| Python常见问题整理 | ||||||||
| 日常使用python时,经常遇到的各种解决不了、头疼的问题,都可以记录到这里,大家群策群力,积极补充~ | ||||||||
| 序号 | 问题标题 | 问题现象 | 原因 | 解决方法 | 参考文章 | 添加人 | 报错截图 | |
| 0 | ModuleNotFoundError | 代码运行报错ModuleNotFoundError | 库没安装 | 见第二个sheet页:ModuleNotFoundError | 见第二个sheet页:ModuleNotFoundError | 马哥 | ||
| 1 | pycharm安装第三方库失败 | 在pycharm中安装第三方库失败 | python默认的安装源地址是国外的,所以偶尔会遇到安装失败的问题。 | 以安装pandas库为例,在命令行(windows系统的cmd,Mac系统的terminal)里执行:(-i选项,代表python安装源地址,这里用到清华大学的安装源) pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple | 马哥python说 的想法: 社群里小伙伴近期频繁遇到的问题:pychar… - 知乎 | 马哥 | ||
| 2 | pycharm已经安装了第三方库,还是提示导入失败 | 比如,在cmd命令行用pip install安装好了第三方库,在pycharm中import这个库的时候,依然显示没安装。 | 电脑上存在多个python运行环境(比如,cmd里是py3.7,pycharm里是py3.9) | 在pycharm中安装第三方库,不要在cmd命令行中安装。或者, 在目标python安装目录的Scripts下面,用pip安装。 | Pycharm安装第三方库的三种方法_nufe_wwt的博客-CSDN博客_pycharm安装第三方库 | 马哥 | ||
| 3 | jupyter notebook里已经安装了第三方库,还是提示导入失败 | jupyter notebook里已经安装了第三方库,还是提示导入失败 | 电脑上存在多个python运行环境(比如,cmd里是py3.7,jupyter notebook里是py3.9) | 在jupyter中安装第三方库,不要在cmd命令行中安装。 比如,在单元格里执行: !pip install pandas | https://www.zhihu.com/question/59392251/answer/560977151https://blog.csdn.net/weixin_43999124/article/details/108623799 | 马哥 | ||
| 4 | 爬虫获取不到数据 | 在用python爬虫向目标地址发送请求时,返回的响应码是非200,比如403、404等,而且获取不到任何页面数据 | 1、被目标服务器检测到爬虫,被反爬了 2、如果响应码是404,找不到页面,很有可能是请求的URL地址不对 | 解决反爬的方法: 1、模拟请求头 2、伪造请求cookie 3、随机等待间隔 4、使用代理IP 5、验证码破解 | 【道高一尺,魔高一丈】Python爬虫之如何应对网站反爬虫策略 - 知乎 | 马哥 | ||
