文章目录
- awk的介绍
- awk能够干什么
- awk的格式
- 工作原理:
- 记录和域
- 内建变量的用法
- 1. FS
- 2. OFS
- 3.RS
- 4. ORS
- 5. NF
- 6. NR
- BEGIN 和END语句块
- 常见案例
- 1. 使用NR行号提取ip
- 2. 打印UID小于10的账号名称和UID信息
- 3. 数学运算
- 4. AWK打印硬盘设备名称,默认以空格为分割:
- 5. AWK以空格、冒号、\t(Tab缩进) 、分号为分割显示第4列内容:
- 6. AWK以冒号分割,打印第一列,同时将内容追加到/tmp/awk.log下:
- 7. 打印test.txt文件中的第3行至第5行(2种写法):NR表示打印行,$0表示文本所有域:
- 8. 打印test.txt文件中的第3行至第5行的第一列与最后一列:
- 9. 打印test.txt文件中,长度大于80的行号:
- 10. AWK引用Shell变量,使用-v或者双引号+单引号即可:
- 总结
awk的介绍
shell脚本中最难的不是shell的语法难,而是在shell编程这门语言中,又突然出来一门编程语言,这个编程语言叫: awk
awk以用来处理数据和生成报告(excel);
处理的数据可以是一个或多个文件;可以是直接来自标准输入,也可以通过管道获取标准输入;
awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。
awk能够干什么
学习具体使用前,先来看下 awk 能干些什么事情:
- 能够将给定的文本内容,按照我们期望的格式输出显示,打印成报表。
- 分析处理系统日志,快速地分析挖掘我们关心的数据,并生成统计信息;
- 方便地用来统计数据,比如网站的访问量,访问的 IP 量等;
- 通过各种工具的组合,快速地汇总分析系统的运行信息,让你对系统的运行了如指掌;
- 强大的脚本语言表达能力,支持循环、条件、数组等语法,助你分析更加复杂的数据;
6
awk 不是万能的,它比较擅长处理格式化的文本,比如 日志、csv 格式数据等;
awk的格式
简单结构:
awk [选项] ‘模式 {动作}’ 输入文件
awk [options] ‘pattern{attion}’ file
-
模式即pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如NR==1,这就是模式,可以把它理解为一个条件。
-
动作即action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开。
详细结构
awk ‘BEGIN{ print “start” } pattern{ commands } END{ print “end” }’ filename
一个 awk 脚本通常由 BEGIN 语句 + 模式匹配 + END 语句三部分组成,这三部分都是可选项
工作原理:
简单版:
第一步执行 BEGIN 语句
第二步从文件或标准输入读取一行,然后再执行 pattern 语句,逐行扫描文件到文件全部被读取
第三步执行 END 语句
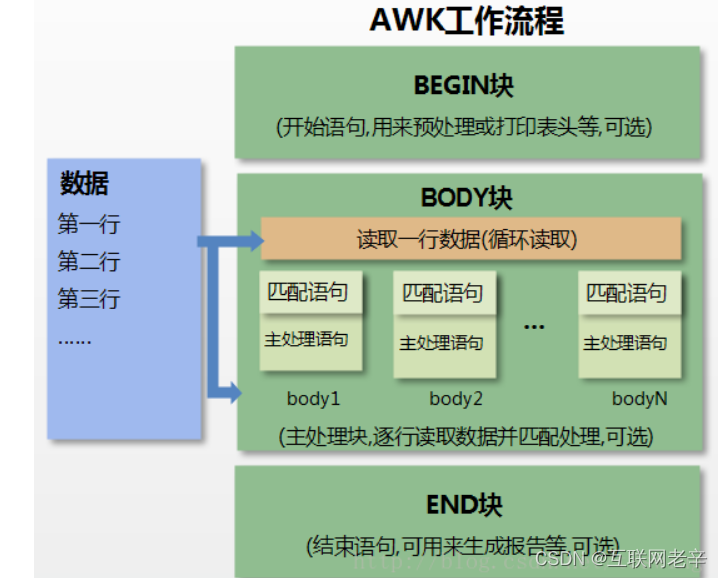
详细执行流程:
- 首先执行关键字 BEGIN 标识的 {} 中的命令;
- 完成 BEGIN 大括号中命令的后,开始执行 body 命令;
- 逐行读取数据,默认读到 \n 分割的内容为一条 记录,其实就是行的概念;
- 将记录按照指定的分隔符划分为 字段,其实就是列的概念;
- 循环执行 body 块中的命令,每读取一行,执行一次 body,最终完成 body 执行;
- 最后,执行 END 命令,通常会在 END 中输出最后的结果;
awk 是输入驱动的,有多少输入行,就会执行多少次 body 命令
我们在学习过程中,要时刻记着:
记录 (Record) 就是行
字段 (Field) 就是列
BEGIN 是预处理阶段
body 是 awk 真正工作的阶段
END 是最后处理阶段。
