- 目录
1.zookeeper基础信息
2.zookeeper部署
1. 单点
2. 分布式
1.解压
2.软连接
3.环境变量
4.删除相关cmd文件
5.添加zookeeper文件夹
5.1添加server
6.同步
7.指定zk机器号
8.启动 【三台机器一起做】
群起脚本 (bigdata13机器)
3.zk
4.节点
5.操作命令
1.登录节点
2.查看节点
3. 查看节点内容
4. 获取当前节点状态 stat
5.创建节点
1.永久节点
2.临时节点:
3.顺序节点
6.修改数据内容 set
7.删除节点
7.监听相关 zk
-
1.zookeeper基础信息
- 官网 https://zookeeper.apache.org
- ·作用: 分布式协调服务
-
2.zookeeper部署
-
1. 单点
-
2. 分布式
- 部署机器个数: 2n + 1 台
- 主从架构
- leader
- follower
-
1.解压
- 上传apache-zookeeper-3.8.0-bin.tar.gz
- 解压
[hadoop@bigdata13 software]$ tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C ~/app/
-
2.软连接
- [hadoop@bigdata13 app]$ ln -s apache-zookeeper-3.8.0-bin/ zookeeper
-
3.环境变量
- [hadoop@bigdata13 app]$ vim ~/.bashrc
#ZK_HOME export ZK_HOME=/home/hadoop/app/zookeeper export PATH=${PATH}:${ZK_HOME}/bin[hadoop@bigdata13 app]$ source ~/.bashrc
- [hadoop@bigdata13 app]$ vim ~/.bashrc
-
4.删除相关cmd文件
- 路径:/home/hadoop/app/zookeeper/bin
[hadoop@bigdata13 bin]$ rm -rf *cmd
- 路径:/home/hadoop/app/zookeeper/bin
-
5.添加zookeeper文件夹
- 路径:/home/hadoop/data
[hadoop@bigdata13 data]$ mkdir zookeeper
- 路径:/home/hadoop/data
-
5.1添加server
- 路径:/home/hadoop/app/zookeeper/conf
[hadoop@bigdata13 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@bigdata13 conf]$ vim zoo.cfg- 修改:dataDir=/home/hadoop/data/zookeeper/
- 添加
server.1=bigdata13:2888:3888 server.2=bigdata14:2888:3888 server.3=bigdata15:2888:3888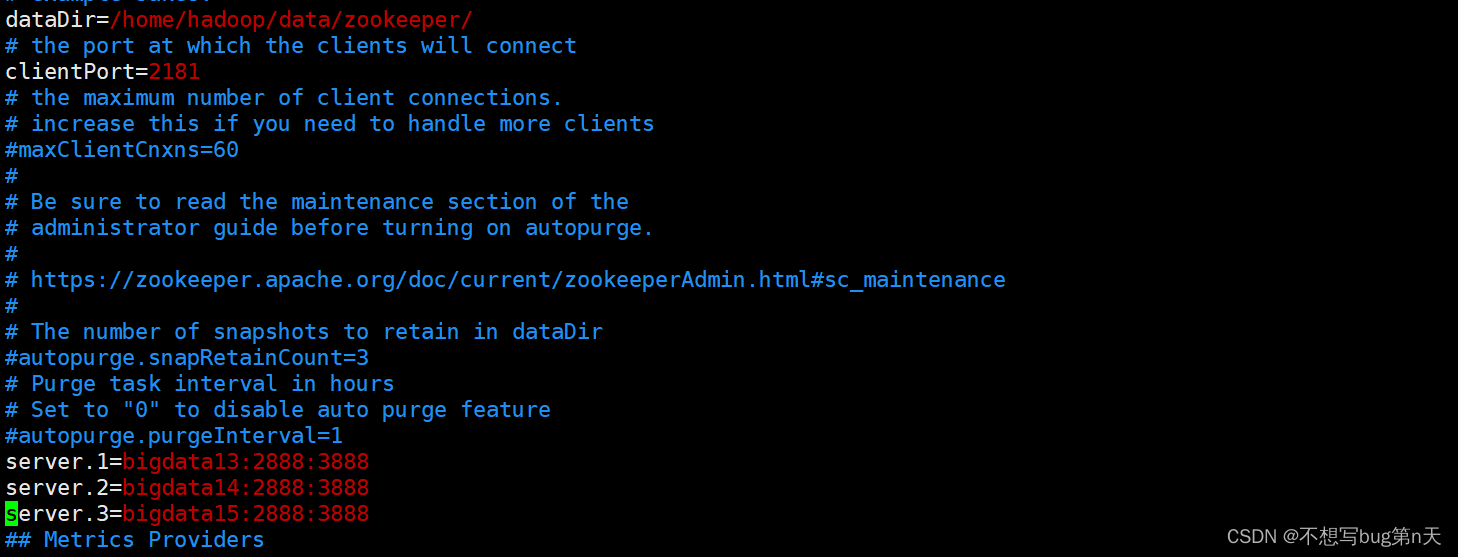
