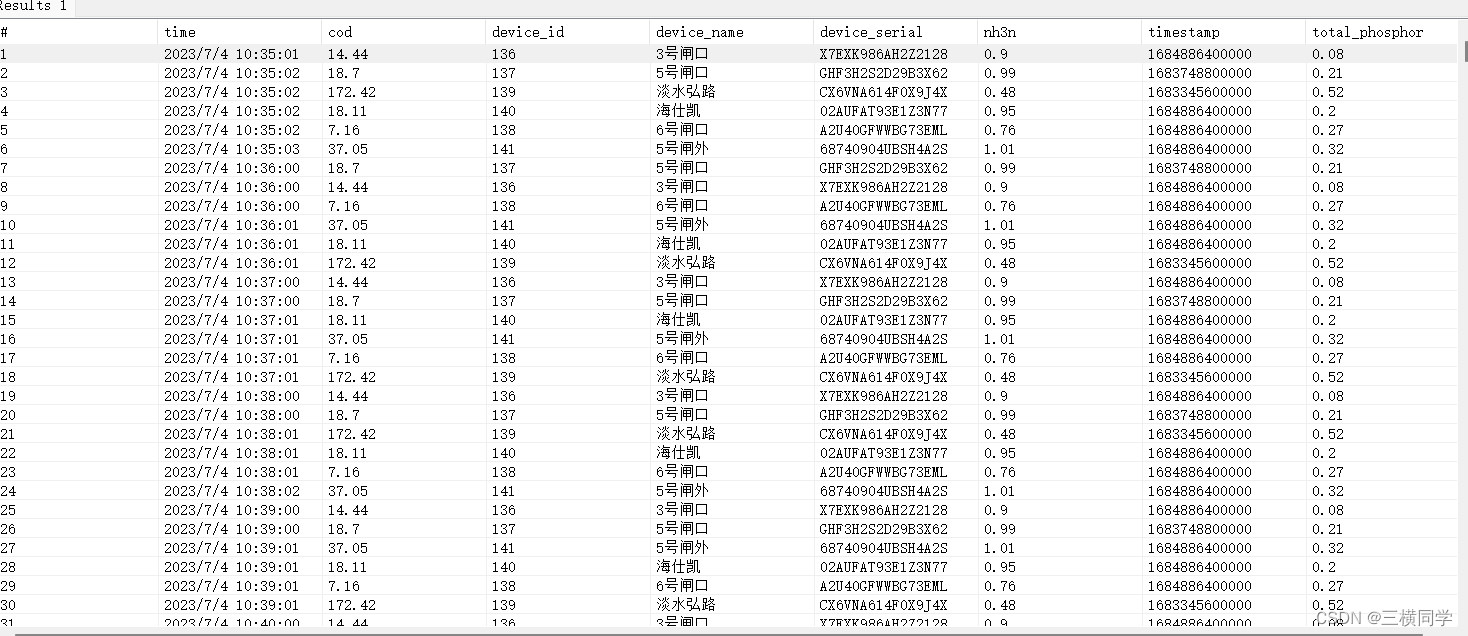
要求:对根据设备id(device_id)查询出上述图片中,某个时间段内对应设备在每小时、每分钟的cod、nh3n、total_phosphor的数据。
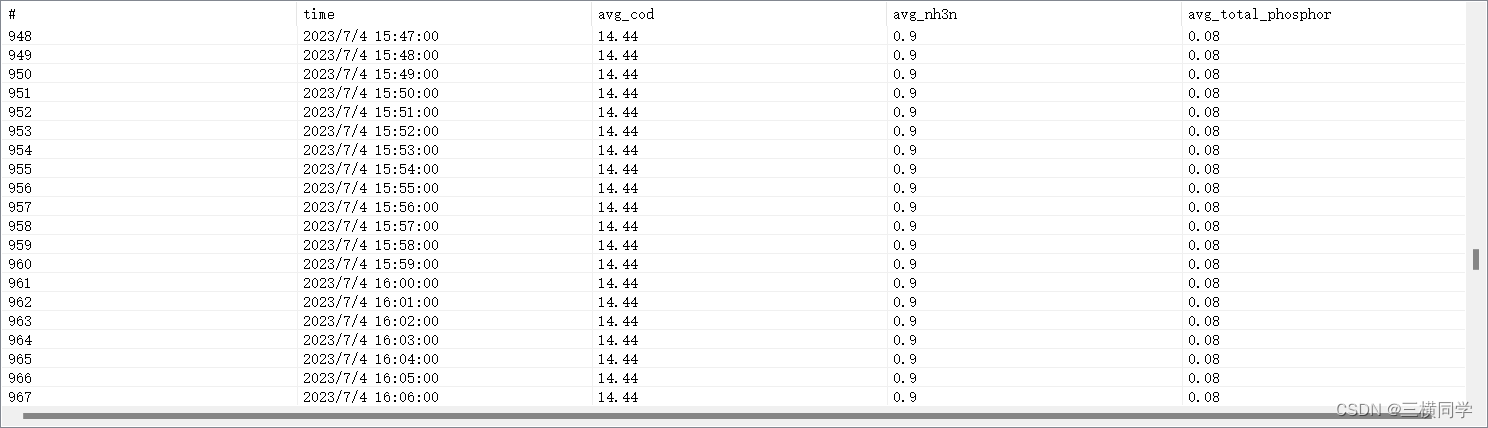
sql实现:SELECT MEAN(*) as avg //用来求平均值
FROM drain_sensor_history_data
where time >= '2023-07-04T00:00:00Z'
AND time <= '2023-07-05T00:00:00Z'
AND device_id = '136'
GROUP BY time(1m) FILL(0)// time(1m)以每分钟对数据进行聚合time(1h) 以小时聚合数据
order by time ASC
结果:
4、MEDIAN()函数
从单个字段(field)中的排序值返回中间值(中位数)。中值是在一组数值中居于中间的数值。字段值的类型必须是长整型或float64格式。
语法:
SELECT MEDIAN(<field_key>) FROM <measurement_name> [WHERE ] [GROUP BY ]
注:median()几乎相当于
PERCENTILE(field_key, 50)
,如果参数集合中包含偶数个数字,函数 MEDIAN 将返回位于中间的两个数的平均值。
中值 中值是一组数中间位置的数;即一半数的值比中值大,另一半数的值比中值小。例如,2、3、3、5、7 和 10 的中值是 4
例子1
选择water_level的中间值
PERCENTILE(field_key, 50)SELECT MEDIAN(water_level) from h2o_feet
结果:
name: h2o_feet
--------------
time median
1970-01-01T00:00:00Z 4.124
解释:
说明表中 water_level字段的中位数是 4.124
==注:聚合函数返回的时代0(1970-01-01t00:00:00z)为时间戳,除非您指定一个下界的时间范围。然后返回下界作为时间戳。 ==
例子2:
选择时间在2015年8月18日和8月18日30分,以location分组water_level的中间值
SELECT MEDIAN(water_level) FROM h2o_feet WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-08-18T00:36:00Z' GROUP BY location
结果:
name: h2o_feet
tags: location = coyote_creek
time median
---- ------
2015-08-18T00:00:00Z 7.8245name: h2o_feet
tags: location = santa_monica
time median
---- ------
2015-08-18T00:00:00Z 2.0575
5)SPREAD()函数
返回字段的最小值和最大值之间的差值。数据的类型必须是长整型或float64。
语法:
SELECT SPREAD(<field_key>) FROM <measurement_name> [WHERE ] [GROUP BY ]
例子1
计算water_level的最小值 与最大值 之间差
SELECT SPREAD(water_level) FROM h2o_feet
结果
name: h2o_feet
