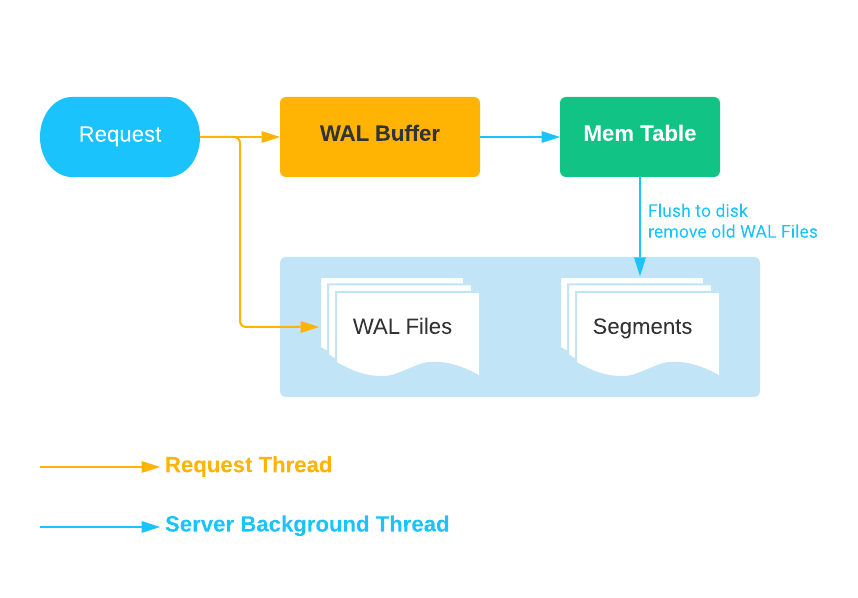
目录
概述
准备
所需模块
涉及知识点
运行效果
完成爬虫
1. 分析网页
2. 爬虫代码
概述
爬取妹子图网的美女图片。
准备
所需模块
- time
- requests
- lxml
涉及知识点
- python基础
- requests模块基础
- xpath表达式基础
运行效果
控制台打印:

电脑本地文件:
完成爬虫
1. 分析网页
打开妹子图网,按F12分析网页
第一页的URL是:https://www.meizitu.com/a/list_1_1.html
第二页的URL是:https://www.meizitu.com/a/list_1_2.html
第三页的URL是:https://www.meizitu.com/a/list_1_3.html
故分析三者可以得出:
# 第1页:https://www.meizitu.com/a/list_1_1.html
# 第2页:https://www.meizitu.com/a/list_1_2.html
# 第3页:https://www.meizitu.com/a/list_1_3.html
# 故可以推断出URL公式:url="https://www.meizitu.com/a/list_1_"+page_index+".html"
# 其中page_index指的是页码获取每一页的URL后,接着是获取该页图片的超链接,然后通过该超链接进入具体的页面下载图片。

这些超链接可以通过xpath表达式进行提取。
接下来进入具体的页面:

这标题和超链接也可以xpath表达式进行提取。
2. 爬虫代码
import timeimport requests
from lxml import etree# 爬虫实战:爬取妹子图网的图片# 第1页:https://www.meizitu.com/a/list_1_1.html
# 第2页:https://www.meizitu.com/a/list_1_2.html
# 第3页:https://www.meizitu.com/a/list_1_3.html
# 故可以推断出URL公式:url="https://www.meizitu.com/a/list_1_"+page_index+".html"
# 其中page_index指的是页码page_index = 1 # 这里只下载了第一页相关的图片,如需下载更多可以使用for循环
# 请求头
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
# 组装请求的URL
url = "https://www.meizitu.com/a/list_1_" + str(page_index) + ".html"
# 发送请求,获取响应的HTML源代码
response = requests.get(url, headers=header).content.decode("gb2312")
# 将源码字符串转换成HTML对象
html = etree.HTML(response)
# 通过xpath表达式提取页面中通往图片详情页面的超链接,返回一个列表
image_link_all_list = html.xpath("//li[@class='wp-item']/div[@class='con']/div[@class='pic']/a/@href")
# 循环列表中的图片详情页面的超链接
for image_link in image_link_all_list:# 获取图片详情页面的HTML源码response_image_detail = requests.get(image_link).content# 将源码字符串转换成HTML对象html_image_detail = etree.HTML(response_image_detail)# 获取每张图片的下载链接image_link_detail_list = html_image_detail.xpath("//div[@id='picture']//img/@src")# 获取每张图片的标题image_name_detail_list = html_image_detail.xpath("//div[@id='picture']//img/@alt")# 条件判断if len(image_link_detail_list) == len(image_name_detail_list):# 循环图片下载链接for i in range(0, len(image_name_detail_list)):# 请求每张图片的数据data = requests.get(image_link_detail_list[i]).content# 下载提示print("正在下载图片" + image_name_detail_list[i] + ".jpg中......")# 将图片下载保存到电脑本地with open(r"C:/Users/Administrator/Pictures/images/" + image_name_detail_list[i] + ".jpg","wb") as file_object:# 写入数据file_object.write(data)# 缓一缓time.sleep(0.5)