一:【numpy数组】
1.1为什么要学习numpy
1.快速 2.方便 3.科学计算的基础库
1.2什么是numpy
一个python中做科学计算的基础库,重在数值计算,也是大部分python科学计算库的基础库,多用于在大型,多维数组上执行数组运算
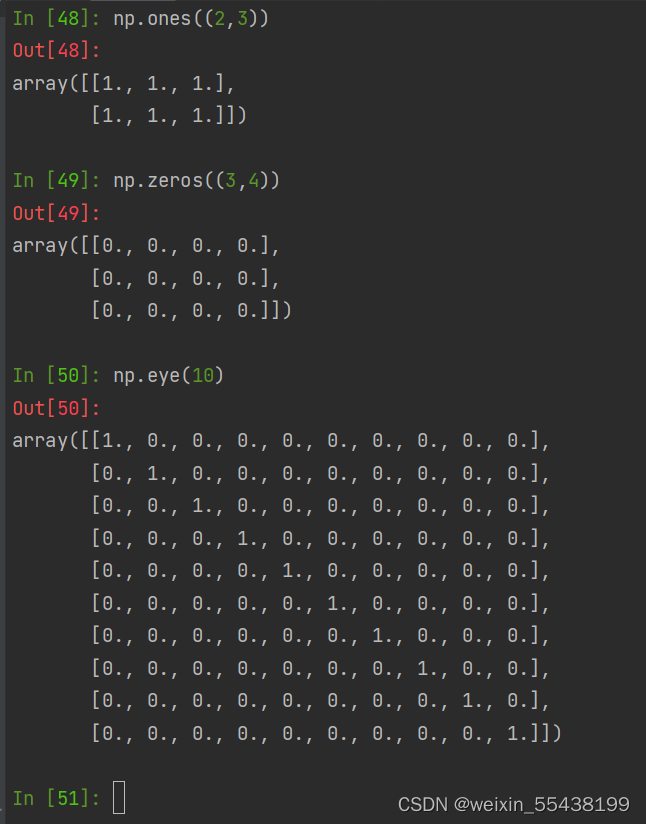
1.3numpy的数组的创建(矩阵)


1.4数据类型的操作



1.4数组的形状
数组的形状

reshape方法有return值,不会对数据本身进行任何修改,所以还是2行6列



当shape的元组为一个值时,这个数组形状为一位的,为二个值时,数组形状为二位的
修改数组形状:reshape

‘三位数’数组见解:以下代码的(2,3,4)可以这样理解:2为一共二大块,三为每块三行,4为每块4列

1.5numpy中常见的更多数据类型

1.6数组的计算
数组和数的计算

数组和数组的计算(数组都是同样的位数)

数组与数组的计算(不同位数但行或者列维度相同)
 行的维度相同所以进行,行计算
行的维度相同所以进行,行计算
 列的维度相同,进行列运算
列的维度相同,进行列运算
数组与数组的计算(行和列都没有相同维度)
 没有相同维度的数组进行计算会报错
没有相同维度的数组进行计算会报错
广播原则:

二:【numpy读取本地数据和索引】
2.1轴
在numpy中可以理解为方向,使用0,1,2...数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2, 3)),有0,1,2轴
有了轴的概念之后,我们计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值
np.arange(0,10).reshape((2,5)),reshpe中2表示0轴长度(包含数据的条数)为2,1轴长度为5,2X5一共10个数据
二维数组的轴

三维数组的轴

2.1numpy读取本地数据
CSV:Comma-Separated Value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
由于csv便于展示,读取和写入,所以很多地方也是用csv的格式存储和传输中小型的数据,为了方便教学,我们会经常操作csv格式的文件,但是操作数据库中的数据也是很容易的实现的
读取方法:
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)

numpy中的转置:(就是行和列的交换)
转置是一种变换,对于numpy中的数组来说,就是在对角线方向交换数据,目的也是为了更方便的去处理数据



2.2numpy中的索引和切片

取行:a[2]
取连续的多行:a[2:]
取不连续的多行a[[2,8,10]]
取列a[:,0] ,前操作行,逗号后操作列
2.3numpy中更多的索引方式
numpy中数值的修改



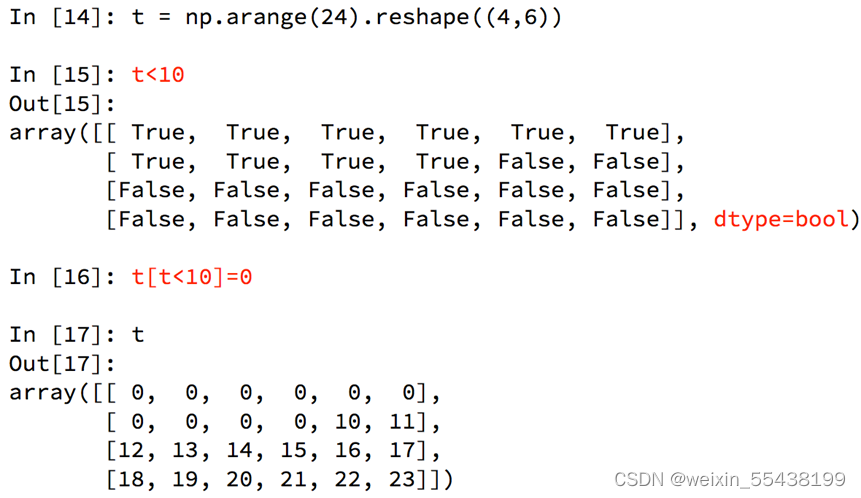
numpy中布尔索引
numpy中三元运算符

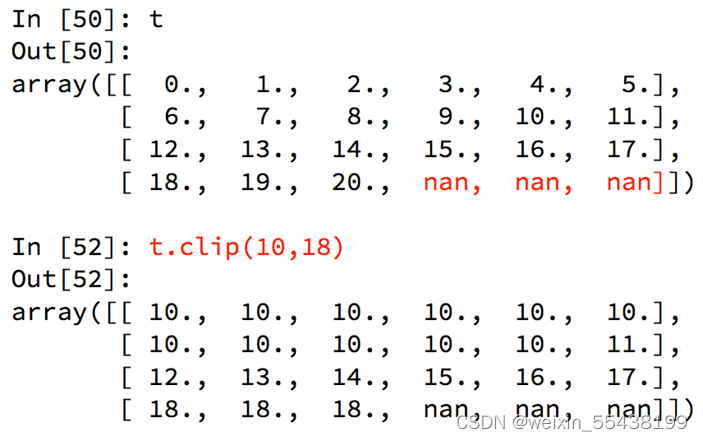
numpy中的clip(裁剪)(小于10的替换成10,大于18的替换成18)
三:【numpy中的nan和常用方法】
3.1数据的拼接

3.2数组的行列交换:

3.2numpy中的随机方法
1.获取最大值最小值的位置
numpy生成随机数

分布的补充
1.均匀分布:在相同的大小范围内的出现概率是等可能的

2.正太分布:呈钟型,两头低,中间高,左右对称

3.3numpy中的nan和常用统计方法
nump中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf)
比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)
numpy中的nan的注意点
1.二个nan是不相等的
2.np.nan!=np.nan
3.nan和任何计算都为nan
numpy中常用统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None)![]()
标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值反映出数据的波动稳定情况,越大表示波动越大,约不稳定