--------------
time spread
1970-01-01T00:00:00Z 10.574
注意:
聚合函数返回的时代0(1970-01-01t00:00:00z)为时间戳,除非您指定一个下界的时间范围。然后他们回到下界的时间戳。
在float64点同一套执行spread()可能会产生稍微不同的结果。InfluxDB之前不适用的功能,结果在那些小差异排序分。
例子2
计算water_level的最小值 与最大值差,以30分钟间隔,指定location为
santa_monica,和一个时间范围
SELECT SPREAD(water_level) FROM h2o_feet WHERE location = 'santa_monica' AND time >= '2015-09-18T17:00:00Z' AND time < '2015-09-18T20:30:00Z' GROUP BY time(30m)
结果:
name: h2o_feet
--------------
time spread
2015-09-18T17:00:00Z 0.16699999999999982
2015-09-18T17:30:00Z 0.5469999999999997
2015-09-18T18:00:00Z 0.47499999999999964
2015-09-18T18:30:00Z 0.2560000000000002
2015-09-18T19:00:00Z 0.23899999999999988
2015-09-18T19:30:00Z 0.1609999999999996
2015-09-18T20:00:00Z 0.16800000000000015
6)SUM()函数
返回一个字段中的所有值的和。字段的类型必须是长整型或float64。
语法:
SELECT SUM(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
例子1
计算water_level的所有值的和
SELECT SUM(water_level) FROM h2o_feet
结果
name: h2o_feet
--------------
time sum
1970-01-01T00:00:00Z 67777.66900000002
注意:
聚合函数返回的时代0(1970-01-01t00:00:00z)为时间戳,除非您指定一个下界的时间范围。然后他们回到下界的时间戳。
在float64点同一套执行sum()可能会产生稍微不同的结果。InfluxDB之前不适用的功能,结果在那些小差异排序分。
例子2 计算以5天为分组,water_level的和SELECT SUM(water_level) FROM h2o_feet WHERE time >= '2015-08-18T00:00:00Z' AND time < '2015-09-18T17:00:00Z' GROUP BY time(5d)
结果:
--------------
time sum
2015-08-18T00:00:00Z 10334.908999999983
2015-08-23T00:00:00Z 10113.356999999995
2015-08-28T00:00:00Z 10663.683000000006
2015-09-02T00:00:00Z 10451.321
2015-09-07T00:00:00Z 10871.817999999994
2015-09-12T00:00:00Z 11459.00099999999
2015-09-17T00:00:00Z 3627.762000000003