-
6.同步
- [hadoop@bigdata13 app]$ xsync apache-zookeeper-3.8.0-bin/
- [hadoop@bigdata13 app]$ xsync zookeeper
- [hadoop@bigdata13 app]$ xsync ~/.bashrc
-
7.指定zk机器号
- (两个路径都放置myid文件【内容相同 用cp命令】)
路径:/home/hadoop/app/zookeeper
路径:/home/hadoop/data/zookeeper- 在bigdata13机器:[hadoop@bigdata13 zookeeper]$ vim myid
内容为 1 - 在bigdata14机器:[hadoop@bigdata14 zookeeper]$ vim myid
内容为 2 - 在bigdata15机器:[hadoop@bigdata15 zookeeper]$ vim myid
内容为 3
- 在bigdata13机器:[hadoop@bigdata13 zookeeper]$ vim myid
- (两个路径都放置myid文件【内容相同 用cp命令】)
-
8.启动 【三台机器一起做】
- 命令:zkServer.sh start
- 启动后查看jps
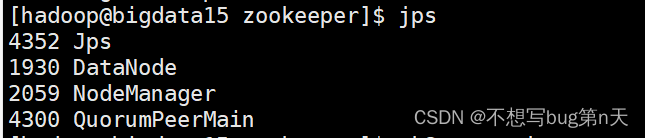
- 启动后查看jps
-
群起脚本 (bigdata13机器)
- [hadoop@bigdata13 shell]$ vim zkServer.sh
case $1 in "start")for host in bigdata13 bigdata14 bigdata15doecho "====${host}==="ssh ${host} "/home/hadoop/app/zookeeper/bin/zkServer.sh start"done;;"stop")for host in bigdata13 bigdata14 bigdata15doecho "====${host}==="ssh ${host} "/home/hadoop/app/zookeeper/bin/zkServer.sh stop"done;;"status")for host in bigdata13 bigdata14 bigdata15doecho "====${host}==="ssh ${host} "/home/hadoop/app/zookeeper/bin/zkServer.sh status"done;;*)echo "Usage:$0 <start|stop|status>";; esac赋予权限:[hadoop@bigdata13 shell]$ chmod u+x zkServer.sh
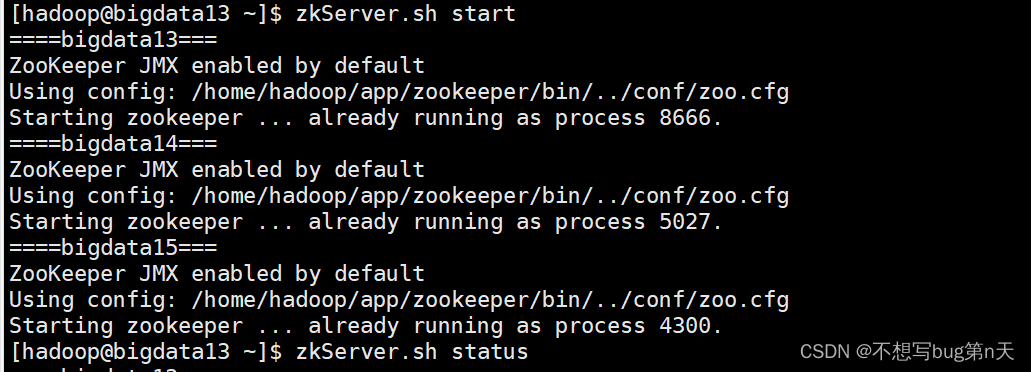
- [hadoop@bigdata13 shell]$ vim zkServer.sh
- 命令:zkServer.sh start
-
-
3.zk
-
1.zk是用来做什么的?