案例: 输出test.txt中的每一行
[root@itlaoxin41 ~]# awk '{print $0}' test.txt
cccc
old new old now 在这个案例中: awk每次读取一行
具体的执行过程:
- 读取文件第一行 (awk 默认按行读取文件)
- 将所读取的行赋值给 awk 的变量 $0,于是 $0 中保存的就是本次所读取的行数据
- 进入代码块 {print $0} 并执行其中代码 print $0,即输出 $0,也即输出当前所读取的行
- 执行完本次代码之后,进入下一轮 awk 循环:继续读取下一行 (第二行)
…
全部读取完成后,退出awk
记录和域
域标记: awk执行时,其浏览标记为$1,2...2...2...n,这种方法称为域标记
$1 表示参照第一域, 多个域用,分割,比如$1,$3
$0 表示所有域
内置变量:
···
NR:表示当前的行数;
NF:表示当前的列数;
RS:行分隔符,默认是换行;
FS:列分隔符,默认是空格和制表符;
OFS:输出列分隔符,用于打印时分割字段,默认为空格
ORS:输出行分隔符,用于打印时分割记录,默认为换行符
案例:
以冒号为分隔符,打印第三个域
[root@itlaoxin41 ~]# awk -F ":" '{print $3}' /etc/passwd
假设我们想截取多列,比如:
截取用户名,用户ID,家目录和bash
[root@itlaoxin41 ~]# awk -F ":" '{print $1,$3,$6,$7}' /etc/passwd
root 0 /root /bin/bash这里需要知道,awk默认以空格为分隔符
内建变量的用法
1. FS
指定列分隔符
···
[root@itlaoxin41 ~]# echo "111|222|333" |awk '{print $1}'
111|222|333
[root@itlaoxin41 ~]# echo "111|222|333" |awk 'BEGIN{FS="|"}{print $1}'
111
[root@itlaoxin41 ~]# 2. OFS
输出列分隔符,用于打印时分割字段,默认为空格
[root@itlaoxin41 ~]# echo "111 222 333" |awk 'BEGIN{OFS="/"}{print $1,$2}'
111/222
[root@itlaoxin41 ~]# echo "111 222 333" |awk 'BEGIN{OFS="/"}{print $1,$2,$3}'
111/222/333
[root@itlaoxin41 ~]#
3.RS
行分隔符,默认是换行符;
[root@itlaoxin41 ~]# echo "111 |222|333|444" |awk 'BEGIN{RS="|"}{print $0}'
111
222
333
4444. ORS
ORS指定输出行分隔符
[root@itlaoxin41 ~]# echo "111 |222|333|444" |awk 'BEGIN{RS="|"}{print $0}'>test.sh[root@itlaoxin41 ~]# cat test.sh
111
222
333
444[root@itlaoxin41 ~]# awk 'BEGIN{ORS="|";}{print $0}' test.sh
111 |222|333|444||
5. NF
当前的列数
[root@itlaoxin41 ~]# cat test.sh
111
222
333
444[root@itlaoxin41 ~]# awk '{print NF}' test.sh
1
1
1
1
06. NR
当前行的行数
[root@itlaoxin41 ~]# cat test.sh
111
222
333
444[root@itlaoxin41 ~]# awk '{print NR}' test.sh
1
2
3
4
5BEGIN 和END语句块
awk程序由三部分组成,分别为
