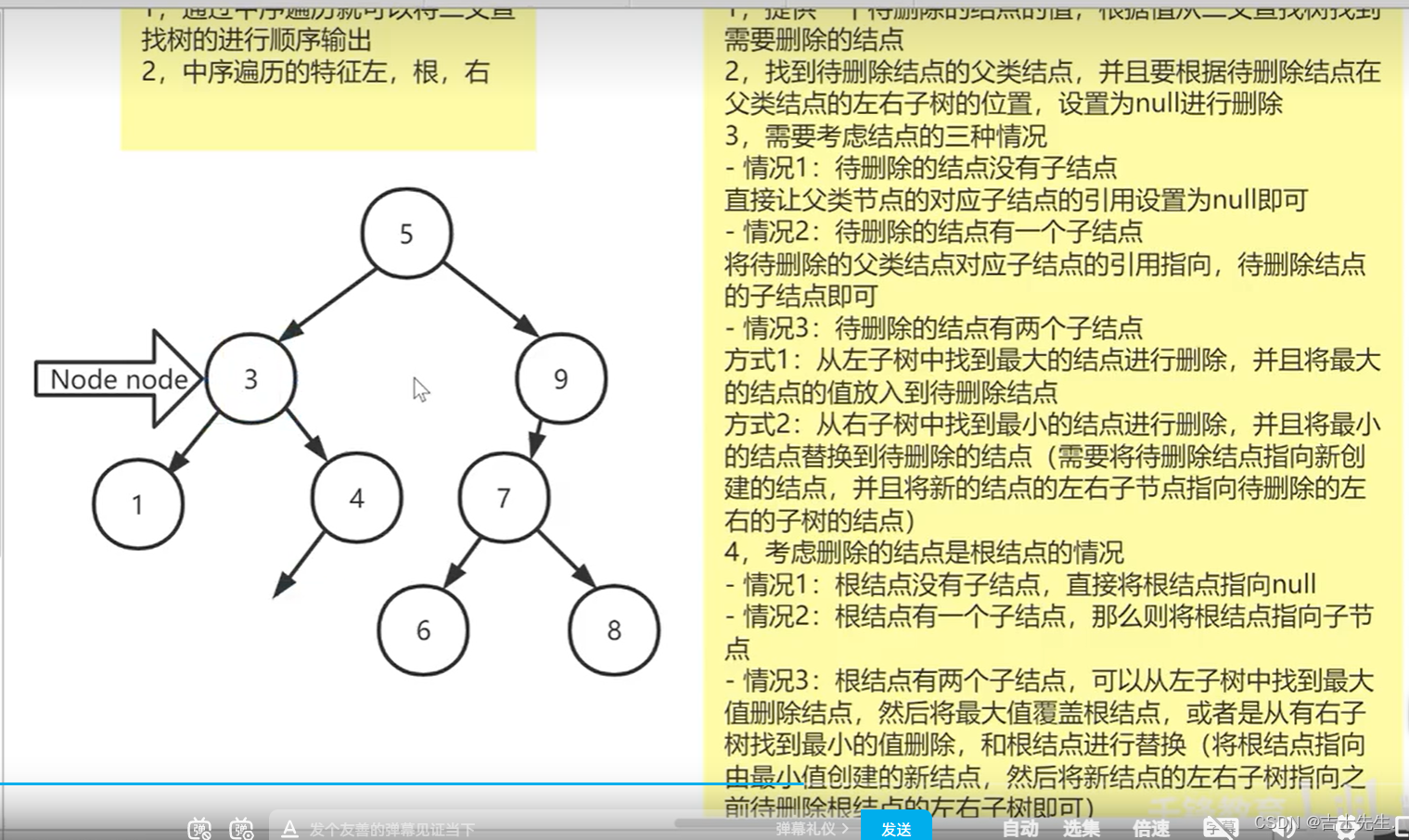
Redis
- 是一个NSQL数据库
- 主要存储的数据是缓存(内存)
- 数据的结构是key-value
- 适合用来做一些需要用到中央缓存的业务数据
- 提供了过期key的处理
- 还可以搭建集群提供高可用
Redis安装
1下载redis源码
wget http://download.redis.io/releases/redis-6.0.5.tar.gz
2安装redis
tar zxf redis-6.0.5.tar.gz //解压
cd redis-6.0.5
//不需要配置参数 不需要执行./configure
make && make install//编译&&安装
注意:新版的redis需要gcc较高版本 需要先安装或则升级gcc版本再进行make
安装:
yum -y install gcc
升级:
安装centos-release-scl
yum install centos-release-scl
安装 devtoolset
yum install devtoolset-9-gcc*
激活:
scl enable devtoolset-9 bash
Redis启动与连接
可以通过src目录下面的 redis-server 来启动服务器,通过redis-cli来连接服务器,需要在命令前加上./
默认的启动都是在前台启动,并且启动服务器绑定的端口默认是6379,绑定的ip默认是127.0.0.1
如果需要在
后端启动,以及改变ip或则端口允许其他方式连接,我们需要去修改配置文件
//在自定义的config下//1后台启动redis服务./../src/redis-server 6370.conf//2连接redis./../src/redis-cli//3输入密码 auth root123
在windows环境下连接
//在redisbin64下(F:)
redis-cli.exe -h 192.168.XX.XX -p 6379
一下几个常用的启动配置文件参数:
- bind 0.0.0.0 ## 配置绑定的ip,4个0就是所有IP
- protected-mode yes ##开启保护模式,只允许bind上面设置的ip连接
- port 6379 ## 端口
- daemonize yes ## 开启后端启动