-
1.管理配置信息的 【数据量小】
-
2.watch(监控) 配置信息的变化
-
-
2.zk数据模型(一个 树形/层级式结构 linux差不多)
-
0.根节点 /
-
1.目录就是节点
-
2.节点保存数据的内容
-
3.zk里面所有的目录 都叫做节点 znode
-
-
-
4.节点
-
1.永久节点 (节点创建好之后 可以永久存在 )
可以存放子节点 -
2.临时节点 (节点创建好之后 有效时间过后节点就会消失 )
不能创建子节点 -
3.顺序节点
-
4.特点
-
1.zk 每个节点都有自己id 【不会重复的】
-
2.数据是存放在节点上
-
3.数据 不是很大的数据 仅仅存放比较小的数据
-
4.如果存放的数据发生变更 数据版本号也会发生变化
-
-
-
5.操作命令
-
1.登录节点
-
路径:/home/hadoop/app/zookeeper/bin
[hadoop@bigdata14 bin]$ zkCli.sh
-
-
2.查看节点
-
ls [-s] [-w] [-R] path
[zk: localhost:2181(CONNECTED) 2] ls /
-
-
3. 查看节点内容
-
[zk: localhost:2181(CONNECTED) 1] get /zookeeper
-
-
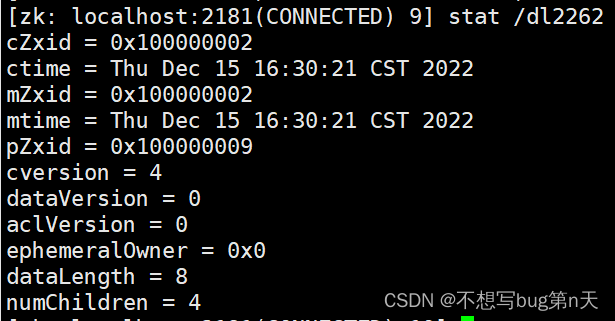
4. 获取当前节点状态 stat
-
[zk: localhost:2181(CONNECTED) 6] stat /dl2262
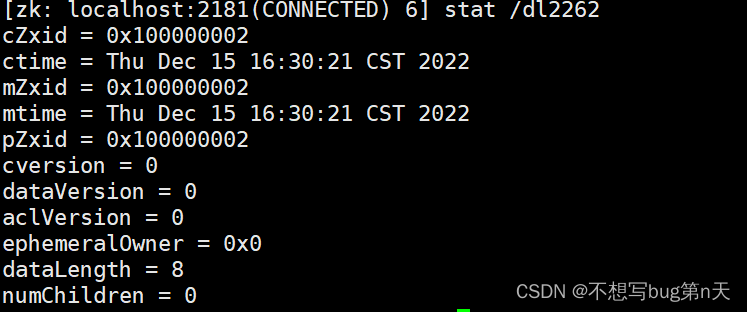
cZxid = 0x100000002 #节点的id ctime = Thu Dec 15 16:30:21 CST 2022 #创建时间 mZxid = 0x100000002 #修改id mtime = Thu Dec 15 16:30:21 CST 2022 #修改时间 pZxid = 0x100000002 #现在id cversion = 0 #版本 dataVersion = 0 #数据版本 aclVersion = 0 ephemeralOwner = 0x0 #是否是临时节点 0x0:永久节点 dataLength = 8 #节点内数据长度 numChildren = 0 #子节点个数
-
-
5.创建节点
-
1.永久节点
-
