[POI2006] OKR-Periods of Words
题面翻译
对于一个仅含小写字母的字符串 a a a, p p p 为 a a a 的前缀且 p ≠ a p\ne a p=a,那么我们称 p p p 为 a a a 的 proper 前缀。
规定字符串 Q Q Q(可以是空串)表示 a a a 的周期,当且仅当 Q Q Q 是 a a a 的 proper 前缀且 a a a 是 Q + Q Q+Q Q+Q 的前缀。
例如 ab 是 abab 的一个周期,因为 ab 是 abab 的 proper 前缀,且 abab 是 ab+ab 的前缀。
求给定字符串所有前缀的最大周期长度之和。
题目描述
A string is a finite sequence of lower-case (non-capital) letters of the English alphabet. Particularly, it may be an empty sequence, i.e. a sequence of 0 letters. By A=BC we denotes that A is a string obtained by concatenation (joining by writing one immediately after another, i.e. without any space, etc.) of the strings B and C (in this order). A string P is a prefix of the string !, if there is a string B, that A=PB. In other words, prefixes of A are the initial fragments of A. In addition, if P!=A and P is not an empty string, we say, that P is a proper prefix of A.
A string Q is a period of Q, if Q is a proper prefix of A and A is a prefix (not necessarily a proper one) of the string QQ. For example, the strings abab and ababab are both periods of the string abababa. The maximum period of a string A is the longest of its periods or the empty string, if A doesn’t have any period. For example, the maximum period of ababab is abab. The maximum period of abc is the empty string.
Task Write a programme that:
reads from the standard input the string’s length and the string itself,calculates the sum of lengths of maximum periods of all its prefixes,writes the result to the standard output.
输入格式
In the first line of the standard input there is one integer k k k ( 1 ≤ k ≤ 1 000 000 1\le k\le 1\ 000\ 000 1≤k≤1 000 000) - the length of the string. In the following line a sequence of exactly k k k lower-case letters of the English alphabet is written - the string.
输出格式
In the first and only line of the standard output your programme should write an integer - the sum of lengths of maximum periods of all prefixes of the string given in the input.
样例 #1
样例输入 #1
8
babababa
样例输出 #1
24
数据范围与提示
对于全部数据, 1 < k < 1 0 6 1\lt k\lt 10^6 1<k<106。
人话翻译:
给定一个字符串A,求他所有前缀B(包括A=B)的最大周期,周期即B的前缀C最长,C要满足B是CC的字串。实例:
A B A B A B A B 的所有前缀有: − − − − − − − − − 周期为 − − − 长度 ABABABAB的所有前缀有:---------周期为---长度 ABABABAB的所有前缀有:−−−−−−−−−周期为−−−长度
A − − − − − − − − − − − − − − − − − − − − 无 − − − − − 0 A--------------------无-----0 A−−−−−−−−−−−−−−−−−−−−无−−−−−0
A B − − − − − − − − − − − − − − − − − − − 无 − − − − − 0 AB-------------------无-----0 AB−−−−−−−−−−−−−−−−−−−无−−−−−0