- pidfile /var/run/redis_6379.pid ##存放启动之后进程号的文件
- loglevel notice ##日志级别
- logfile “log/6379.log” ## 存放日志的文件
Redis常用命令
set 设置键值对
del 删除数据
dbsize 查看数据数量
info 查看服务器当前各种状态
expire 设置过期时间(秒)
ttl 查看当前过期时间
persist 中断过期
flushdb 清空当前库
flushall 清空所有库
keys 搜索key
type 查看某key的数据类型
Object encoding 查看某key的数据类型的底层编码格式
Redis有16个库,从0–15,默认是0号库,库的选择:select 库号;不同库的数据不影响.
select 0-15 选择库
Redis的数据类型
-
string
set 设置一个字符串
get 获取一个字符串
mset 设置多个
mget 获取多个
如果设置的字符串的值是数值,可以用命令来进行加减操作
incr(增1)、incrby(增多) 、decr、decrby、incrbyfloat
字符串在实际项目当中更多的存JSON格式的字符串,但是序列化以及修改对象参数性能不好
-
list
lpush key value 将一个或多个值 value 插入到列表 key 的表头(最左边)
rpush key value 将一个或多个值 value 插入到列表 key 的表尾(最右边)
lpop key 移除并返回列表 key 的头(最左边)元素。
rpop key 移除并返回列表 key 的尾(最右边)元素。
lrange key start stop 返回列表 key 中指定区间内的元素,查询所有的stop为-1即可
lrem key count value 根据count值移除列表key中与参数 value 相等的元素
count > 0 : 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count 。count < 0 : 从表尾开始向 表头搜索,移除与 value 相等的元素,数量为 count 的绝对值。count = 0 : 移除表中所有与 value 相等的 值。
lindex key index 返回列表 key 中,下标为 index 的元素
注意: 如何实现队列与栈?