[zk: localhost:2181(CONNECTED) 3] create /dl2262 luozidai
默认创造永久节点
-
-
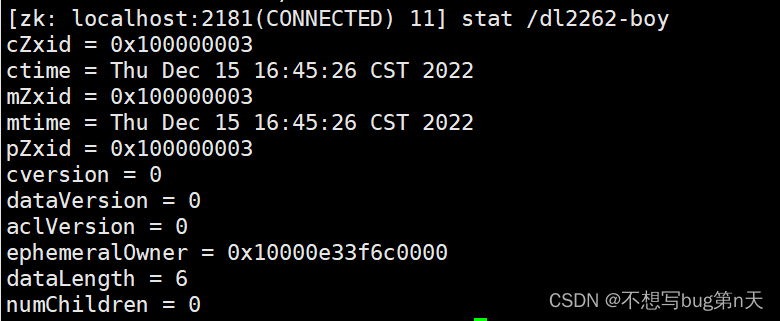
2.临时节点:
-
[zk: localhost:2181(CONNECTED) 7] create -e /dl2262-boy sanpao

-
-
3.顺序节点
-
[zk: localhost:2181(CONNECTED) 2] create -s /dl2262/luozidai
-s 参数默认会给ziyuan节点后面加一个自增的序列号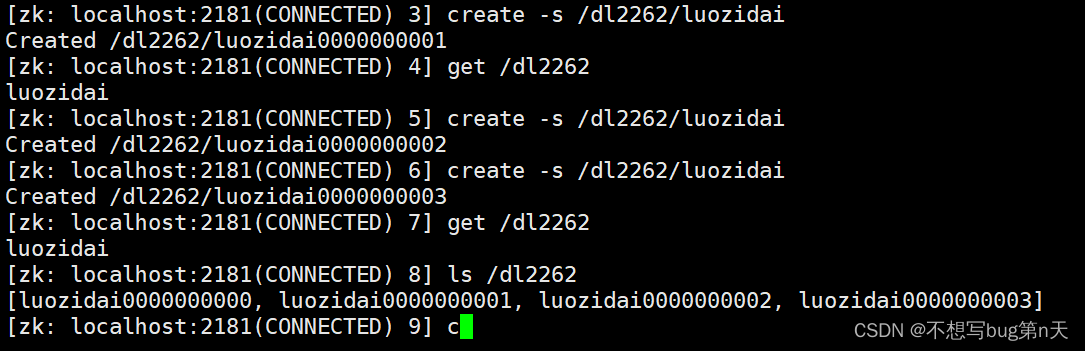
-
-
4.多级创建
-
zookeeper api: 多级
-
curator api: 多 级
-
-
-
6.修改数据内容 set
-
[zk: localhost:2181(CONNECTED) 10] set /dl2262 tiantian

-
加上版本号进行更改:[zk: localhost:2181(CONNECTED) 20] set -v 3 /dl2262 xiaoshuai
-v 后面的数字必须于本次版本号相同
-
-
7.删除节点
-
[zk: localhost:2181(CONNECTED) 28] delete /dl2262/luozidai0000000002

-
-
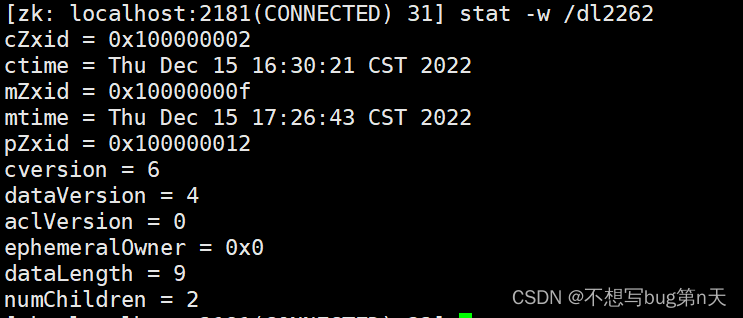
7.监听相关 zk
-
针对每个节点的操作 都有一个 监听器
当你的节点发生变化 就会触发 watch事件 -
[zk: localhost:2181(CONNECTED) 31] stat -w /dl2262
-
[zk: localhost:2181(CONNECTED) 33] get -w /dl2262
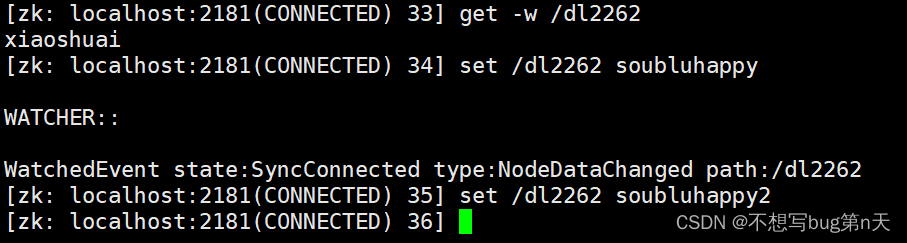
zk shell命令: 监听器只能触发一次
-
补充:zookeeper 对外提供服务的端口 对zk进行监控
-
stat
echo stat | nc bigdata32 2181 -
ruok
echo ruok | nc bigdata32 2181 -
dump
-
conf
-
-
-
zookeeeper
news/2024/10/22 18:44:41/