| 5 | if语句判断相等时报语法错误 | if语句判断是否相等时,报语法错误的异常: SyntaxError: invalid syntax | python中,=代表赋值,==代表判断两个变量是否相等。 如果用反了,就会出现上面的报错。 | 用"=="判断变量是否相等,比如: if a == 2: | python中的=与==有什么区别? - 知乎 | 马哥 | ||
| 6 | 用pandas保存csv文件时乱码 | 用pandas库的to_csv函数保存csv文件时,保存进去的内容打开之后显示乱码 | 乱码问题最头疼,编码格式跟操作系统默认环境、pycharm等IDE工具配置都有关系 | to_csv时,加一个参数: encoding='utf_8_sig' 即,用utf_8_sig的编码格式保存文件。 | 【python爬虫案例】用python爬取B站TOP100排行榜数据 - 知乎 | 马哥 | ||
| 7 | 爬虫分析时,捕获不到页面请求 | 开发python爬虫代码时,在浏览器的开发者模式里面,检测不到目标链接的请求 | 未触发页面请求,所以是空白的 | 点击对应的页面元素,触发一次页面请求。 | 【Python科普】讲解python爬虫如何通过分析前端页面,正确捕获页面请求_哔哩哔哩_bilibili | 马哥 | ||
| 8 | 安装第三方库wordcloud库失败 | 安装wordcloud或其他第三方库时,报错:error: Microsoft Visual C++ 14.0 or greater is required | 总体而言,是电脑运行环境中缺少系统文件导致,此问题比较棘手。 | 解决办法: 1、通过whl文件离线安装,参考: https://www.pythonf.cn/read/61234 2、升级电脑上的Visual C++版本,参考: https://www.codeleading.com/article/74141818258/ | https://www.pythonf.cn/read/61234https://www.codeleading.com/article/74141818258/https://www.bilibili.com/video/BV1bt4y1y7sU | 马哥 | ||
| 9.1 | 爬虫爬到的是乱码 | 爬到的内容中,有很多类似:"Title":"\u56fd\u5916\u65b0\u578b\u80ba\u708e\u6700\u65b0\u52a8\u6001 | 结果中包含unicode编码 | 在用python做爬虫的时候经常会与到结果中包含unicode编码,需要将结果转化为中文,处理方式如下: str.encode('utf-8').decode('unicode_escape') | https://www.cnblogs.com/CoolJayson/p/10469306.htmlhttps://blog.csdn.net/q1246192888/article/details/119424408 | 马哥 | ||
| 9.2 | 爬虫爬到的是乱码 | 爬到的内容中,有很多类似:<title>ÕÐƸÍø_È˲ÅÍø_ÕÒ¹¤×÷_ÇóÖ°_ÉÏÇ°³ÌÎÞÓÇ</title> | 结果中编码格式不对 | 最简单的办法: r.encoding = r.apparent_encoding | 如何解决python爬虫乱码问题_giunwr的博客-CSDN博客_爬虫打印乱码 | 马哥 | ||