lpush与rpop实现队列的数据结构
lpush与lpop实现栈的数据结构
lpush key value rpop key 先进先出 队列
lpush key value lpop key 先进后出 栈
3.set
sadd 添加
srem 删除
smembers 得到所有数据
scard 得到长度
4.zset
zadd key score value 添加一个元素,每个元素有一个分值绑定
zrange key start stop 查看某些元素或则所有元素,start与stop类似于list(分数由小到大排列)
zrevrange key start stop 分数由大到小查看
zincrby key crenment value 对某个元素的分数进行加减操作
zrem key value 删除某元素
5.hash(相当于map)、
hash表存储的是多个键值对,可以用来储存对象数据类型
hset key field value 添加或则修改一个属性的值
hdel key filed 删除属性
hget key field 获取某个属性的值
hgetall key -raw 获取所有的键值对
hincrby key field crement 对某一个整数类型的属性进行加减操作
hmset key filed1 valu1 field2 vlaue2 。。。。 同时设置多个属性
hmget key filed1 filed2.。。。获取多个属性的值
以上是常见的5个redis里面的数据类型
redis存储键值对在命名上也是需要一些规范的:在命名的时候一般会多多个单词组合或则加上前后缀的情况
这种情况分割符号使用“:”,例如:woniu:demo:user:1
Springboot连接 Redis
-
导包
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency> -
配置连接
spring:redis:host: 192.168.40.226port: 6379 -
在类里面注入模板对象
//每个不同类型的操作都封装在独立的一个操作对象里面,所以需要先srt.opsForValue()得到操作对象再 //调用方法进行使用,如果是统一的操作直接调用srt的方法 @Autowired private StringRedisTemplate srt;Springboot的模版对象
RedisTemplate<?,?>是用来操作的模版对象,在服务器启动的时候,框架会自动注入两个模板对象,一个是:
RedisTemplate<String,String>(有一个子类StringRedisTemplate),该类的序列化方式都是用得字符串,另外一个是:RedisTemplate<Object,Object>,该类的序列化方式都是用得jdk的自动序列化,所以这个对象再实际运行中不合适。我们为了更好的对对象与json的转换存储,可以手动创建RedisTemplate对象,规定需要的泛型,设置相关的序列化方式使其变得更好用:
@Configuration public class RedisConfig {//把框架自动生成的Redis连接工厂注入进来@Autowiredprivate RedisConnectionFactory redisConnectionFactory;/*手动创建一个RedisTemplate注入到容器中*/@Bean("redisJsonTemplate")public RedisTemplate<String, Object> createRedisTemplate() {RedisTemplate<String, Object> rt = new RedisTemplate<>();//设置连接工厂rt.setConnectionFactory(redisConnectionFactory);//设置4个地方各自的序列化方式rt.setKeySerializer(RedisSerializer.string());rt.setHashKeySerializer(RedisSerializer.string());rt.setValueSerializer(RedisSerializer.json());rt.setHashValueSerializer(RedisSerializer.string());return rt;} }上面配置成功之后,就可以注入自己创建的这个模版对象来进行操作
@Autowired private RedisTemplate<String, Object> rto;Redis密码
可以设置一个配置参数来加入密码认证
requirepass 密码这样我们在客户端连接进去之后需要选输入密码认证才能正常使用
auth 密码Springboot里面也需要配置password参数
Redis持久化(理论很重要)
-
RDB
它是把内存整个数据一次性的压缩成二进制存储到后缀为RDB的文件里面,
1)可以手动通过命令执行存储过程
save: 用来手动执行保存,但是不会开子进程,跟其他命令在一个通道,所以很容易导致命令执行
阻塞。
bgsave: 用来手动执行保存,但是会开子进程执行,不会阻塞其他的命令。
2)可以通过配置参数来设置条件执行存储过程
在参数文件里面可以通过设置:
save 操作次数 秒
这样的参数来进行自动RDB的持久化,到达上面的操作要求就会触发一次bgsave
save参数可以同时存在多个,如果要关闭掉自动的RDB存储就是把所有的save配置去掉
RDB对数据的压缩比较小,所以加载数据块,用来做数据备份、加载、移植是比较快的,但是对于持久化
而言性能不好,就会导致数据的实时性不高。
-
AOF
这种方式会以一个后缀为aof的文件来存储redis里面执行的命令,也可以说是日志记录
当操作redis的时候命令会被记录到文件,在启动服务器的时候,会加载aof里面的所有命令然后全部执行
来恢复数据。
在默认的情况之下,这种方式是关闭的,我们需要通过配置文件参数把它打开
#打开aof模式 appendonly yes #设置存储的文件名 appendfilename "6379.aof" #设置存储的时机,现在是每秒 appendfsync everysec这种方式随着时间的推移,文件命令会越来越多,这样就会导致在加载恢复的时候一次性执行过多命令加载速度慢,redis提供了aof重写机制,来优化日志文件,把一些冗余的命令去掉:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hc7k6S5O-1640589133204)(E:\Markdown\Typora\MarkdownImage\1.png)]
我们可以通过配置以及手动执行命令来进行aof重写
命令: bgrewriteaof
配置:
#文件大小的增长率 auto-aof-rewrite-percentage 100 #第一次进行重写的最小大小 auto-aof-rewrite-min-size 64mb注意: 在6.x的版本以后,aof重写进一步做了优化,进行重写之后的命令数据会编程RDB格式的二进制数据进一步优化文件大小,提高加载速度。重写之后后面的命令追加更以前一样,所以当前的aof文件具备两种格式的数据,一种就是二进制数据,另外一种就是命令(混编模式),这个也可以通过配置来进行指定是否需要,默认是混编的记录模式:
#yes改成no就回到以前的重写方式而不是混编 aof-use-rdb-preamble yes
-
两种方式都可以同时开启,互不影响,但是在启动加载的时候不会同时加载,会优先选择aof,只要aof不存在的时候再去加载RDB
-
两种方式对比
- RDB保存的是二进制数据,aof保存的是命令
- RDB每次都是全数据保存,aof是数据追加
- RDB实时性不高,保存性能占用较大,aof实时性相对较高,保存性能较快
-
怎么选择?