初始化:处理输入前做的准备,放在BEGIN块中。
数据处理:处理输入数据。
收尾处理:处理输入完成后要进行的处理,放到END块中。
其中,在“数据处理”过程中,指令被写成一系列模式/动作过程,模式是用于测试输入行的规则,以此确定是否将应用于这些输入行。
awk 的所有代码 都是写在语句块中的
root@itlaoxin41 ~]# awk -F ":" '{print $1}' passwd |head -3
root
ceshi
no such person语句块可分为 3 类: BEGIN语句块, END语句块,和main语句块
其中 BEGIN 语句块和 END 语句块都是的格式分别为 BEGIN{…} 和 END{…}
main 语句块是一种统称,它的 pattern 部分没有固定格式,也可以省略,main 代码块是在读取文件的每一行的时候都执行的代码块。
且:
BEGIN代码块:
- 在读取文件之前执行,且执行一次
- 在BEGIN代码块中,无法使用 $0 或者其他变量
main 代码块:
- 读取文件时循环执行,(默认情况) 每读取一行,就执行一次 main 代码块
- main 代码块可有多个
END代码块
- 在读取文件完成之后执行,且执行一次
- 有 END 代码块,必有要读取的数据 (可以是标准输入)
- END 代码块中可以使用 $0 等一些特殊变量,只不过这些特殊变量保存的是最后一轮 awk 循环的数据
常见案例
1. 使用NR行号提取ip
[root@itlaoxin41 ~]# ifconfig |grep inet |awk 'NR==1{print $2}'
192.168.1.412. 打印UID小于10的账号名称和UID信息
[root@itlaoxin41 ~]# awk -F : '$3 < 10{print $1,$3}' /etc/passwd
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 83. 数学运算
加法:awk ‘{a=1; b=2; print a+b}’
减法:awk ‘{a=1; b=2; print a-b}’
乘法:awk ‘{a=1; b=2; print a*b}’
除法:awk ‘{a=1; b=2; print a/b}’
取余:awk ‘{a=1; b=2; print a%b}’4. AWK打印硬盘设备名称,默认以空格为分割:
df -h|awk '{print $1}' $1 第一列
5. AWK以空格、冒号、\t(Tab缩进) 、分号为分割显示第4列内容:
awk -F '[ :\t; ]' '{print $4}' test.txt
6. AWK以冒号分割,打印第一列,同时将内容追加到/tmp/awk.log下:
awk -F: '{print $1 >>"/tmp/awk.log"}' test.txt
7. 打印test.txt文件中的第3行至第5行(2种写法):NR表示打印行,$0表示文本所有域:
awk 'NR==3,NR==5 {print}' test.txt
awk 'NR==3,NR==5 {print $0}' test.txt
8. 打印test.txt文件中的第3行至第5行的第一列与最后一列:
awk 'NR==3,NR==5 {print $1,$NF}' test.txt
备注:默认情况下,awk操作的文本以空格或者缩进格(Tab)为列的分界序列
9. 打印test.txt文件中,长度大于80的行号:
awk 'length($0)>80 {print NR}' test.txt
10. AWK引用Shell变量,使用-v或者双引号+单引号即可:
`awk -v STR=hello '{print STR,$NF}' test.txt` #test.txt每行前加入hello打印
STR="hello";echo|awk '{print "'${STR}'";}' #需要订正!
总结
AWK没有一万字写不完,这刚刚开始就干到了4500字, 足够你学习用了。