| 10 | pycharm界面运行后会显示乱码 | | pycharm设置编码格式问题 | 在pycharm里,file–settings–code style–file encodings,设置为"GBK"就可以解决问题 | 解决在pycharm运行代码,调用CMD窗口的命令运行显示乱码问题_python_脚本之家 | |||
| 11 | 爬百度搜索时,爬到的数据量为0 | | 大概率是编码格式不对,导致内容乱码,所以解析不到相应的页面数据 | 如果爬取到的数据是0,说明乱码了(可以把r.text给print一下,执行一看就是乱码)。 0、尝试更换cookie值。 1、试试换成用anaconda里的python执行,就能解决。 2、试试把请求头中的Accept-Encoding里的br去掉。 | https://www.bilibili.com/video/BV1j94y1f7fD/https://www.bilibili.com/video/BV1ob4y1W7qj/ | 马哥 | ||
| 12 | 词云图不是按背景图绘制出来的 | 词云图的结果,还是一个矩形图,不是背景图形状 | 背景图不是纯白色(有时看上去是白色,其实不是,用取色器看一下就知道了) | 先把图片去背景,然后贴到白色画布上,截图,这样出来的背景图才能用于词云 | 无 | 马哥 | ||
| 13 | read_csv失败 | pandas在read_csv时,报错:OSError: Initializing from file failed | 文件路径中包含了中文,由于read_csv函数的默认引擎engine为C,不支持对中文的识别,导致报该错误。在使用notebook打开文件时常见这个问题。 | 更改engine='python'即可执行成功。 df=pd.read_csv('123.csv',engine='python') | python报OSError: Initializing from file failed故障_北.海的博客-CSDN博客 | 马哥 | ||
| 14 | 爬虫代码bs4报错 | Couldn't find a tree builder with the features you requested: lxml | BeautifulSoup的解析方法之一,xml,需要安装好lxml库才行 | 用常规安装库的方法就行: pip install lxml | https://blog.csdn.net/qq_41621362/article/details/93410344https://www.zhihu.com/question/268088532 | 马哥 | ||
| 15.1 | pyecharts图表不显示 | pyecharts开发的可视化图表html文件打开之后是空白,没有任何显示 | 由于PyEcharts在升级到1.x版本后,将原来HTML网页中使用到的很多js文件换为了在线获取的方式 | win10 win11下可按此种方法解决 | 解决离线状态下使用PyEcharts进行数据可视化绘图时,pyecharts-gallery示例库中的所有html网页打不开、不出图的问题_superchao1982的博客-CSDN博客_pyecharts-gallery | 马哥 | ||