一般来说,我们会关闭RDB自动保存,用手动的方式再特定的时间来进行数据备份
会打开aof老保证数据的持久化
Redis集群
集群就是为了防止单节点故障,可以把Redis部署在多台服务器上共同对项目提供服务:
-
主从复制模式
提供一个中心的主节点,可以让很多的其他节点,称为从节点来连接主节点,并且复制主节点的所有数据,在复制的时候会清空自身的数据,复制的方式第一次跟后续的数据改动的复制不一样,第一次称为全量复制,主节点会把数据打包成RDB文件进行传输,从节点加载RDB文件,如果是后续的数据改动的复制主节点根据偏移量计算出改动的数据进行部分传输。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YNkL55P3-1640589133205)(E:\Markdown\Typora\WorkSpace\Java基础学习\redis\3.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AZsXtsza-1640589133205)(E:\Markdown\Typora\WorkSpace\Java基础学习\redis\4.png)]
主从复制有两种实现方式:
1) 通过命令让从节点去链接主节点: replicaof host port 2)把命令配置到参数里面,启动自动连接
主从复制有一些弊端,
1) 主节点不能出问题。因为只有主节点才能写数据
2) 内存利用率不高,所有数据都是同步共同复制存在的
3) 主节点出问题之后只能人工检查恢复
-
哨兵模式(sentinel)
sentinel是一种独立的服务,用来监控一个主从集群里面主节点故障情况,如果主节点发生故障,超过指定数量的sentinel都认为故障存在的时候会在剩下的从节点里面选举一个新的主节点,让其他从节点进行新主节点的连接,当原来的主节点恢复之后也会自动连接到新的主节点上
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eof0NSTT-1640589133205)(E:\Markdown\Typora\WorkSpace\Java基础学习\redis\5.png)]
sentinel的服务启动有自己的配置跟命令,配置如下:
port 26379 daemonize yes pidfile /var/run/redis-sentinel-26379.pid logfile "26379.log" dir /tmp #指定主节点以及名字以及需要几个哨兵服务共同确认 sentinel monitor mymaster 127.0.0.1 6379 2 #主节点故障之后最长连接等待时间 sentinel down-after-milliseconds mymaster 30000 #新主从关系,从节点向主节点做全量复制共同进行的数量 sentinel parallel-syncs mymaster 1 #故障恢复的超时时间 sentinel failover-timeout mymaster 180000 #脚本记录 sentinel deny-scripts-reconfig ye启动需要用到redis-sentinel sentinel.conf
-
cluster
去中心节点的集群,所有的节点都是主节点,都能够进行数据的读取操作,数据分散存储在不同的节点上面,每一个节点都有相应的hash槽位分布,cluster集群总共提供了16384个hash槽位,然后在创建集群的时候回去指定某一个节点分配的槽位段是那一段,比如节点1分配 0- 5600 等等,有数据存入的时候会通过该数据的key的hash值来计算出一个对应的槽位值,比如是2800,这个时候改数据就只能存放包含在2800这个槽位的节点上面。每一个节点还可以配置自己的从节点做备用,当该集群节点出现故障以后,备用的从节点可以顶上代替它的位置。
创建cluster节点首先我们需要改变redis服务区的启动方式,还需要指定集群参数的存放文件:
cluster-enabled yes cluster-config-file nodes-6379.conf然后启动所有需要构建集群的节点以及它们的从节点,启动成功之后执行构建集群的命令:
redis-cli --cluster create 192.168.40.226:6379 192.168.40.226:6380 192.168.40.226:6381 192.168.40.226:6382 192.168.40.226:6383 192.168.40.226:6384 --cluster-replicas 1 //后面参数的数值1是表示每个集群节点下面挂在1个从节点特点:
- 数据分散存储,内存利用率高
- 由于有备份从节点的存在所有在执行过程中有节点故障也能自动恢复
- 由于数据分散,所以在分布式的一些数据同步上面可能存在风险
Redis的命令单线程
Redis的所有的命令执行都是单线程的,也就是排队执行,所以在执行命令的时候是线程安全的。
在Redis6.x版本之后,从连接开始到最终执行其实多多线程的,除了执行命令这一步还是单线以外,其他执行步骤都是多线程处理进一步加强处理的效率
Redis的内存溢出策略
可以通过Maxmemory 来设置redis的最大内存使用量
如果超过了,有新的数据存储就会去删除相应的数据来腾出内存空间给新的数据,也可以不删除,禁止新数据进入
可以通过maxmemory-policy来设置溢出处理的策略
1.volatile-lru 设定了超时时间数据,之后采用LRU算法进行删除.
2.allkeys-lru 全部数据,采用LRU算法进行内存数据的优化.
3.volatile-lfu 设定了超时时间的数据,采用LFU算法进行删除
4.allkeys-lfu 所有的数据采用LFU算法实现数据删除.
5.volatile-random 为设定超时时间的数据采用随机算法.
6.allkeys-random 所有数据采用随机算法实现删除.
7.volatile-ttl 将所有设定了超时时间的数据,利用ttl方式进行排序,将还没有超时的数据提前删除.
8.noeviction (默认策略)不采用任何的算法删除数据.如果将来内存溢出则报错返回
Redis过期键的删除策略
删除数据可以有三种策略
- 过时删除:每个有过期时间的key都去创建一个监听器来监控改key的时间,到点立即删除,实时性很高,但是资源占用过大。
- 定时删除:开一个定时器,不断的去执行查看所有带过期时间的key是否需要删除,资源占用少,但是实时性不高。
- 惰性删除:适应数据之前会判断是否有过期时间以及是否已经过期,如果过期就删除。
Redis采用的是上面的2+3策略同时开启,有一个参数hz,用来配置定时任务的频率,不能过大
Redis如何处理缓存穿透问题
-
缓存穿透
就是缓存没有的数据,在查询的时候穿过了缓存,所有的请求都去数据库了,如果数据库也没有,这就会导致后续该请求一直访问到数据库
1、在查不到数据之后,缓存里面存放一个空值数据
2、布隆过滤器
-
缓存雪崩
如果redis服务器出现问题,或者内存过大,溢出等等导致所有的请求都去数据库,整个数据库压力变大,其实处理缓存雪崩就是设置redis服务器高可用
1、Redis做集群
2、尽量给key设置过期时间
3、可以做一些压力测试
Redis常见面试问题
- Redis的使用场景?
- Redis的持久化特点?
- aof的重写是什么?
- 如何用Redis来实现队列、栈等数据结构(会结合逻辑程序来阐述实现消息队列的过程)
- Redis集群方案的特点?
- Redis内存溢出策略以及过期键的删除策略
- 缓存雪崩与穿透
-
-
2、布隆过滤器
2. 缓存雪崩如果redis服务器出现问题,或者内存过大,溢出等等导致所有的请求都去数据库,整个数据库压力变大,其实处理缓存雪崩就是设置redis服务器高可用1、Redis做集群2、尽量给key设置过期时间3、可以做一些压力测试### Redis常见面试问题1. Redis的使用场景?2. Redis的持久化特点?3. aof的重写是什么?4. 如何用Redis来实现队列、栈等数据结构(会结合逻辑程序来阐述实现消息队列的过程)5. Redis集群方案的特点?6. Redis内存溢出策略以及过期键的删除策略7. 缓存雪崩与穿透