相关文章

2021 Geek re
2021 Geek re
一年一度的极客大挑战,做完了逆向,题目质量有高有低,一些适合新生,一些又不适合新生,写wp给新生看看,毕竟大家都是这么过来的。
Re0
签到题 ida打开,shift f12查看字符串就行。…

【云原生】aws平台使用eks发布load balancer暴露服务到外网
网络负载均衡: aws官网文档:https://docs.amazonaws.cn/eks/latest/userguide/network-load-balancing.html
在svc上添加注释:
service.beta.kubernetes.io/aws-load-balancer-scheme: "internet-facing"
Android中构建多视图 RecyclerView的正确打开方式
Android中构建多视图 RecyclerView的正确打开方式
简介
漂亮的UI能极大提高用户留存率,相反糟糕的UI将导致App安装率下降。 UI体验对用户留存率有特别大的影响,较差的体验app我可能用不了2s就要卸载掉。 你需要学习内容如下:
使用单个R…

深度强化学习在机器人领域的研究与应用
前言 机器学习方法主要可以分为四类,监督学习、半监督学习、无监督学习、以及强化学习。其中,强化学习不同于连接主义的监督学习方法,是智能体通过与环境的交互,观测交互结果以及获得相应的回报。这种学习的方式是模拟人或动物的一…
机器学习的应用–大数据
说完机器学习的方法,下面要谈一谈机器学习的应用了。无疑,在2010年以前,机器学习的应用在某些特定领域发挥了巨大的作用,如车牌识别,网络攻击防范,手写字符识别等等。但是,从2010年以后…

【一】机器学习在网络空间安全研究中的应用
本文为清华大学计算机系团队于2017年发表于计算机学报的一篇文章,作者为张蕾,崔勇,刘静,江勇和吴建平。
摘要
文章首先阐述机器学习技术在网络空间安全应用研究中的应用流程,然后从系统安全,网络安全和应…
Few-Shot Learning (FSL): 小样本学习简介及其应用
原文链接:Few-Shot Learning (FSL): What it is & its Applications 如果手机需要成千上万张照片来训练才能进行人脸识别解锁,这是很不友好的。在机器学习应用领域,小样本学习(Few-shot Learning)(在刚刚描述的情况下称为单样…