| 15.2 | pyecharts大屏不显示个别子图表 | pyecharts大屏不显示个别子图表,比如,开发了5个子图表,只显示出4个,有1个没显示出来 | 有可能是子图表的chart_id重复了 | chart_id是每个子图表的唯一标识id,不能重复,一旦重复,子图表数量就会缺失 | 无 | 马哥 | ||
| 16 | 爬虫请求校验SSL失败 | 爬虫报错:requests.exceptions.SSLError: HTTPSConnectionPool | 发送请求时校验SSL失败 | 1、在 requests.get 请求中加入 verify=False 2、网络问题,把你的vpn关掉,再爬 | https://www.cnblogs.com/mlllily/p/12134621.htmlhttps://blog.csdn.net/qq_31698363/article/details/121324551 | 马哥 | ||
Python常见问题整理
news/2024/12/2 23:40:01/
相关文章

IMX6ULL学习笔记(15)——GPIO输出接口使用【官方SDK方式】
一、GPIO简介 i.MX6ULL 芯片的 GPIO 被分成 5 组,并且每组 GPIO 的数量不尽相同,例如 GPIO1 拥有 32 个引脚, GPIO2 拥有 22 个引脚, 其他 GPIO 分组的数量以及每个 GPIO 的功能请参考 《i.MX 6UltraLite Applications Processor Reference M…
人员工装未穿戴识别检测 opencv
人员工装未穿戴识别检测基于OpenCvyolo计算机视觉深度学习技术对现场画面中人员行为着装穿戴实时监测识别,发现不按要求着装违规行为立即抓拍存档同步后台。OpenCV-Python使用Numpy,这是一个高度优化的数据库操作库,具有MATLAB风格的语法。所…
【C语言进阶】想用好C++?那就一定要掌握动态内存管理
目录
🤩前言🤩:
一、动态内存概述⚔️: 1.什么是动态内存: 2.动态内存分配的意义:
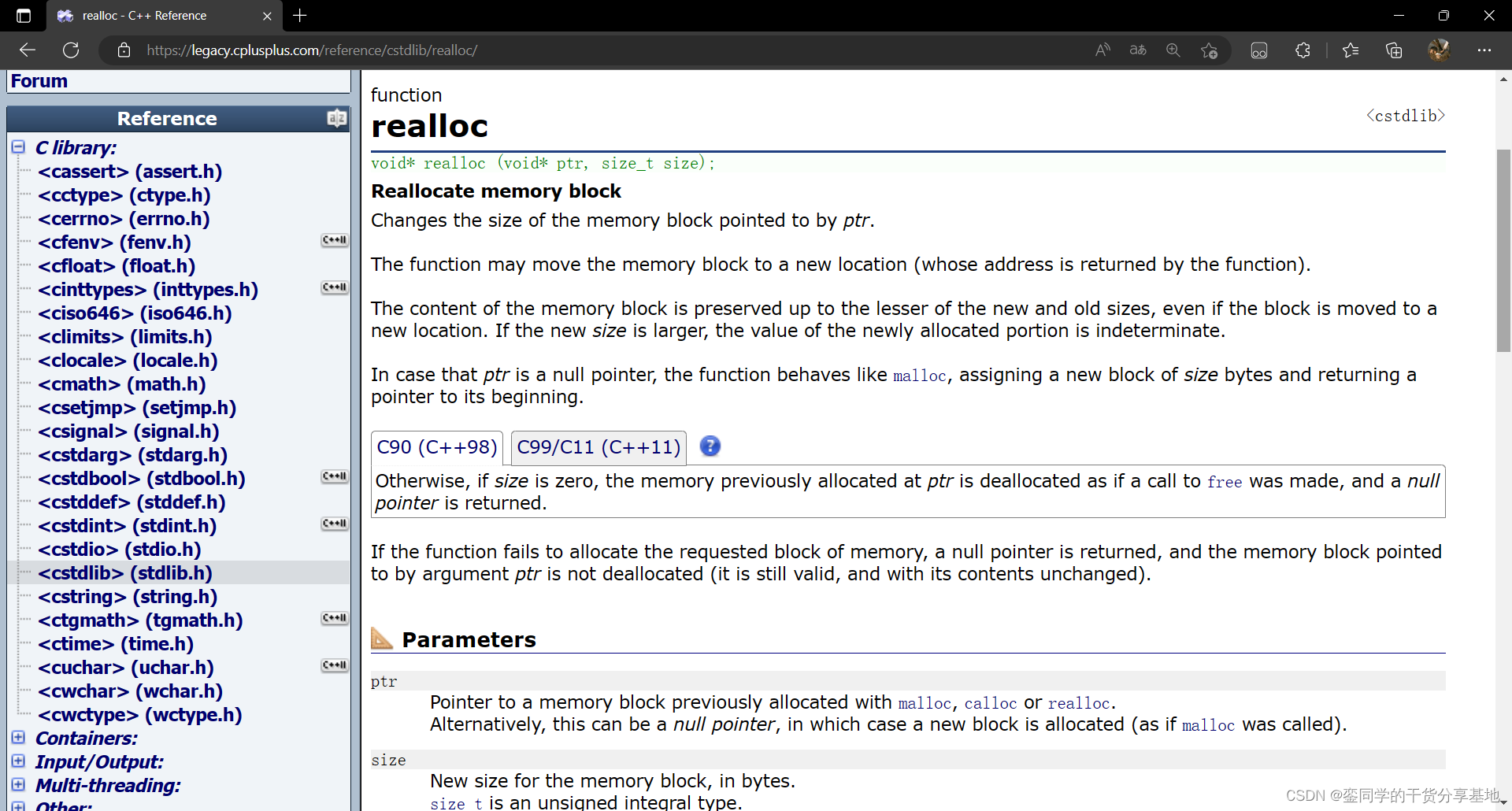
二、常用的动态内存函数🏹: 1. malloc 和 free函数: ①. malloc 函数: …
Windows和Mac系统实现本地部署WebPageTest工具
在项目开发或者测试的过程中,由于没有上线,我们在公网上无法访问我们的网站,但同时我们又需要查看浏览器性能,这样我们就需要在本地部署WebPageTest工具以协助进行性能测试
具体实现步骤:
Windows系统:
…
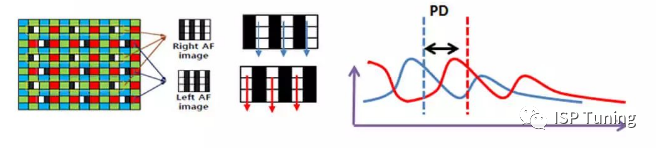
关于 Camera 开始 Tuning 时的一些注意事项
1、问题背景: 最近有调试一个体感游戏机上带 Camera 的项目,原定搭配 ov13855 这颗 sensor, 但由于各种各样的问题,导致做了很多无用功,且各种延期。 本文主要总结下此次项目遇到的问题,及产品开始 tuning 时的一些注意…

Java集合框架【三Map接口、Iterator送代器、Collections工具类】
文章目录双例模式一 Map接口简介1.1 常用方法1.2 演示二 HashMap的存储结构简介三 TreeMap容器类3.1 TreeMap的比较规则3.2 元素自身实现比较规则3.3 通过比较器实现比较规则四 Iterator迭代器4.1 Iterator送代器接口介绍4.2 栗子五 Collections工具类5.1 Collections工具类简介…