A B A − − − − − − − − − − − − − − − − − − A B − − − − − 2 ABA------------------AB-----2 ABA−−−−−−−−−−−−−−−−−−AB−−−−−2
A B A B − − − − − − − − − − − − − − − − − A B − − − − − 2 ABAB-----------------AB-----2 ABAB−−−−−−−−−−−−−−−−−AB−−−−−2
A B A B A − − − − − − − − − − − − − − − − A B A B − − − − 4 ABABA----------------ABAB----4 ABABA−−−−−−−−−−−−−−−−ABAB−−−−4
A B A B A B − − − − − − − − − − − − − − − A B A B − − − − 4 ABABAB---------------ABAB----4 ABABAB−−−−−−−−−−−−−−−ABAB−−−−4
A B A B A B A − − − − − − − − − − − − − − A B A B A B − − − 6 ABABABA--------------ABABAB---6 ABABABA−−−−−−−−−−−−−−ABABAB−−−6
A B A B A B A B − − − − − − − − − − − − − A B A B A B − − − 6 ABABABAB-------------ABABAB---6 ABABABAB−−−−−−−−−−−−−ABABAB−−−6
因此输出结果为 2 + 2 + 4 + 4 + 6 + 6 = 24 因此输出结果为2+2+4+4+6+6=24 因此输出结果为2+2+4+4+6+6=24
怎么求这些周期长度呢?KMP的精髓也在此,附图(其中next数组就是之前模板中提到的p数组,含义是相同的)
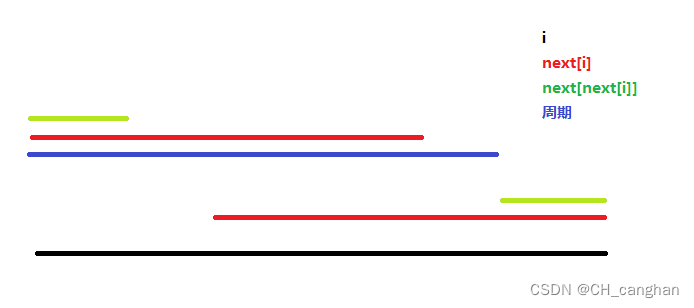
明显其中的蓝线是黑线的周期
那么这个题目就变得极其简单了,只需要求出 i − n e x t [ n e x t [ i ] ] i-next[next[i]] i−next[next[i]],ans累加即可
很简单就可以得到实现代码:
#include<bits/stdc++.h>
using namespace std;
const int N=1e7+999;
int p[N],n,len,ans=0;
char a[N];
void pre(){//KMP模板int j=0;p[1]=0;for(int i=1;i<n;i++){while(j>0&&a[i+1]!=a[j+1])j=p[j];if(a[i+1]==a[j+1])j++;p[i+1]=j;}
}
int main(){cin>>n;scanf("%s",a+1);pre();for(int i=1;i<=n;i++){int j=i;while(p[j])j=p[j];ans+=i-j;}cout<<ans;return 0;
}
但是!这样是不够的,会得到以下结果

算法原理是肯定没有错的,但是问题在哪?
注意k的范围
对于全部数据, 1 < k < 1 0 6 1\lt k\lt 10^6 1<k<106。
那么对于我们在累加的ans可能会超出int的范围
十年OI一场空,不开long long 见祖宗
加上longlong
#include<bits/stdc++.h>
using namespace std;
const int N=1e7+999;
int p[N],n;
long long int ans=0;
char a[N];
void pre(){int j=0;p[1]=0;for(int i=1;i<n;i++){while(j>0&&a[i+1]!=a[j+1])j=p[j];if(a[i+1]==a[j+1])j++;p[i+1]=j;}
}
int main(){cin>>n;scanf("%s",a+1);pre();for(int i=1;i<=n;i++){int j=i;while(p[j])j=p[j];if(p[i]!=0)p[i]=j; ans+=i-j;}cout<<ans;return 0;
}
信心十足的交上代码,

哎?不是,啊?KMP超时了?FFFF
咳,随着数据变大,查找 n e x t [ n e x t [ ] ] next[next[]] next[next[]]的时间就变得难以接受,我们可以通过记忆化的方式更改 n e x t next next数组,原理类似于并查集的优化
实现代码(AC)
#include<bits/stdc++.h>
using namespace std;
const int N=1e7+999;
int p[N],n;
long long int ans=0;
char a[N];
void pre(){int j=0;p[1]=0;for(int i=1;i<n;i++){while(j>0&&a[i+1]!=a[j+1])j=p[j];if(a[i+1]==a[j+1])j++;p[i+1]=j;}
}
int main(){cin>>n;scanf("%s",a+1);pre();for(int i=1;i<=n;i++){int j=i;while(p[j])j=p[j];if(p[i]!=0)p[i]=j;//记忆化,否则会有TLE。 ans+=i-j;}cout<<ans;return 0;
}
附封面